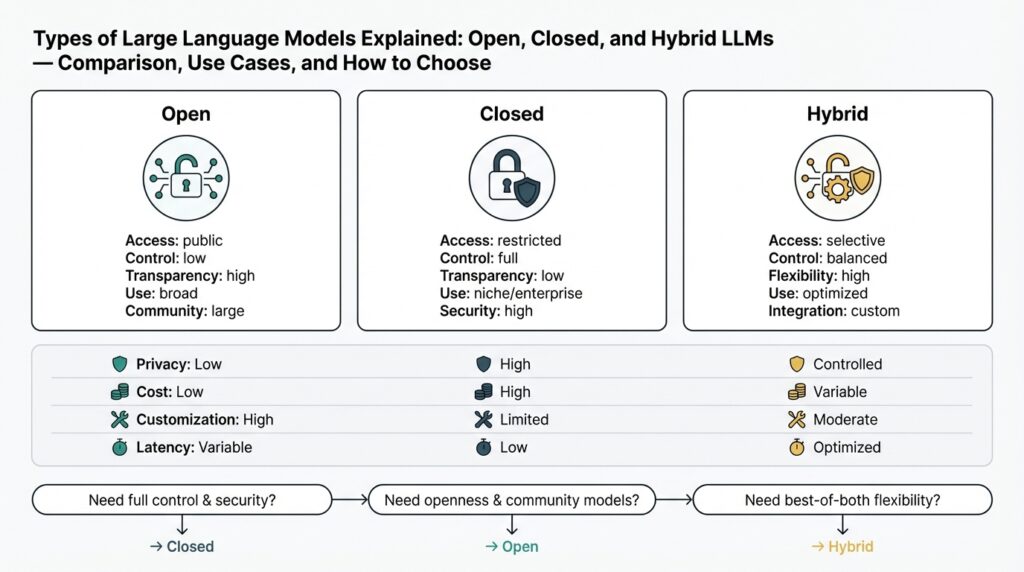
LLM types: open, closed, hybrid overview
Building on this foundation, it helps to separate practical LLM choices into three operational categories you’ll encounter: open LLM, closed LLM, and hybrid LLM. These terms map directly to trade-offs you make around control, data privacy, performance, and operational cost, so understanding them early shapes architecture decisions throughout a project. How do you choose between them when requirements collide (latency vs. compliance vs. cost)? We’ll walk through each type, concrete behaviors you should expect, and the patterns teams use to combine them safely.
An open LLM gives you source-level access or self-hosting capability for the model and often for the training data pipeline; think of this as full-stack control. You pay operationally for infrastructure and hands-on maintenance, but you can fine-tune, audit model weights, and integrate directly with internal data stores without sending text to a third-party API. In practice, teams use open-source models when they need aggressive customization—embedding domain-specific tokens, applying continual learning loops, or implementing white-box interpretability. Expect to provision GPUs, handle versioning of tokenizer/model artifacts, and orchestrate inference with batching or model parallelism to meet production SLA requirements.
A closed LLM is delivered as a managed API by a vendor and often provides the fastest path from prototype to production. Vendor models trade off control for convenience: you get scale, latency optimizations, hosting, and safety layers, but you must accept vendor policies on data retention and customization limits. For many consumer-facing chatbots or quick internal automation, closed LLMs reduce time-to-market—simply call the API, handle rate limits and secrets like Authorization: Bearer
A hybrid LLM architecture mixes both approaches to optimize for constraints that matter: run sensitive or low-latency inference on an on-prem or VPC-hosted open model, and route high-throughput or non-sensitive workloads to a vendor’s closed LLM. This often looks like a model-routing gateway plus a retrieval layer: use a local vector DB and embeddings for private knowledge, then fall back to an external LLM for creative or compute-heavy tasks. Architecturally, implement a routing policy such as: if request.sensitivity >= threshold -> local_model; else -> vendor_api. This pattern preserves privacy and reduces egress costs while leveraging vendor improvements for the remaining workload.
When evaluating which path to take, focus on actionable criteria: classify your data sensitivity, quantify acceptable latency, estimate inference cost per 1,000 requests, and determine how much model customization you need. If you must keep PII in-house, favor open LLM or hybrid with strict data-flow controls and audit logs. If rapid iteration and small engineering headcount are priorities, a closed LLM accelerates shipping with fewer infra burdens. For many teams, the sensible tactic is iterative: prototype on a closed LLM to validate UX and prompts, then migrate sensitive or high-volume flows to a hybrid or fully open deployment once scale and compliance requirements are clear.
Taking this concept further, design your CI/CD and observability from day one so swapping models or toggling routes becomes routine. Implement model evaluation suites, latency budgets, and cost dashboards tied to your routing logic; these guardrails let you evolve from closed to hybrid or open LLM strategies without disrupting users. In the next section we’ll examine operational patterns—deployment topologies, monitoring signals, and retrieval augmentation—that let you implement these choices reliably in production.
Open LLMs: features, strengths, and tradeoffs
Building on this foundation, the real value of an open LLM shows up when you need deep control over model behavior, deployment, and data flow. You gain access to model checkpoints, tokenizers, and training pipelines so you can replicate, modify, and audit every stage of the stack. That control enables deterministic CI for models, deterministic tokenization across environments, and the ability to embed domain-specific tokens or vocabularies that closed APIs won’t accept. For teams that must prove provenance or run repeatable evaluations against private benchmarks, open-source models and self-hosting are often non-negotiable.
A defining set of features separates open LLM deployments from managed offerings: access to raw weights and checkpoints, the ability to fine-tune or apply parameter-efficient adapters, full control over data retention and telemetry, and the freedom to instrument inference for custom metrics. You can bake in custom tokenizers, swap training corpora, and run continual learning loops that adapt models to fresh internal data. These features let you treat the model as part of your product rather than a black-box service and integrate it tightly with in-house retrieval systems, private vector stores, or custom prompt preprocessing pipelines.
The strengths are practical and measurable. Customization at the weight level—using techniques like LoRA or full-finetune—lets you align a model to industry jargon, proprietary workflows, or regulatory constraints in ways prompts alone cannot. Running locally gives you consistent low-latency inference for SLA-sensitive paths and predictable cost-per-inference at scale because you control hardware choices and scaling policies. Auditability and explainability improve because you can snapshot model versions, rerun tests, and inspect attention maps or intermediate activations when investigating failures. When compliance or IP protection is a requirement, keeping models and data in-house removes many contractual and legal blockers.
Those benefits come with clear tradeoffs you must plan for. Operating an open LLM means owning the full stack: provisioning GPUs/TPUs, managing quantization and memory optimization, handling model versioning, and building safety filters you’d otherwise get from a vendor. Engineering costs rise—DevOps, MLOps, security, and cost-control tooling are necessary—and model quality can lag behind proprietary, frequently-updated vendor models unless you commit to active maintenance. Licensing complexity is another pitfall: some open-source models carry use restrictions or copyleft clauses that affect commercial deployment. Finally, you inherit attack surface: prompt injection, data leakage, and dependencies in third-party libraries require active defenses and regular audits.
How do you make these tradeoffs practical in production? Start with concrete patterns: use parameter-efficient fine-tuning (LoRA) to reduce GPU requirements, apply 4-bit/8-bit quantization for memory savings with a measured accuracy baseline, and containerize models with well-defined resource requests so orchestration tools can autoscale. Example deployment pattern in Python (sketch):
from transformers import AutoModelForCausalLM, AutoTokenizer
# load quantized model and resume LoRA weights
tokenizer = AutoTokenizer.from_pretrained('my-open-model')
model = AutoModelForCausalLM.from_pretrained('my-open-model', load_in_4bit=True)
model.load_adapter('my-lora-adapter')
input_ids = tokenizer('Summarize our policy doc:', return_tensors='pt').input_ids
print(model.generate(input_ids, max_new_tokens=200))
This pattern keeps engineering costs bounded while preserving customization.
When should you pick an open LLM path versus a hybrid approach? Choose open LLM or self-hosting when you must control data egress, require model-level customization, or need deterministic evaluation tied to internal benchmarks. Favor hybrid if you want to prototype quickly with a closed API and then move sensitive flows on-prem once requirements stabilize. Whatever you choose, instrument routing logic, cost dashboards, and model evaluation suites from day one so you can pivot between open, closed, and hybrid strategies without disrupting users—this operational discipline is what turns the theoretical strengths of open-source models into reliable production value.
Closed LLMs: capabilities, limits, and risks
Building on this foundation, closed LLMs give you a managed, vendor-hosted path to production that trades control for convenience. Closed LLMs surface high-quality model checkpoints through an API, optimized inference latency, and ongoing model improvements behind the scenes—so you can validate UX and iterate on prompts without owning GPUs or orchestration. This convenience accelerates time-to-market for many automation and chat scenarios, but it also concentrates important architectural decisions around data flow, SLAs, and contractual obligations early in your design. How do you decide when that trade-off is acceptable for your product or compliance posture?
The core capabilities of a closed LLM are predictable performance, operational scale, and built-in safety primitives. Vendors typically provide latency-optimized endpoints, autoscaling, monitoring dashboards, and sometimes content-filtering or rate-limiting primitives that reduce engineering toil; these features let you focus on prompt engineering, retrieval augmentation, and UX. For teams building consumer-facing assistants or internal automation with non-sensitive inputs, a closed LLM often delivers the best cost-to-velocity ratio: you offload patching, model upgrades, and model-card maintenance while retaining programmatic control over prompts and session state. In practice, you’ll pair a managed API with a private retrieval layer and token caching to control costs and responsiveness.
Important limits emerge when you surface sensitive data, require deep customization, or must prove provenance. Closed LLMs commonly restrict weight-level fine-tuning, limit access to training data provenance, and enforce vendor data-retention policies that may conflict with regulatory needs. Auditability and explainability suffer because you can’t snapshot or inspect internal activations; when an output causes a regulatory incident or an erroneous decision, reproducing the exact model state can be difficult if the vendor has rolled a hidden update. These limits make closed LLMs a poor fit when you must guarantee no egress of PII, run deterministic evaluation tied to internal benchmarks, or embed proprietary vocabulary that affects tokenization.
There are concrete operational and security risks to manage beyond contractual terms. Data egress and retention policies create legal exposure in regulated industries; prompt or context leakage can expose secrets to vendor logs; and vendor-side model updates can change behavior mid-release, producing drifting outputs. Additionally, closed models can hallucinate or produce unsafe content in domain-specific contexts, which amplifies downstream risk in automated decision systems. To reduce exposure, we recommend design patterns like pre-filtering sensitive fields, routing high-sensitivity requests to a local model or on-prem proxy, encrypting embeddings before sending them to a vendor where possible, and negotiating explicit data-use clauses and audit rights in contracts.
Operationally, the pragmatic pattern is to treat a closed LLM as one component in a routing strategy rather than the sole compute plane. Implement a sensitivity classifier upstream of your router so requests with PII or high compliance risk route to an open or on-prem model, while low-risk requests use the vendor endpoint for scale. Add observability: log inputs and outputs (with redaction policies), implement A/B evaluation hooks to detect behavioral drift after vendor updates, and run periodic red-team tests against critical flows. We often combine parameter-efficient local adapters for privacy-critical prompts and use vendor models for high-throughput summarization or creative generation, giving us both control and scale.
Taking these trade-offs into account will let you extract the speed and scale benefits of managed models while limiting their liabilities. As we discussed earlier, hybrid architectures are the usual next step when closed LLMs hit compliance or customization walls, so the next section will walk through deployment topologies, routing policies, and monitoring signals you can use to operationalize that hybrid approach without disrupting users.
Hybrid LLMs: architecture, routing, and benefits
Building on this foundation, think of a hybrid LLM deployment as a distributed decision plane that routes requests to the right compute plane based on risk, SLA, and capability. How do you design routing policies that balance latency, cost, and privacy? We’ll treat the architecture as three cooperating layers—ingest and classification, routing and orchestration, and the inference plane—so you can reason about placement, observability, and failure modes rather than just picking a model. That framing keeps us pragmatic: the architecture exists to enforce data boundaries while preserving vendor innovation where it makes sense.
At the heart of the system sits a routing gateway that implements model routing and policy enforcement. The gateway accepts requests, runs a lightweight classifier (sensitivity, domain, required creativity), enriches context via a local retrieval augmentation layer (private vector DB), and then selects a target: an on-prem open model for sensitive/low-latency paths or a vendor endpoint for high-throughput, non-sensitive generation. You can place this gateway as a central API or as sidecars next to services that produce requests; sidecars reduce round-trip latency for internal traffic, while a central gateway simplifies auditing and quota enforcement. Design the inference plane so local models are quantized and adapter-tuned for private data while vendor calls are batched and cached.
Decisions should be multi-dimensional rather than binary. Instead of a single sensitivity flag, compute a routing score that combines sensitivity, latency budget, and cost budget: score = w_s * sensitivity + w_l * (latency / SLA) + w_c * (estimated_cost / budget). If the score exceeds a threshold we route to the private model; otherwise, we use the vendor. You’ll want dynamic weights so routing can change with load or budget windows—during peak hours favor the vendor for throughput, during audits favor local inference. We often implement this as a small policy service with canaryable rulesets and feature flags so we can A/B routing decisions and measure real impact.
Retrieval augmentation is where hybrid deployments deliver the most practical value. Keep your private knowledge in a local vector store and only send the minimal necessary context to external models; for example, retrieve top-k semantically relevant chunks, redact PII, and send just those embeddings or summaries to the vendor. When you must call a vendor for generation, consider sending encrypted or hashed embeddings where supported, or convert sensitive facts into placeholders that get rehydrated locally after generation. Also use context-window management techniques—chunk overlap, salient-sentence extraction, and provenance metadata—so you can attribute outputs back to sources and make hallucinations auditable.
Operationally, treat routing as a first-class metric. Instrument latency (95th and 99th percentiles), cost per inference, routing distribution (percent routed to local vs. vendor), and an error/hallucination signal derived from downstream tests or human feedback. Build a CI pipeline for model artifacts and routing rules so you can promote a policy from staging to production with tests that include privacy regression checks and load tests against on-prem GPUs. Deploy canaries for new local adapters and run A/B comparisons against the vendor model to detect behavioral drift before flipping routes broadly.
The benefits are concrete: you reduce egress and compliance risk by keeping sensitive flows local, lower expected cost by offloading non-sensitive volume to vendor scale, and retain access to vendor innovations for needs you can’t economically meet in-house. The trade-off is operational complexity—you’ll need a policy service, observability, autoscaling of local GPUs, and periodic recalibration of thresholds. A practical path is iterative: prototype on a vendor model to validate UX, then incrementally shift privacy-critical or high-volume flows to the hybrid stack while continuously measuring latency, cost, and safety. This staged approach preserves velocity while turning routing policy into a lever you can tune as requirements evolve.
Compare costs, performance, and privacy tradeoffs
Building on this foundation, choosing between an open LLM, a closed LLM, or a hybrid LLM comes down to three concrete axes you can measure: cost, performance, and privacy. How do you balance those axes when requirements contradict each other? Start by treating each axis as a budget you can trade against—engineering hours, dollars per inference, and allowable data egress—and then translate business requirements into numeric thresholds (latency budget, monthly volume, sensitivity level) that drive an explicit routing policy.
Cost decisions split into predictable operational spend versus variable vendor fees. With a closed LLM you typically pay per-call or per-token and offload infrastructure and maintenance; this converts capital expenditure into an operational line item and lowers upfront engineering cost. Self-hosting an open LLM shifts cost into infra, staff, and tooling: amortize GPU/instance cost, storage, and SRE time across expected QPS to compute a raw cost-per-inference, and include hidden costs like maintenance, security audits, and model tuning. For example, if you amortize an inference cluster monthly cost into expected requests, you get a concrete break-even volume where self-hosting becomes cheaper than vendor calls—use that break-even as the trigger to move high-volume, low-sensitivity flows on-prem or to a hybrid split.
Performance tradeoffs are primarily about latency tail and throughput. Vendor endpoints often deliver strong median latency and seamless autoscaling, which accelerates time-to-market for high-throughput pipelines; however, network round trip and vendor throttling influence 95th/99th percentile latency. Self-hosted models let you colocate inference near services, reduce RTT, and tune batching, quantization, or model parallelism to control tail latency for SLA-critical paths. In practice, we run latency-sensitive calls (authentication, real-time suggestions) on a tuned local model or sidecar, and route bulk summarization or creative generation to a vendor—the hybrid approach lets you optimize both throughput and strict latency budgets.
Privacy tradeoffs are often the decisive factor in regulated or IP-sensitive environments. Closed LLMs introduce egress and retention risk because prompts and contexts can live on vendor logs unless contractually restricted; open LLMs give you full control over data lifecycle and telemetry but require you to implement redaction, access controls, and audit trails. Hybrid patterns reduce exposure: keep private knowledge in a local vector store, send only minimal, redacted context to external models, or call the vendor with hashed/encrypted embeddings where possible. Design your pipeline so the sensitivity classifier and router enforce hard boundaries—requests above a sensitivity threshold never leave the VPC—and log provenance metadata so outputs can be traced back to source documents for audits.
Weighing these axes together demands a pragmatic decision rule rather than ideology. Translate sensitivity, latency, and volume into a simple routing score (for example: score = w_s * sensitivity + w_l * latency_ratio + w_c * cost_ratio) and run canaries to validate that routing changes do not degrade safety or UX. Monitor cost-per-inference, routing distribution, and hallucination/error signals as first-class metrics in your dashboards; when cost-per-inference or drift crosses a threshold, promote flows to a different plane. Use parameter-efficient fine-tuning, quantization, and container orchestration to lower self-hosted costs, and negotiate explicit data-use and audit clauses with vendors to lower closed-model privacy risk.
Taking this concept further, treat routing policy as an operational lever you can tune over time rather than a frozen choice. Prototype on a closed LLM to validate UX and prompt engineering, then iteratively shift high-volume or privacy-sensitive flows to self-hosted inference when your break-even and compliance checks are met. In the next section we’ll examine concrete deployment topologies, routing implementations, and observability signals you should build so you can safely and measurably move between vendor, local, and hybrid LLM planes without disrupting users.
Selecting an LLM: checklist and decision guide
Building on this foundation, start with a practical, testable checklist that maps your product requirements to specific LLM deployment choices: LLM type, data privacy controls, latency budget, cost model, and operational capacity. In the first 100–150 words you should name the trade-offs out loud—open LLM control vs. closed LLM convenience vs. hybrid LLM routing—so the team understands what will be traded for speed, privacy, and scale. This upfront naming helps you avoid vague debates and lets you convert qualitative needs into measurable thresholds from day one. How do you convert product requirements into those thresholds and a repeatable decision process? We’ll walk through a decision-oriented guide you can use immediately.
The first step is requirement quantification: classify data sensitivity, set latency SLAs, estimate monthly request volume, and specify customization needs. For sensitivity, define concrete categories (for example: public, internal, regulated) and map each category to a required handling rule—do not allow regulated data to leave the VPC, redact internal secrets before external calls, etc. For latency, pick numeric SLAs (median and 95th/99th percentiles) tied to user experience; real-time suggestions demand tighter budgets than batch summarization. For cost, calculate expected cost-per-1k calls for closed models and amortized infra cost for self-hosting so you can compute a break-even volume that triggers a hybrid or open LLM decision.
Next, apply a decision flow that combines those criteria into a routing policy you can implement and test. If sensitivity is above your threshold, route to a local open LLM; if latency budget is under X ms and volume is low, prefer a colocated model or sidecar; if customization requires weight-level fine-tuning, prefer an open LLM unless the vendor offers robust adapter APIs. Use parallel rules rather than a single flag—combine sensitivity, latency_ratio = latency/SLA, and cost_ratio = cost/ budget into a simple score so trade-offs are explicit and tunable. This arithmetic lets you run canaries where, for example, requests with score > 0.7 go local and lower-scoring requests use a closed LLM until observed metrics validate the split.
In practice, validate decisions with a staged experiment: prototype UX and prompts on a closed LLM to iterate quickly, then instrument the prototype to collect latency percentiles, hallucination/error rates, and monthly spend. Use those measured values to compute your break-even and risk thresholds—if median latency is acceptable but 99th percentile violates an SLA, consider a local sidecar for tail-sensitive flows. If monthly volume for a flow exceeds the break-even and sensitivity is moderate, plan a migration path to hybrid LLM routing that moves only that high-volume flow on-prem. Quantify success criteria for each migration step so you can roll back if behavioral drift or cost surprises appear.
Security, contract, and compliance checks must be baked into the checklist as hard gates rather than advisory notes. Negotiate explicit data-retention and audit rights with vendors when you decide to use a closed LLM, and require encryption-in-transit and at-rest for any vectors or context sent externally. Implement upstream redaction and a sensitivity classifier that flags PII and regulated content; ensure those flagged requests never hit vendor endpoints. We recommend including a legal sign-off step for any flow that touches regulated data so architecture decisions are aligned with contractual obligations.
Operationalize the checklist by building the routing and observability primitives that let you iterate safely. Create a policy service with feature flags for routing rules, instrument latency (p50/p95/p99), cost per inference, routing distribution, and a hallucination/error signal derived from human review or automated unit tests. Add CI for model artifacts and routing rules so you can promote changes with reproducible tests; run canaries and A/B experiments to compare local adapters against vendor models before changing routes broadly. Treat the routing policy as an operational lever you can tune based on real metrics, not a one-time architectural choice.
Taking this approach makes model selection a repeatable engineering practice rather than a binary bet. By quantifying sensitivity, latency, cost, and customization early, and by prototyping on a closed LLM before migrating critical flows to open or hybrid LLM deployments, we preserve product velocity while controlling risk. In the next section we’ll translate these checklist items into concrete routing implementations and observability dashboards you can deploy in your CI/CD pipeline.



