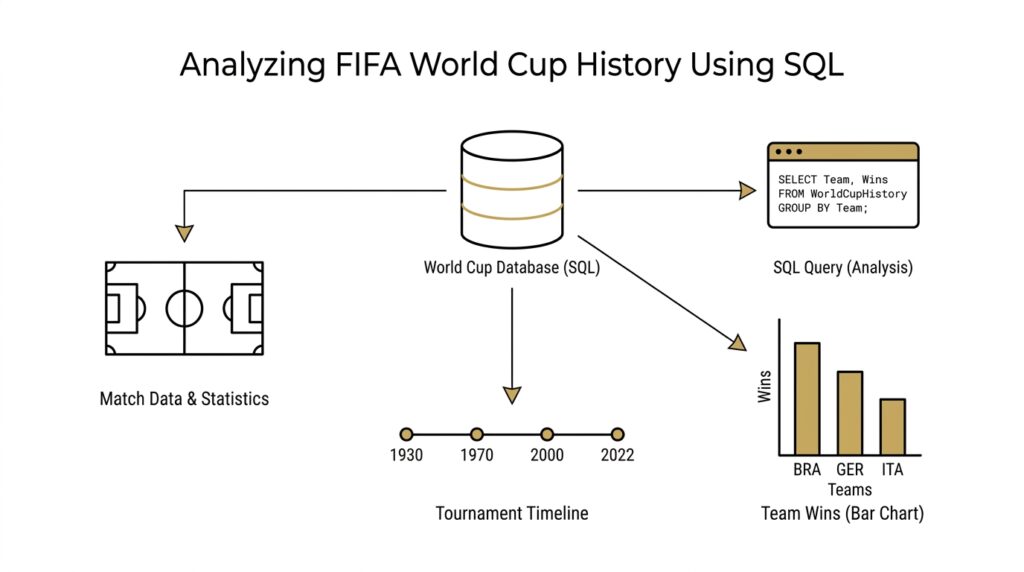
Set Up the Dataset
Before we can ask SQL to tell the story of the FIFA World Cup, we need to give it a clean place to look. That means building a dataset, which is the organized collection of records our queries will read like pages in a notebook. When you are working through FIFA World Cup history using SQL, the setup matters as much as the analysis, because messy source data can turn a promising question into a confusing answer. What should one match look like? What should one team look like? Those choices are the foundation of everything that follows.
The safest way to begin is to choose a single source of truth and keep the structure consistent from the start. In practice, that usually means starting with a CSV, or comma-separated values file, which is a plain-text file that stores information in rows and columns. Each row should represent one real-world event, such as a match, and each column should represent one detail about that event, such as the year, host country, winner, score, or stage. If we keep asking FIFA World Cup history using SQL questions later, this tidy structure will let the database answer without guessing what we meant.
Now we can picture the dataset like a small library with carefully labeled shelves. A match table might hold the core facts, while a teams table might store stable information about national teams, and a tournaments table might group the World Cup editions by year and location. A table is just a structured grid inside a database, and a row is one record inside that grid. This separation helps us avoid repeating the same team name or tournament details over and over, which keeps the data easier to update and easier to trust.
As we prepare the files, we also want to make the names and values predictable. Column names should be clear and consistent, such as match_id, year, home_team, away_team, and goals_home, because SQL works best when it can read labels without ambiguity. A primary key, which is a column that uniquely identifies each row, is especially useful here because it prevents two records from pretending to be the same match. If you have ever looked at a spreadsheet where the same team appears spelled three different ways, you already know why this matters.
Cleaning is where the dataset starts to feel trustworthy. We want to remove duplicate rows, fix inconsistent country names, and make sure numbers are stored as numbers rather than as text. Dates should follow one format, scores should not be mixed with notes, and empty values should be handled on purpose instead of ignored. This step may feel careful and slow, but it saves us from broken joins later, where SQL tries to connect tables and finds mismatched labels instead of matching records.
If you are wondering, “How do I set up a FIFA World Cup dataset for SQL analysis without making it messy?” the answer is to design for the questions you expect to ask. If you want to study champions over time, keep a tournament-level table. If you want to compare match outcomes, keep one row per match. If you want to track team performance, make sure team names and team codes are standardized across every table. That way, when we begin querying FIFA World Cup history using SQL, the database can trace the same team or tournament through every record without confusion.
Once the data is cleaned, import it into your SQL database and check it like a careful traveler checking luggage before a long trip. Open a few rows, confirm that the columns loaded correctly, and make sure the counts look right for each table. This is the moment where we verify that the dataset in SQL matches the source files we prepared outside it. A solid setup does not feel flashy, but it gives us something far more valuable: a reliable base for exploring patterns, comparing eras, and uncovering the story hidden inside World Cup history.
Inspect Tables and Relationships
In FIFA World Cup history using SQL, the first real checkpoint after import is to see how the tables talk to each other. We have already put the data in place; now we want to understand the shape of the room before we start asking big questions. If you are wondering, “How do I inspect tables and relationships in SQL without getting lost?” the answer begins with looking for the clues that show which table holds the main story and which tables add supporting details.
A table is a structured grid of rows and columns, but not every table plays the same role. One table may hold matches, another may hold teams, and a third may hold tournament editions. When we inspect table relationships, we are looking for how those pieces connect, almost like matching names on luggage tags. The goal is to find the common fields that let SQL follow the same event or team across different tables without guessing.
The easiest place to start is with the primary key, which is the column that uniquely identifies each row. In a match table, that might be match_id; in a teams table, it might be team_id. A foreign key is the matching column in another table that points back to that unique record, and that link gives the database a reliable path between tables. Once we can spot those fields, FIFA World Cup history using SQL becomes much easier to map, because we know which records belong together.
This is where the relationships start to feel less abstract and more like a story. A single tournament can include many matches, so a tournaments table often connects to a matches table in a one-to-many relationship, meaning one record in the first table relates to many records in the second. The same pattern often appears between teams and matches, because one team can appear in many games. When we inspect those links carefully, we stop treating the database like separate lists and start seeing it as one connected system.
At this stage, SQL gives us a few simple ways to look around. We can list tables in the database, check column names, and preview rows to confirm that the identifiers line up. We can also read the schema, which is the blueprint of the database structure, to see which columns are keys and which ones are meant to connect. These checks may feel small, but they save us from a common headache later: a JOIN, which is a query that combines rows from two tables, only works cleanly when the shared fields actually match.
Good inspection also means noticing what should not be repeated. If team names appear in every match row, that can work for quick analysis, but it becomes fragile when spelling changes or abbreviations drift. A separate teams table gives us one consistent record for each team, while the match table stores the event itself. In FIFA World Cup history using SQL, that separation helps us ask sharper questions later, because we can compare teams, tournaments, and match outcomes without duplicating the same facts over and over.
The real payoff comes when we trace a single path through the database and watch the structure make sense. A match can point to a tournament, a tournament can group many matches, and teams can appear through those match records as participants. Once you can read those relationships, the database stops feeling like a pile of tables and starts feeling like a map. That map is what will let us move from checking the data to actually exploring patterns in World Cup history.
Clean Match and Team Data
Now that the tables are loaded, the real work begins: we need to make the match and team data trustworthy before we ask it anything interesting. This part of FIFA World Cup history using SQL feels a little like sorting a box of old photographs before building a family tree. If one label is off, one score is written as text, or one team appears under two names, the story can bend in ways we do not want. The good news is that clean match data and clean team data give us a stable base, so every query later can follow the evidence with confidence.
The match table is usually where we start, because it carries the action. Each row should describe one game and one game only, which means we want to remove duplicates, fix row-by-row errors, and make sure fields like year, stage, and score use the right data types. A score should behave like a number, not a sentence, so SQL can compare it, sum it, and sort it without confusion. If we are asking, “How do I clean match data for FIFA World Cup history using SQL?” the answer begins with making sure every row means exactly one match and every column stores one clear piece of information.
From there, we turn to the team data, where consistency matters just as much as accuracy. Team names often drift over time because of abbreviations, spelling differences, or historical changes, so one team may appear in more than one form unless we standardize it. This is where a team code or a fixed team identifier becomes useful, because it acts like a name tag that does not change when the spelling does. In a FIFA World Cup SQL dataset, that shared identifier helps us compare teams across decades without accidentally treating the same team as two different ones.
Cleaning team data also means deciding how to handle history with care. Some national teams have changed names, borders, or official abbreviations across tournament eras, and those changes can look like errors if we do not expect them. Instead of forcing every record into one modern label, we should preserve the historical reality while still keeping the identifiers consistent. That way, our FIFA World Cup history using SQL stays honest about the past while still being easy to query today.
Next, we need to make the match table and team table speak the same language. This is where foreign keys, which are matching fields that point from one table to a unique row in another table, matter again because they keep links reliable. If a match record says a team won but the team name is written differently in another table, the connection can fail quietly and distort the result. Cleaning match and team data together gives us a shared vocabulary, and that shared vocabulary is what makes later joins feel smooth instead of fragile.
We should also treat missing values with intention rather than surprise. An empty score, an unknown venue, or a blank team field may mean the source data is incomplete, or it may mean the record was entered in a different format that we need to normalize. The safest move is to inspect those gaps, decide whether they should become NULL values, which are placeholders for unknown or missing data, and document the rule we used. That small act of discipline keeps the dataset readable and helps every later query tell the truth instead of guessing.
Once the cleaning is done, we test the result the way we would test a bridge before crossing it. We count rows, compare team totals, sample a few matches, and confirm that names, scores, and dates line up across tables. This is where the cleaned data starts to feel solid, because we can trust it to support deeper analysis without wobbling under the weight of a bad label or a mismatched record. With match and team data cleaned and aligned, FIFA World Cup history using SQL is ready for the kind of questions that reveal patterns instead of hiding them.
Query Winners and Goal Leaders
Once the tables are clean and the joins line up, we can finally ask the fun questions: who won each tournament, and who put the most goals on the board? In FIFA World Cup history using SQL, these are the moments when the database stops feeling like a filing cabinet and starts feeling like a storyteller. The trick is to treat winners as tournament-level facts and goal leaders as aggregated scoring facts, because those two answers live at different scales. When we separate them clearly, the queries become much easier to reason about.
For winners, the simplest path is usually the tournament table, because one row there should represent one World Cup edition. If that table includes fields like year, winner, and maybe runner_up, we can read the history almost like a scoreboard timeline. A query such as this gives us a clean list of champions without any extra math:
SELECT year, winner
FROM tournaments
ORDER BY year;
That ORDER BY clause matters because it arranges the story in time, which helps you see how FIFA World Cup history using SQL can trace champions across decades. If you want only the most recent winner, you can sort descending and ask for the first row, but the full list is often more useful when we are learning how the pattern changes over time.
Goal leaders need a different kind of thinking because their story is scattered across many rows. A single player does not usually appear once; they appear every time they score, so we need aggregation, which means combining many rows into one summary. The most important tool here is GROUP BY, which tells SQL to gather rows by player before counting or adding their goals. If you have a scorer-level table, a query like this can reveal the top finishers:
SELECT player_name, SUM(goals) AS total_goals
FROM goal_events
GROUP BY player_name
ORDER BY total_goals DESC;
Here, SUM(goals) adds up each player’s scoring rows, while ORDER BY total_goals DESC places the biggest totals at the top. If you want the top 10, you can add LIMIT 10, which trims the result to the leaders we care about first. This is the moment where FIFA World Cup history using SQL starts to feel like ranking the best pages in a notebook by how much action they contain.
What if your data does not include a player-level scoring table? That is a common and very workable problem. In that case, we can still query team goal totals from match scores, or we can build a scoring table later from match reports and then revisit the same pattern. The important idea is that goal leaders always come from repeated events, while winners come from one record per tournament, so the query shape should match the kind of question we are asking.
There is one more detail worth watching closely: ties. Two players can finish with the same goal total, and two tournaments can sit side by side in the dataset without confusion, but only if the values are clean and consistent. If you want to handle tied scorers more gracefully, window functions like RANK() or DENSE_RANK() can assign shared positions instead of forcing an artificial order. That gives us a more honest view of the data, which is exactly what we want when we are using FIFA World Cup history using SQL to compare champions, scorers, and the shape of success across eras.
Analyze Trends Across Eras
Now that the winners and goal leaders are clear, we can step back and ask the bigger question: what changes when we look at FIFA World Cup history using SQL as a timeline instead of a single event list? This is where the data starts to tell us about eras, or stretches of time that share a similar style of play, scoring pattern, or competitive balance. To analyze trends across eras, we group matches, tournaments, and teams into time windows and then compare how those windows differ. The picture becomes richer because we are no longer asking who won one year; we are asking how the game itself evolved.
The first move is to define the era we want to study. An era is a custom time slice, like decades or pre- and post-World Cup rule changes, and SQL can build it with a CASE statement, which is a rule that turns one value into another based on conditions. For example, we might group 1930–1950 as an early era, 1954–1982 as a middle era, and 1986 onward as a modern era. That kind of grouping lets us compare FIFA World Cup history using SQL without getting lost in year-by-year noise.
Once the eras are in place, we can look for patterns that show how the tournament changed. Did average goals per match rise or fall? Did certain continents dominate more strongly in one period than another? Did finals become tighter, with fewer goals and more defensive play? A query that uses AVG() for average, COUNT() for totals, and GROUP BY for grouping can answer those questions in a way that feels almost like reading the pulse of the tournament.
SELECT
era,
COUNT(*) AS matches,
AVG(total_goals) AS avg_goals
FROM world_cup_matches
GROUP BY era
ORDER BY era;
That small pattern gives us a surprisingly clear lens. If the average goals climb in one era and settle in another, we can begin to connect the numbers to the football style of that time, such as more open attacking play or more cautious defensive systems. If you have ever wondered, “How do I compare World Cup eras in SQL without making the analysis too complicated?” this kind of query is the answer. It keeps the comparison simple while still showing meaningful change.
We can also compare teams within each era instead of across the full history at once. That matters because a team’s success often looks different depending on the time period we choose. A PARTITION BY clause, which tells SQL to treat each era as its own mini-group, helps us rank teams or scorers inside each period rather than across the whole tournament archive. In FIFA World Cup history using SQL, that gives us a fairer comparison because a team’s performance should be measured against the competition it actually faced.
Era analysis also helps us see shifts in geography and opportunity. Early tournaments were shaped by travel limits and fewer entrants, while later editions brought more teams and broader global participation. When we count appearances, wins, or knockout-stage finishes by era, we can see whether dominance stayed concentrated or spread out over time. That kind of trend line turns raw match records into a story about access, growth, and changing competition.
The final step is to pair the numbers with a question we can keep following. If an era has more goals, was that because defenses weakened, attacks improved, or the tournament format changed? If one region wins more often in a given period, was it due to talent, scheduling, or simply a smaller field of rivals? SQL cannot answer every why on its own, but it can show us where to look next, and that is what makes FIFA World Cup history using SQL so rewarding. Once we can compare eras clearly, we are ready to move from broad patterns into the specific records and seasons that shaped them.