Threat Model and Project Goals
Imagine you’re watching a breaking clip flood your feed and you wonder if what you’re seeing is real — this is where deepfake detection, real-time inference, and machine learning meet a very human problem: stopping fake videos from going viral. In this section we build on the foundation of why detection matters and shape a clear plan: who we’re protecting, who might attack, and what measurable goals will show the project is working. Think of this as drawing a map before we start the journey — we need to know the terrain, the risks, and the finish line.
First, let’s set the stage by defining a threat model in plain language: a threat model is a description of the people or groups who might try to fool the system (the adversaries), what they want to accomplish, and what resources or techniques they can use. An adversary could be a prankster with basic editing tools, an organized actor using sophisticated generative models, or a platform-scale spammer trying to amplify misinformation. We describe these attackers so we can design defenses that match the level of risk rather than guessing at threats.
Next, we identify the high-value assets we’re protecting: user trust, platform reputation, and the system’s own decision-making. Protecting these assets means catching fake videos quickly enough to prevent widespread sharing while avoiding unnecessary takedowns that harm legitimate creators. Here we introduce important terms: a false positive is when the system flags a real video as fake, and a false negative is when a fake video slips through. Both are costly in different ways, so our goals must explicitly balance them.
Now let us talk about realistic attack scenarios and how they shape our technical choices. One scenario is a fast-moving news event where an adversary seeds a convincing deepfake of a public figure; our system must detect it with low latency (the delay between input and decision) and high throughput (how many videos we can process per second). Another scenario involves adversaries deliberately altering videos to evade detectors — this requires robustness to novel manipulations and continual model updates. These stories tell us which defenses matter: speed, scalability, and adaptive learning.
So what do we actually want to achieve? Our project goals should be concrete and testable: reach X% detection accuracy on benchmark deepfake datasets, maintain median latency under Y seconds for real-time streams, keep false positive rate below Z% for high-impact content, and support horizontal scaling to handle traffic spikes. We’ll define interpretability goals too — produce explainable signals (for example, highlighted frames or confidence breakdowns) so human moderators can make fast, informed calls. These measurable objectives make trade-offs explicit and let us prioritize engineering effort.
We also need to acknowledge constraints and trade-offs. Real-time detection on-device reduces privacy risk and bandwidth but limits model size and complexity; cloud-based inference allows heavy models but introduces latency and cost. Privacy regulations and user consent shape what raw video we can store and analyze, and computational budgets force decisions about model compression or lightweight feature extraction. How do you balance accuracy and speed? The answer depends on the scenario — for breaking-news pipelines we favour lower latency with human verification, while for archival scans we prioritise deeper, slower analysis.
Finally, let’s translate goals into an initial roadmap. Start with a minimal viable pipeline that ingests live streams, extracts lightweight audio-visual fingerprints, runs a fast classifier for real-time triage, and routes suspicious items to a stronger offline model plus human review. Measure success against the accuracy, latency, and false positive targets we set earlier, and plan for continual retraining as adversaries evolve. With the threat landscape mapped and goals nailed down, we’re ready to choose model architectures and design the data pipeline that will bring this plan to life.
Datasets and Benchmarks to Use
Building on this foundation, imagine you’re choosing the raw materials for a detection pipeline: the quality of your deepfake detection models will only be as good as the datasets and benchmarks you train and test them on. Right away, prioritize a mix of scale, realism, and measured challenge — the right datasets help us test not only accuracy but robustness, cross-dataset generalization, and the real-time latency targets we set earlier. How do you pick that mix for a system meant to triage live video and then route suspicious clips for deeper analysis? Let’s walk through the practical choices together.
First, consider large curated challenge datasets when you need scale. These provide the variety and volume needed to avoid overfitting to a narrow set of manipulation styles and help train models that can spot broad patterns in manipulated pixels and audio. The Deepfake Detection Challenge (DFDC) dataset is an example of a large-scale, curated set created specifically to accelerate automated detection research and to provide a meaningful public benchmark for model comparison. (arxiv.org)
Next, add datasets that expose models to a variety of manipulation techniques and compression artefacts. FaceForensics++ is important here: it was built to study multiple manipulation methods and to measure detector performance under realistic post-processing (compression, re-encoding) that you’ll see on social platforms. Using a dataset like this helps you evaluate whether a model is learning brittle cues tied to one generation method or robust signals that transfer across methods. (arxiv.org)
Realism matters for the kinds of attacks that make content go viral. Some benchmarks were created precisely because earlier datasets were too easy: Celeb-DF improves visual quality and diversity so detectors are tested against higher-fidelity forgeries that look closer to real footage. When you need to stress-test a model’s generalization — especially for public-figure or news-event scenarios in our threat model — including a realism-focused dataset like Celeb-DF is essential. (openaccess.thecvf.com)
For robustness at scale, look to datasets built from large, messy, real-world collections. DeeperForensics-1.0 is an example of a dataset created to reflect real-world noise and contains tens of thousands of videos (on the order of 60,000 videos) so you can evaluate performance not just on clean lab clips but on the kinds of degraded, varied content your pipeline will actually see. Including such a dataset helps measure how detection accuracy degrades under stress and which pre-processing choices preserve signals for real-time inference. (arxiv.org)
Benchmarks matter as much as datasets. When you test models, run cross-dataset evaluations (train on one corpus, test on another) to estimate generalization, and report both frame-level and video-level metrics plus latency and false positive rates aligned with your goals. If you want a curated list of available public collections and their trade-offs while designing evaluation protocols, look to centralized resources and community benchmark pages that summarize datasets and tasks for standardized comparison. (mfc.nist.gov)
Practically, assemble a training and evaluation plan that mirrors the pipeline you sketched earlier: a large-scale set for broad feature learning, a realism-heavy set to push fidelity, and a robustness set for noisy, real-world conditions. Reserve a held-out cross-dataset split for stress tests, measure end-to-end latency alongside detection accuracy, and plan to augment with adversarial or synthetic variants to simulate evasion attempts. This strategy keeps your real-time deepfake detection system honest — it forces trade-offs to show up as measurable numbers, not wishful thinking.
With these datasets and benchmark habits in place, you’ll have a concrete, testable suite that maps directly to the goals and threat model we defined previously. That setup makes it easier to interpret failures, prioritize retraining, and decide when to route an item for human review versus automated mitigation — the next piece of the pipeline we’ll build on.
Video Preprocessing and Frame Extraction
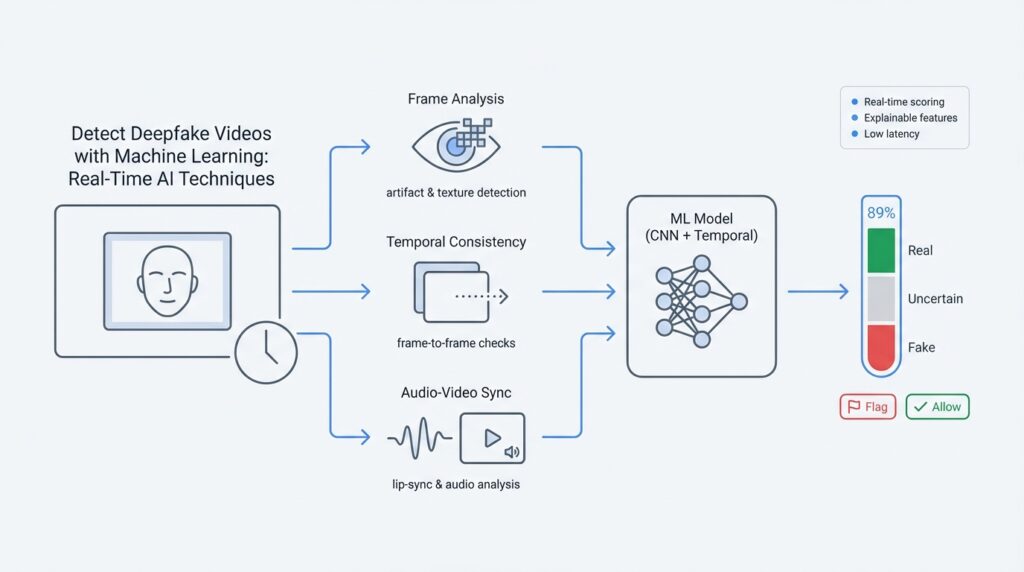
Imagine you just spotted a clip racing across your feed and your stomach tightens because you don’t know whether it’s real — we need to turn that gut feeling into something testable. For robust deepfake detection we begin with careful video preprocessing and frame extraction, which means preparing raw video so models can find the signals that separate honest footage from manipulated content. A frame is a single still image inside a video (think of a flipbook page), and frame extraction is the process of pulling those images out of the encoded video so we can analyze them. Starting here saves time later and sets the stage for reliable, real-time inference without drowning models in irrelevant data.
Our first job is standardization: make incoming clips comparable so a model trained on one dataset can reason about another. Preprocessing — the set of steps we apply to raw frames — includes decoding the compressed video, converting color formats, resizing to a consistent resolution, and normalizing pixel values so brightness and contrast don’t confuse the detector. These steps reduce noise from different cameras and platform re-encodings, and they directly affect latency (the time between seeing a clip and producing a decision), which matters when we’re triaging breaking content. We’ll balance fidelity and speed differently depending on whether we’re doing on-device checks or cloud-based, heavier analysis.
Now let’s talk about pulling frames out in a way that respects both speed and signal. Decoding means turning a codec-encoded stream back into raw frames; a codec is the software that compresses video to save bandwidth. Tools like FFmpeg (an open-source multimedia toolkit) are the practical workhorses for decoding and extracting frames quickly. How do you choose the right frame rate for analysis? It depends on the content: high-motion clips (sports, rapid gestures) need higher sampling (for example 15–30 frames per second) to capture temporal cues, while long conversational videos can be subsampled to 1–5 fps for triage. Choosing every Nth frame, sampling uniformly, or selecting keyframes each have trade-offs: denser sampling preserves temporal artifacts that some deepfakes hide, while sparse sampling reduces cost and speeds up real-time inference.
Once frames are extracted, we often focus on faces because many deepfakes manipulate facial regions. Face detection finds bounding boxes around faces, and landmark detection locates points like eyes and mouth so we can align and crop consistently; alignment means rotating and scaling faces so eyes and mouth line up across frames. After cropping, we resize to a model-friendly shape (common sizes are 224×224 pixels for many convolutional neural networks) and apply normalization — scaling pixel values so their mean and variance match the model’s training data. Doing this reduces spurious differences from cameras or lighting and helps the detector learn real manipulation signals instead of artefacts of resolution.
Temporal cues are characters in this story too: some manipulations reveal themselves only across frames. Optical flow, which measures how pixels move between frames, is a lightweight representation of motion and can reveal unnatural motion patterns introduced by synthesis. We call per-image signals frame-level features (things the model can compute from one frame), and we call sequences of those features video-level features (the story told across frames). Sliding windows of consecutive frames let us feed short temporal contexts into models so they can spot flicker, mismatched blinks, or temporal inconsistencies. Don’t forget audio: aligning audio and visual streams can expose desynchronization or voice anomalies, which strengthens detection when combined with frame-level cues.
Real-world video arrives heavily compressed and re-encoded by social platforms, which creates artifacts that both hide and mimic manipulations. Compression artifacts, motion blur, and color shifts are common, so it’s useful to augment training with simulated re-encoding and to preserve multiple representations (raw RGB frames plus frequency-domain transforms or face embeddings) for robustness. For real-time pipelines we usually run a lightweight stage first — fast face cropping, a compact CNN or feature extractor, and a confidence score — then route suspicious clips to a slower, more powerful offline model for deeper forensics. This two-stage approach balances the need to stop viral content quickly with the need to keep false positives low.
Building reliable detectors begins here: extract representative frames, align and normalize faces, capture short-term motion, and simulate the kinds of compression you’ll see in the wild so models learn robust signals. With these preprocessing choices in place, we’re ready to feed consistent, high-quality inputs to the architectures and training strategies that follow — the next part of our journey will show how to turn those inputs into explainable model decisions and measurable detection performance.
Feature Engineering and Model Selection
Imagine you’ve just pulled a clip out of a trending thread and you want to know—fast—if it’s manufactured or real. Right away we should anchor two phrases: deepfake detection (spotting synthetic or manipulated video) and real-time inference (making that decision quickly enough to act while a clip spreads). A feature is a measurable signal we extract from video or audio (for example, a face texture pattern); a model is the algorithm that learns patterns in those signals to predict whether a clip is fake. How do you decide which signals to trust and which model family to run under time pressure?
Start by treating potential signals like detectives at a scene: each one brings different evidence. Pixel-level cues are direct image patterns; frequency-domain transforms reveal subtle color or compression inconsistencies; optical flow measures motion between frames and can catch unnatural head or eye movement; audio-visual alignment checks whether speech and lip motion match; embeddings are compact numeric summaries produced by pretrained face or speech networks that capture identity or voice characteristics. Define each tool when it appears: an embedding is a fixed-length vector that summarizes high-dimensional content so a downstream classifier can reason about it quickly.
Next we must balance signal richness against latency. For real-time inference you cannot afford every expensive feature on every clip, so prioritize lightweight, high-signal descriptors for triage and reserve heavy features for follow-up. For example, compute a compact face embedding plus a small optical-flow descriptor on-device or at the edge to produce an initial confidence score; only route medium-to-high suspicion items to cloud-based pipelines that compute frequency-domain analysis or full-frame consistency checks. This two-stage design keeps throughput high while preserving the ability to do deep forensics when the stakes are high.
Choosing which model family to use is the next character in our story. Convolutional neural networks (CNNs) are strong at spatial cues like texture; 3D CNNs and temporal convolutions add short-range motion understanding; recurrent networks (RNNs) and Transformers excel at longer temporal patterns across many frames. Lightweight CNNs or small Transformer encoders are natural for fast triage because they are efficient with careful architecture choices; larger 3D models or ensembles are better for offline, high-accuracy analysis. When we explain a choice, we say why: pick compact architectures when latency and on-device memory are limiting factors, and deeper temporal models when you must capture temporally inconsistent artifacts.
Practical model selection hinges on concrete trade-offs and measurements. We judge candidates not only by accuracy but by false positive rate (how often real clips are wrongly flagged), calibration (how well confidence scores reflect true probability), latency (time per clip), and throughput (clips per second). To make heavy models feasible in practice, apply model compression techniques: pruning removes redundant weights, quantization reduces number precision for faster arithmetic, and knowledge distillation trains a small “student” model to mimic a larger “teacher.” Define pruning as removing unnecessary parameters and quantization as lowering numeric precision; both preserve performance while cutting computational cost.
Training strategy and robustness are part of the selection decision, not an afterthought. Augment training data with realistic platform compression and adversarial variants to mimic the manipulations attackers will use; consider adversarial training (teaching the model to resist small, crafted perturbations) and human-in-the-loop feedback to correct systematic errors. For continual drift—when new manipulation styles appear—set up automated monitoring that tracks performance on held-out streams and triggers scheduled retraining or incremental updates when accuracy or calibration degrades.
Finally, picture a concrete pipeline you might deploy for breaking-news triage: extract aligned face crops, compute a compact face embedding and a small motion descriptor, run a tiny CNN to produce a confidence score, and apply a calibrated threshold that routes high-risk items to a slower ensemble plus a human reviewer. This approach ties our feature choices to the model selection in a measurable way and sets the stage for deployment, explainability, and monitoring—the next parts of our journey where we turn decisions into transparent, operational safeguards.
Train, Validate, and Evaluate Models
Imagine you’ve built a prototype that can flag suspicious clips, and now the question is simple and urgent: is the model actually ready to stop viral fakes? Building on the preprocessing and dataset choices we just discussed, this next stage turns raw ingredients into a working deepfake detection system by training, validating, and evaluating models so they behave predictably in the wild. Training is where the model learns patterns from examples; evaluation is where we test whether those learned patterns generalize to new, realistic content. How do you know when a model is ready for real-time inference, and what does “ready” even mean in measurable terms?
Start training by treating data strategy as your north star: pick balanced splits, handle class imbalance explicitly, and mix datasets so the model won’t overfit to one manipulation style. Define an epoch as one pass through your training set and a batch as the subset processed at once; these control stability and compute. Use augmentation—re-encoding, color jitter, synthetic occlusions—to simulate platform distortions we expect, and choose loss functions that reflect the costs in our threat model (for example, weighted binary cross-entropy if false negatives are especially damaging). When you see validation loss diverge from training loss, that’s overfitting, and it tells us to regularize, add data, or simplify the model.
Validation is our rehearsal stage: it’s how we tune hyperparameters and estimate generalization before any real deployment. Define a held-out validation split and then go further with cross-dataset validation—train on one corpus and test on another—to measure transferability and robustness. Consider k-fold validation when data is limited so we learn from many different train/validation partitions. Use the validation set to drive early stopping (halting training when performance stops improving) and to select checkpoints that balance accuracy, false positive rate, and latency for the two-stage pipeline we favor.
Metrics are the language we use to decide whether the model meets our goals, and choosing them deliberately matters more than chasing a single number. Precision measures how many flagged videos are actually fake, while recall (or true positive rate) measures how many fakes we catch; a false positive rate (FPR) shows how often real videos are wrongly flagged, and the false negative rate (FNR) shows how many fakes slip through. We also report AUC (area under the ROC curve) for threshold-agnostic ranking and separate frame-level versus video-level metrics so we know whether the model is consistent across time. How do you pick a decision threshold? Use the validation set to align thresholds with your operational targets (for example, a low FPR for high-impact content and a higher recall for triage scenarios).
Beyond raw scores, calibration and explainability tell us whether to trust a model’s confidence at scale. Calibration means predicted probabilities match real-world frequencies; a calibrated classifier that says 80% should indeed be correct about four in five times. Tools like reliability diagrams and temperature scaling are practical ways to measure and fix miscalibration. Pair calibrated scores with explainable signals—highlighted frames, attention maps, or per-frame confidence traces—so human reviewers can verify why a clip was flagged and reduce costly false positives through a human-in-the-loop workflow.
Finally, treat evaluation as an ongoing practice, not a one-off checkbox, and connect it back to our operational constraints like latency and throughput. Deploy a two-stage system for real-time inference: a lightweight triage model at the edge and a heavier forensic ensemble in the cloud, and continuously monitor live performance on labeled streams to detect drift. When metrics slip on held-out cross-dataset tests or live traffic, schedule targeted retraining with fresh examples and adversarial augmentations. With this cycle of careful training, rigorous validation, and continual model evaluation, we turn experimental detectors into operational safeguards ready to keep viral deepfakes from spreading.
Real-Time Optimization and Deployment
Building on the pipeline and evaluation steps we just covered, the practical work now is getting models to run fast enough in the real world without losing the signals that catch manipulated video. In real-time deepfake detection we care first about latency (how long a decision takes) and throughput (how many clips we can process per second), and we make engineering choices—the model, where it runs, and how we serve it—that trade off accuracy for speed. Think of deployment as the bridge between a model that works in a lab and a system that protects people on a timeline: it must be predictable, measurable, and resilient.
The first choice you face is location: run inference on-device at the edge, or in the cloud. Edge inference means the model runs on the user’s phone or on platform edge servers; this lowers data movement and can cut detection latency, but it limits model size and requires careful on-device model optimization. Cloud inference lets you use larger, more accurate ensembles and more expensive forensic checks, but introduces network latency and higher operational cost. How do you keep latency low while preserving accuracy? We pick a two-stage pattern: a compact triage model at the edge or ingress that produces a fast confidence score, and a heavyweight forensic ensemble in the cloud that inspects anything above a suspicion threshold.
Model optimization is the set of techniques that make that two-stage idea practical. Pruning (removing redundant weights), quantization (reducing numeric precision such as from 32-bit to 8-bit integers), and knowledge distillation (training a small “student” model to mimic a large “teacher”) are the characters we introduce here—each is a trade-off between size, speed, and fidelity. Define quantization as lowering numeric precision to speed math on hardware, and pruning as deleting weights that contribute little; both often reduce model footprint by orders of magnitude. In practice we test combinations: int8 quantization plus distillation frequently gives big speedups with acceptable detection drops, and using hardware-optimized runtimes (for example TensorRT, ONNX Runtime, or platform-specific NN runtimes) squeezes additional latency gains.
Serving architecture matters as much as the model itself. A low-latency inference service is usually asynchronous: the ingestion layer decodes and extracts faces, the triage model runs immediately, and suspicious items are queued for heavier cloud workers. Batching strategies help throughput—processing several face crops together is more efficient on GPUs—but batch size increases latency, so we tune batch windows to meet our service-level objectives (SLOs), where an SLO is the latency or availability target you promise your system will meet. Canary deployments and A/B tests let us measure real user impact: deploy a compressed model to a small percentage of traffic, compare false positive and false negative rates against the baseline, then roll forward if metrics are acceptable.
Scaling and reliability are where containerization and orchestration come in. A container packages an app and its runtime so it behaves the same everywhere; container orchestration (tools like Kubernetes) manages many containers across machines, handling automatic scaling and restarts. For real-time inference, autoscaling rules should consider both CPU/GPU load and queue length to react to sudden viral spikes; use node pools with GPU-backed instances for forensic workers and smaller CPU/ARM pools for lightweight triage at the edge. Also plan for heterogeneous hardware: a model compiled to run efficiently on both mobile NPUs and server GPUs reduces brittle dependencies when traffic patterns change.
Observability, safety, and continuous learning close the loop. Instrument every stage with latency, confidence distribution, and human review outcomes so we can detect drift—the gradual degradation when attackers change tactics. Set alarms on calibration and false positive rate, log examples that human reviewers overturn, and feed those labeled examples back into a retraining pipeline. Continuous deployment for models requires a CI/CD pipeline that validates model checkpoints on representative holdouts, runs safety checks, and stages rollouts to avoid large swings in behavior.
Deployment is where engineering meets policy: choice of where to run inference affects privacy, cost, and speed, while model optimization and orchestration determine whether your real-time inference system actually prevents viral manipulation. With a measured two-stage architecture, hardware-aware optimizations, observability, and careful rollout practices, we can turn detection research into a dependable real-world defense and prepare to integrate explainability and human review in the next phase of the pipeline.



