Prepare Transaction Data
When you first open a file of raw transactions, it can feel less like data and more like a receipt drawer that has been tipped onto the floor. That is the moment where customer segmentation analytics either starts to become useful or starts to drift into confusion. Before we can group customers into meaningful segments, we need transaction data that is clean, consistent, and trustworthy enough to tell the same story every time we read it.
At its core, transaction data is the record of each purchase, refund, cancellation, or adjustment tied to a customer. Each row usually carries details like a customer ID, a date, an amount, and maybe a product category or channel. The challenge is that real business systems rarely speak the same language, so the same person may appear under slightly different names, dates may use different formats, and refunds may be mixed in with sales. How do you turn that messy history into something segmentation models can actually use? By preparing it carefully, one field at a time.
The first step is identity cleanup, because segmentation starts with knowing who is who. If one customer appears as “A. Smith,” “Ann Smith,” and “[email protected],” those records need to be linked before any analysis begins. Think of this like sorting mail for a neighborhood: if the address label is inconsistent, the letters end up in the wrong pile. In customer segmentation analytics, that same mistake can split one buyer into several fake customers, which quietly distorts everything that comes after.
Next, we make the numbers and dates behave the same way. A transaction amount should use one currency, one decimal style, and one clear rule for returns and discounts, while timestamps should follow one date format and one time zone. This matters because a model does not understand that “$25,” “25.00,” and “USD 25” mean the same thing unless we tell it. When you standardize these details, you are not polishing the data for show; you are making sure the calculations behind customer segmentation are fair and comparable.
This is also the stage where we decide what counts as a real transaction. A completed purchase usually belongs in the analysis, while a canceled order, duplicated record, or test order may need to be removed or marked separately. Refunds deserve special care, because they can either reduce a customer’s value or signal a very different buying pattern depending on the business question. In other words, preparation is not only about cleaning data; it is about choosing the rules that define the story.
Once the records are clean, we can look for missing values, unusual spikes, and outliers. A missing category might be harmless, or it might hide an important part of the customer journey, so we need to check before we fill it in or drop it. A single huge purchase could be a genuine high-value order or a data error, and the difference matters when you are studying customer behavior. This is where careful judgment helps more than speed, because one bad assumption can bend the whole segmentation picture.
It also helps to keep a raw copy of the original file before we begin transforming anything. That untouched version acts like a safety net, letting us trace back a decision if a segment looks strange later on. We can then build a prepared version for analysis while preserving the source of truth underneath it. Taking this step may feel tedious, but it is one of the simplest ways to make customer segmentation analytics easier to trust and easier to explain.
With the data cleaned and standardized, we are finally ready to shape it into features the analysis can use, such as purchase frequency, average order value, or recency of the last transaction. That is the bridge from raw transactions to patterns we can actually compare. Once this foundation is in place, the next step becomes much more interesting, because we can start turning a long list of purchases into a clear picture of customer groups and their behavior.
Create RFM Scores
Building on this foundation, we can turn each customer’s transaction history into RFM scores—a compact way to describe how recently they bought, how often they buy, and how much they spend. If the raw transaction table is the story’s notebook, RFM scoring is the highlighter that pulls the most important signals into view. How do you turn a pile of purchases into something you can compare at a glance? You rank each customer on those three behaviors so customer segmentation becomes clearer and easier to act on.
The three pieces of the puzzle are straightforward once we name them. Recency means the time since the last purchase, frequency means how many times a customer bought during the period you are studying, and monetary value means how much they spent. Here is the part that often trips people up: recency works backward from the others, so a lower number of days usually deserves a higher score because recent buyers are generally considered more engaged. In a common five-point scale, the most recent, most frequent, or highest-spending customers receive 5, while the weakest performers in each measure receive 1.
Once those measures are calculated, we sort customers into groups for each one. Think of it like ranking runners in three different races: one for how recently they crossed a finish line, one for how often they show up, and one for how much effort they put in. Many RFM scoring setups use five equal-sized groups, often called quintiles, so each customer gets a recency score, a frequency score, and a monetary score on the same 1-to-5 scale. That consistency matters because it lets us compare customers on one common language instead of three separate spreadsheets.
After that, we combine the three scores into a single RFM code. A customer with a 5 for recency, 5 for frequency, and 5 for monetary value might be labeled 555, while someone who bought long ago, rarely, and for a small amount might look more like 155 or 111. This is where RFM scoring starts to feel practical, because a short code can quickly hint at behavior: loyal buyers, big spenders, newly active customers, or customers who may be drifting away. It is a bit like a report card for buying habits, except the grade is built from real transactions instead of classroom work.
The real value appears when you read those codes as patterns, not as isolated numbers. A customer with strong frequency and monetary scores but weaker recency may be valuable but slipping, while a customer with high recency and low frequency may be new and worth nurturing. That is why customer segmentation analytics uses RFM scores as a bridge: they turn raw behavior into a ranking system that helps you decide who needs a reminder, who deserves a reward, and who may be ready for a deeper segment analysis. With these scores in hand, we can move from measurement to interpretation and begin grouping customers into meaningful segments.
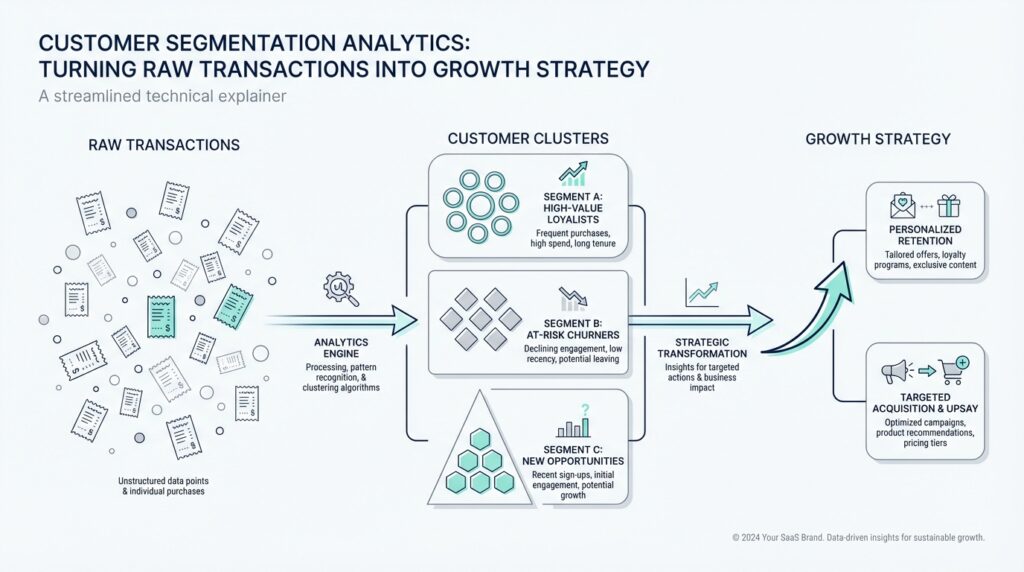
Cluster Customer Segments
Building on this foundation, we can now let the scores start talking to one another. Once you have recency, frequency, and monetary value in hand, the next question is not who is best or worst in isolation, but which customers move together in similar ways. That is where cluster analysis, a method for grouping records that behave alike, comes in. In customer segmentation analytics, clustering helps us discover natural customer segments instead of forcing people into labels that were guessed ahead of time.
How do you turn those RFM scores into groups that feel real enough to use? We give the algorithm a few signals about each customer, then let it look for patterns in the space those signals create. Think of each customer as a point on a map: one point may sit near other recent, frequent, high-spending buyers, while another lands far away among quiet, infrequent shoppers. A cluster is simply a neighborhood on that map, where the points are close together because their behavior is similar.
This is the moment when the abstract becomes practical. If two customers both buy often, spend generously, and purchased recently, clustering is likely to place them in the same segment even if their exact numbers are not identical. That is useful because real business audiences rarely fit into perfect boxes; they move in shades and patterns. Customer segmentation analytics works well here because it respects those shades and turns them into groups you can understand, compare, and act on.
One common approach is k-means clustering, a technique that splits customers into a set number of groups by placing each person near the closest group center. The name sounds more intimidating than the idea really is. Picture several campfires in a dark field: each customer walks toward the fire that feels closest based on their behavior, and the campfires shift until the groups settle into a stable pattern. Other methods exist too, but the key idea stays the same: similar customers should end up together, and different customers should stay apart.
Now that we understand the basic motion, we need to make one careful choice: how many clusters should we create? Too few, and very different customers get lumped together, which hides important differences. Too many, and the segments become so small and specific that they stop being useful for marketing, service, or growth planning. In practice, we look for a balance between clarity and actionability, because customer segmentation analytics is only helpful when the groups can support a real decision.
This is also where interpretation matters more than the math. A cluster does not become valuable just because it exists; it becomes valuable when we can describe the people inside it in plain language. One segment might contain loyal regulars who buy often and spend steadily. Another might hold new customers who bought recently but have not yet built a habit, while a third may contain high-value shoppers who are starting to fade. Those stories are what make clustering feel less like statistics and more like a customer map we can actually read.
Once the segments appear, the next step is to name them in a way your team can remember. A label like “champions” or “at-risk loyalists” is far more useful than a code like Cluster 3, because the label reminds everyone what behavior the group represents. That does not mean the cluster is a personality type or a fixed identity; it is a pattern in the data, and patterns can change as customers buy more, buy less, or stop buying altogether. This is why we revisit segments regularly in customer segmentation analytics, rather than treating them as permanent.
Taken together, clustering gives us a bridge from scores to strategy. RFM tells us how customers behave on three important axes, and cluster analysis shows us which combinations of that behavior tend to travel together. With those groupings in place, we can stop looking at the customer base as one long line of transactions and start seeing it as a set of living, changing neighborhoods. That shift is what makes the next decisions sharper, because now we know not only who our customers are, but how they naturally gather into meaningful customer segments.
Profile Segment Behavior
Building on this foundation, profile segment behavior is where customer segmentation analytics starts to feel human. Instead of looking at customers as rows of scores, you ask what a segment looks like in real life: who is in it, how they buy, and what they tend to do next. A customer profile is a file of relevant data about a customer, including interactions, traits, behaviors, and buying preferences, and modern customer platforms often combine profile, transactional, and behavioral data into one view. That single view gives us the material we need to describe a segment in plain language rather than in code.
How do you profile a segment without losing the story inside the numbers? We start by reading the shared patterns that the cluster already hinted at and then translate them into business language: recent buyers, steady repeat purchasers, promo-sensitive shoppers, or customers who are drifting away. Oracle’s segmentation guidance treats behavioral and purchase behavior as key dimensions because the goal is to understand shopping patterns, not only to sort records. This is where customer segmentation analytics becomes useful for teams, because the segment stops being an abstract group and starts acting like a recognizable customer type.
The next layer is context. Two customers can share the same RFM code yet behave differently in important ways, such as one buying across many categories and another buying the same item every month; that is why profile segment behavior should include channel preference, product mix, and engagement style when the data is available. Oracle describes behavioral data as actions across channels such as web, app, chat, and transactions, while IBM notes that customer profiles often bring together spend, purchase behavior, and demographics. In practice, this helps you explain not only that a segment is valuable, but why it is valuable and how it prefers to interact.
Once we can describe the behavior, we can look for the edges of the segment. Every group has members who fit the pattern neatly and a few who sit on the border, and those borderline customers are often the ones worth watching most closely. A segment with strong purchase frequency but falling recency may need a win-back message, while a new high-spend segment may need education or onboarding before loyalty forms. The behavior profile acts like a weather report: it does not tell you exactly what each customer will do, but it gives you a practical forecast for the next decision.
This is also why naming the segment matters. A label such as “frequent value seekers” or “at-risk loyalists” gives your team a shared shorthand for the behavior you observed, and platforms built for customer segmentation can drill from a segment view into individual customer records when you need to check the details. That drill-down keeps the profile honest: if the story sounds too neat, you can open the customer-level evidence and see whether the pattern really holds. It is a small habit, but it protects customer segmentation analytics from turning into guesswork.
With that in place, the segment profile becomes a working tool rather than a static description. You can use it to choose the right message, the right offer, and the right timing because you now understand the behavior that sits underneath the score. As we discussed earlier, the scores tell us who clusters together; profiling tells us what those clusters mean in practice. That is the bridge from observation to action, and it is what lets the next stage of customer segmentation analytics feel less like analysis and more like strategy.
Analyze Cohort Trends
Building on this foundation, we now want to watch customers as they move through time, not just as they sit in a segment on day one. That is where cohort trends become powerful in customer segmentation analytics, because a cohort is a group of customers who share a starting point, such as the month they first bought, signed up, or activated their account. If segments tell us who customers are, cohort analysis helps us see how those customers behave after their first step, which is often where the real story begins.
So how do you analyze cohort trends without getting lost in the timeline? We start by lining customers up by their shared starting event and then tracking what happens in the weeks or months that follow. Think of it like watching different classes of seedlings planted at different times: one group may sprout quickly, another may slow down, and a third may fade early. In customer segmentation analytics, that same pattern can reveal whether newer acquisition groups are sticking around, spending more, or drifting away faster than earlier ones.
The simplest cohort view usually focuses on retention, which means the share of customers who come back after their first purchase or signup. A retention curve shows how many people remain active over time, and that curve often tells a clearer story than a single average ever could. If one cohort drops sharply after the first month while another holds steady, we know something changed in the customer experience, the product, or even the acquisition channel. That makes cohort trends especially useful because they do not just describe the past; they hint at what kind of customers each period is bringing in.
Once that pattern is visible, we can compare cohorts across different business periods and ask better questions. Why do customers who arrived in one quarter keep buying longer than customers who arrived in another? Did a promotion attract a large wave of buyers who never returned, or did a product update bring in a smaller but more loyal group? These are the questions that turn cohort analysis from a reporting exercise into a growth tool, because you are no longer measuring only volume, but quality over time.
This is also where cohort trends help us separate seasonality from real behavior. A holiday cohort may look unusually strong at first because people bought during a busy shopping period, while a quiet-season cohort may start smaller but stay more engaged. If we ignore that context, we might praise or blame the wrong thing. By reading cohorts side by side, customer segmentation analytics helps us see whether a shift is tied to timing, channel, or a deeper change in customer loyalty.
We can also layer in other measures beyond retention, such as repeat purchase rate, average order value, or lifetime value, which is the total revenue a customer brings over their relationship with the business. These deeper views show whether a cohort is not only returning, but becoming more valuable as it matures. A cohort that starts small but spends more with each return can be more important than a larger cohort that quickly loses interest. That is why cohort analysis often rewards patience: the early numbers matter, but the later pattern may matter even more.
Now that we understand the shape of the trend, we need to read the edges carefully. A brand-new cohort will always look incomplete because it has had less time to mature, so we should not compare it too aggressively with older groups. That is a common mistake in customer segmentation analytics, and it can make healthy new customers look weak simply because they have not had enough time to show their full behavior. When should you trust a cohort trend? When the time window is fair, the starting event is clear, and the comparison groups have had a similar chance to develop.
At its best, cohort analysis gives you a living map of customer behavior. You can see which acquisition periods created durable customers, which ones faded early, and which ones may deserve a different nurture strategy. That makes the next step more grounded, because once we know how customer groups evolve over time, we can start turning those time-based signals into actions that improve retention, spend, and long-term growth.
Turn Insights Into Action
Building on this foundation, the real work begins when we stop admiring the segment map and start deciding what to do with it. Customer segmentation analytics is useful only when it changes a message, a campaign, a product decision, or a support response. So how do you turn a cluster or RFM code into something your team can actually use? We translate each pattern into a clear next step, the same way a chef turns a pantry list into a meal plan.
The first move is to match each segment with a purpose. A segment made of recent, high-value buyers may deserve early access, loyalty rewards, or referral prompts, because the goal is to deepen a relationship that is already strong. A segment of customers who used to buy often but have gone quiet may need a win-back campaign, which is a targeted message designed to bring inactive customers back. In customer segmentation analytics, the insight is not the finish line; it is the signal that tells you where to aim.
Once we know the goal, we can choose the right action. This is where lifecycle marketing, which means sending different messages at different stages of the customer journey, becomes especially powerful. New customers may need onboarding emails that teach them how to get value quickly, while loyal customers may respond better to premium offers or appreciation notes. What causes a segment to change the most? Often it is not the size of the offer, but whether the offer feels relevant to the behavior we already observed.
Now that we have the message, we need the channel. A segment that tends to buy through mobile app notifications may not react the same way to email, and a cohort that prefers longer consideration may need a slower sequence of touchpoints. Think of channel choice like choosing the right doorway into a room: you can have the right message and still miss the audience if you knock in the wrong place. This is another reason customer segmentation analytics matters, because it helps us align content, timing, and channel instead of treating every customer like they arrived through the same door.
The next step is prioritization, because not every segment deserves the same level of attention. Some groups have high lifetime value, which is the total revenue a customer is likely to generate over time, so even a small improvement in retention can matter a lot. Other groups may be large but low-margin, which means they are better suited to automation than one-to-one outreach. When should you focus on a segment first? Usually when the behavior is valuable, the pattern is clear, and the action is realistic enough for your team to sustain.
This is also where we connect segments back to the rest of the business. Sales teams may use the segments to spot upgrade opportunities, support teams may use them to identify customers who need extra care, and product teams may use them to understand which features keep people engaged. A segment is not only a marketing label; it is a shared language that helps different teams read the same customer story. When customer segmentation analytics is working well, it reduces guesswork across the company, not just inside one dashboard.
Of course, none of this works if we treat the first plan as permanent. Customers change, seasonality shifts, and new acquisition channels bring in different behavior, so we need to test whether the action actually moved the metric we cared about. That means tracking response rate, repeat purchase rate, retention, average order value, or whatever outcome fits the segment’s goal. In practice, the best customer segmentation analytics creates a loop: observe, act, measure, adjust.
So the most valuable habit is not building the perfect segment once; it is building a rhythm around it. We read the behavior, choose a response, watch what happens, and then refine the segment or the strategy if the results surprise us. That is how insights turn into growth strategy, because the data stops sitting in a report and starts guiding real decisions. With that loop in place, the next question becomes less about what the customers are and more about how to keep improving the experience they receive.



