Map Sources and Data Flows
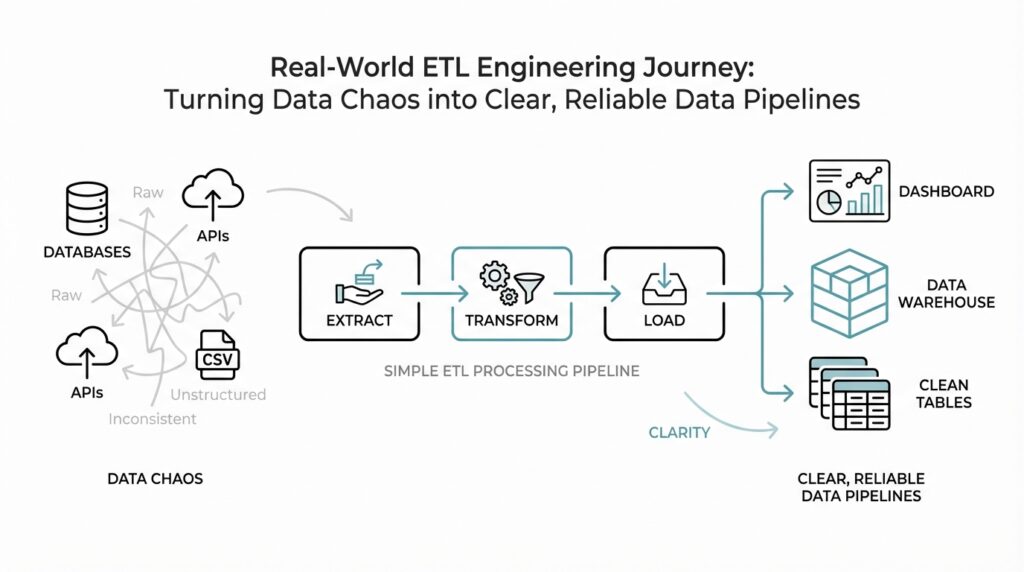
Building on this foundation, we now step into the part of ETL engineering where the real map begins to take shape. Imagine you have a dozen doors in front of you, each leading to a different room full of data: a sales database, a payment system, a marketing platform, and a spreadsheet someone updates every Friday. Before we can build reliable data pipelines, we need to know which room holds which facts, how those facts move, and where they are supposed to end up. How do you know which source feeds which report, and what happens to the data in between? That question sits at the heart of source mapping and data flow design.
The first thing we do is name the source systems clearly. A source system is the original place where data is created, such as an application database, a software-as-a-service tool, or a file drop from a partner. This matters because ETL engineering gets messy when we treat every input as the same kind of input. A customer table in a transactional database behaves very differently from a CSV file emailed by a vendor, so we write down not only where the data comes from, but also who owns it, how often it changes, and whether it is trustworthy enough for downstream use. That simple inventory becomes the beginning of a solid ETL map.
Once the sources are visible, we trace the path each dataset follows. Think of this like following water through a plumbing system: you want to see where it enters, which pipes split it apart, where it gets filtered, and which taps receive it at the end. In a data flow, that means identifying the extract step, the transformations that clean or reshape the data, and the load step that places it into a warehouse, lake, or analytics model. This is where lineage, the record of where data came from and how it changed, becomes useful because it helps us explain every handoff instead of guessing later. When something looks wrong in a dashboard, lineage lets us retrace the path instead of wandering through the dark.
Now that we can see the route, we need to describe the shape of the movement itself. Some data flows are batch-based, which means they move on a schedule, like every hour or every night. Others are near real-time, which means they arrive quickly after the source changes. The difference matters because it affects freshness, cost, and how much pressure we place on source systems. If a finance report depends on a nightly load, we can plan around that delay; if a fraud alert depends on fresh transactions, we need a faster path and tighter monitoring. This is one of the most practical choices in ETL engineering, because the wrong timing can make even a well-built pipeline feel broken.
As we discussed earlier in the broader pipeline story, consistency is just as important as speed. That is why we document transformations alongside the flow itself, not as an afterthought. For example, one source may store dates as text, another may use time zones differently, and a third may repeat the same customer in several records. When we map the flow carefully, we can see where deduplication, standardization, and joining happen, and we can explain why a source field does not always appear unchanged in the final table. This kind of ETL engineering discipline turns hidden logic into shared understanding, which makes collaboration between analysts, engineers, and business users much smoother.
A good map also reveals weak spots before they become incidents. If one source is maintained by a partner team, we may need a service-level agreement, which is a written expectation for freshness and availability. If another source changes without warning, we may need schema monitoring, which watches for changes in columns, types, or structure. These details can feel small at first, but they are the difference between a pipeline that survives real-world change and one that keeps surprising everyone on Monday morning. When we map sources and data flows with this level of care, we are not just drawing boxes and arrows; we are building the shared understanding that lets the whole system stay reliable.
Profile and Clean Raw Data
Building on the map we already drew, we now stop at the next natural question: what does the raw data actually look like once it arrives? This is where raw data profiling in ETL engineering begins, and it feels a bit like opening a suitcase after a long trip. You may know who packed it and where it came from, but you still need to check whether the clothes are folded, whether anything is missing, and whether the contents match the label. Before we transform anything, we inspect the raw material so we can trust the work that follows.
Raw data profiling is the practice of scanning a dataset to understand its shape, quality, and oddities before we clean or load it. In plain language, we are asking questions like: How many rows are here? Which columns have missing values? Do the dates look consistent? Are there duplicate records, impossible values, or text fields that really should be numbers? This step matters because data rarely arrives in a neat classroom example. Real-world ETL engineering often starts with messy spreadsheets, inconsistent timestamps, and fields that mean one thing in one system and something slightly different in another.
That first look gives us more than curiosity; it gives us control. When we profile raw data, we learn which problems are harmless noise and which ones need immediate attention. A null value, which means an empty or unknown field, may be perfectly normal in one column and a warning sign in another. A duplicated customer record might be a simple export glitch, or it might reveal that two systems are recording the same person in different ways. With raw data profiling, we are not guessing blindly. We are collecting clues before we decide how to clean the data.
So how do you clean raw data without accidentally damaging it? The answer is to treat cleaning as careful editing, not creative rewriting. We remove extra spaces, standardize date formats, convert text numbers into real numbers, and fix obvious inconsistencies such as “NY” versus “New York” when the meaning is clear. We also deduplicate records when the rules are well defined, because duplicates can inflate counts and distort reports. But we avoid making assumptions that erase important detail, especially when a value could mean different things depending on context. In ETL engineering, preserving the original source data is often as important as producing the cleaned version.
This is also where data cleansing becomes a balancing act between precision and practicality. If we clean too little, downstream analytics will inherit confusion and errors. If we clean too aggressively, we may hide useful information or merge records that should have stayed separate. That is why many teams keep the raw layer untouched and create a cleaned layer beside it, rather than overwriting the original feed. Think of it like keeping the ingredients on the counter while you prepare the meal. You can wash, chop, and season what you need, but the original ingredients remain available in case you need to check the package again.
Once the cleaning rules are in place, we document them as part of the pipeline, not as tribal knowledge sitting in someone’s head. This documentation matters because the same raw data will not always arrive in the same condition. A vendor may add a new column, a source system may change a code value, or a file may suddenly contain blank rows where it did not before. When we pair raw data profiling with data cleansing, we create a repeatable habit: inspect first, clean with purpose, and record what changed. That habit turns ETL engineering from a rescue mission into a dependable process, and it gives the next transformation stage a solid starting point.
Design Transformations and Business Rules
Building on this foundation, we now step into the part of ETL engineering where raw data starts becoming meaningfully useful. This is the moment when we design transformations, which are the steps that reshape data from its original form into something a warehouse, dashboard, or model can work with. Think of it like turning a pile of grocery ingredients into a meal: the ingredients are still there, but we now decide what gets chopped, mixed, measured, and cooked. How do you know which changes belong in the pipeline and which ones should be left to the source system or the analyst? That question is where business rules enter the story.
A business rule is a decision the company wants applied consistently to its data, such as how to define an active customer, how to calculate revenue, or when to exclude a record from reporting. In ETL engineering, these rules matter because two teams can look at the same raw table and reach very different answers if they do not share the same definitions. For example, one team may count an order as revenue when it is placed, while another may only count it after payment clears. The transformation layer is where we turn those decisions into repeatable logic instead of letting every report invent its own version of the truth.
Taking this concept further, we usually split transformations into small, understandable moves rather than one giant block of logic. We may standardize values first, such as turning different spellings of the same state into one consistent code, then calculate derived fields, which are new values computed from existing ones, such as profit margin or customer age. After that, we might join datasets together, which means combining records from two sources based on a shared key like customer ID or order ID. Each step does one job, and that matters because readable ETL engineering is easier to test, easier to debug, and much easier to explain when someone asks why a number changed.
This is also where business rules stop being abstract and start shaping the actual pipeline design. Suppose a subscription company wants to treat a trial user as a customer only after the first payment succeeds. That rule affects filtering, aggregation, and even the timing of downstream reports. If we build the transformation without writing the rule down first, we may end up with a dashboard that looks polished but answers the wrong question. In contrast to the previous approach, where we mainly inspected and cleaned data, we are now deciding what the data should mean once it enters the analytical world.
A good way to think about ETL transformations is to imagine a careful editor working through a draft. The editor does not change the author’s voice at random; they fix structure, clarify meaning, and apply style rules so the final piece is consistent and readable. ETL engineering follows the same pattern. We might remove invalid records, map coded fields to human-friendly labels, or convert timestamps into a single time zone so reporting lines up across regions. We are not erasing the source; we are making the data usable while preserving the logic that explains every change.
Of course, not every rule is obvious on first sight, and that is what makes this stage tricky. Some rules come from finance, some from operations, and some from the product team, so we often need to ask where the truth should come from before we encode it. Should canceled orders disappear entirely, or should they remain visible with a status flag? Should returns reduce revenue immediately, or only after approval? These questions are not technical decorations; they are the heart of reliable ETL engineering, because the wrong rule can quietly distort every downstream metric.
Once the rules are agreed on, we document them in the pipeline itself and in plain language for the people who depend on the data. That documentation becomes a shared contract, which means future changes are less likely to break hidden assumptions. It also gives us a clean handoff to the next stage, because well-designed transformations make later validation much easier. When the logic is clear, the pipeline feels less like a mystery box and more like a system we can trust, extend, and explain.
Handle Incremental Loads and CDC
Building on this foundation, we reach the moment when the pipeline has to stop acting like a one-time delivery truck and start behaving like a careful courier. New data keeps arriving, old records keep changing, and some rows even disappear, so incremental loads and change data capture become the tools that keep ETL engineering efficient and trustworthy. Instead of rereading everything every time, we focus on what changed since the last run. That shift matters because it saves time, lowers cost, and keeps the source systems from feeling like they are being shaken awake every hour.
An incremental load is the practice of loading only new or changed records since the previous run. Think of it like reading the last page of a diary instead of starting from page one each morning. In contrast to a full refresh, where we pull the entire dataset again, incremental loads use a marker called a watermark, which is a saved point in time or sequence that tells us where we left off. That marker might be an updated_at timestamp, an auto-incrementing ID, or another field that moves forward in a predictable way. Once that idea clicks, the rest of the design becomes easier to picture.
How do you know which rows belong in the next incremental batch? We usually compare source records against the last successful watermark and select anything newer than that point. This works well when the source system reliably records when a row changed, but it can get tricky when clocks drift, timestamps update late, or backfilled data arrives after the fact. That is why incremental loads need careful rules for late-arriving data, because a record that looks old on paper may still be the newest version of the truth. In ETL engineering, the real challenge is not only moving data, but moving the right data at the right time.
This is where change data capture, often shortened to CDC, enters the story. Change data capture means recording inserts, updates, and deletes as they happen so downstream systems can follow the source more closely. If incremental loads are like checking a mailbox for today’s letters, CDC is more like receiving a running feed of every message that gets dropped in, edited, or removed. Some CDC methods watch database transaction logs, which are the system’s internal record of changes, while others rely on timestamps or triggers that fire when a row changes. Log-based CDC is especially useful because it can capture changes with less pressure on the source application.
Taking this concept further, CDC helps us keep analytical tables aligned with operational systems without constantly rebuilding everything from scratch. When a customer updates their email address, places a new order, or cancels a subscription, the pipeline can apply that change as an upsert, which means insert the row if it is new or update it if it already exists. Deletes matter too, because a row that disappears in the source should not keep showing up forever in the warehouse. Without CDC, those small changes can quietly drift apart, and a dashboard may start telling a story that no longer matches reality.
Incremental loads and CDC solve similar problems, but they are not identical. Incremental loads are often simpler to implement when the source offers a trustworthy timestamp and the data volume is manageable. CDC is usually a better fit when freshness matters, when updates and deletes must be captured precisely, or when the dataset is too large for repeated full scans. The choice is less about which method sounds more advanced and more about which one matches the shape of the source system. A good ETL pipeline feels calm because the method matches the problem.
As we discussed earlier with raw data profiling and cleaning, the pipeline still needs protection after the data changes are captured. We often keep a state table, which is a small tracking table that remembers the last processed watermark or offset, so reruns stay consistent and idempotent, meaning safe to repeat without duplicating results. That same habit helps when a job fails halfway through, because we can replay only the missing changes instead of starting over blindly. This is one of the hidden strengths of mature ETL engineering: the system remembers where it stood, even when the world around it keeps moving.
Once the new rows and updates land, we still validate them against the source, because speed without accuracy only creates faster mistakes. We check row counts, compare totals, and watch for unexpected gaps in the change stream so we know the pipeline captured what it was supposed to capture. Over time, that discipline turns incremental loads and CDC from a technical trick into a dependable rhythm. And once that rhythm is in place, we can move on to the next challenge: making sure those changing records land in a model that stays consistent as business rules evolve.
Orchestrate Reliable Pipeline Runs
Now that the pipeline knows how to move only the right changes, we face the next real-world problem: how do we make all those steps happen in the right order, at the right time, without someone babysitting every run? This is where orchestration tools, which are systems that coordinate tasks and dependencies, become the quiet conductor behind reliable pipeline runs. In ETL engineering, orchestration is less about doing the data work itself and more about making sure every extract, transform, and load step happens when it should, with the right inputs, and with a clear path to recovery if something goes wrong.
Think of it like cooking a full meal with several burners, a timer, and a list of dishes that depend on one another. You would not plate the dessert before the oven finishes, and you would not start the sauce until the ingredients are prepped. A pipeline run works the same way: one job may need a source extract to finish before a transformation starts, and that transformation may need to succeed before a warehouse load begins. When we use orchestration for ETL engineering, we are turning that sequence into a repeatable plan instead of relying on memory or manual triggers.
So what does a reliable run actually need? First, it needs a scheduler, which is the part that starts work on a time-based or event-based cadence. Then it needs dependency management, which means one task waits for another task to finish before moving forward. It also needs retries, which are automatic re-attempts after a temporary failure, because network hiccups and locked tables are part of normal life, not rare disasters. When these pieces work together, pipeline runs feel calm even when the system underneath them is busy.
Reliability also depends on making each task safe to repeat. That is where idempotency, meaning the ability to run the same operation more than once without creating duplicate results, becomes essential. If a load job fails after writing half the rows, we do not want the rerun to double-count records or overwrite good data with partial output. We want the pipeline to recover cleanly, and that usually means writing checkpoints, tracking state carefully, and designing tasks so they can resume from a known point instead of starting over blindly.
Here is where orchestration gets practical for day-to-day ETL engineering. A good pipeline run does not end when the final table loads; it ends when the system confirms the data looks right. That is why teams add validation steps, which are checks that compare row counts, required fields, totals, or freshness against expectations. If a source feed arrives late, or a downstream table has fewer rows than expected, the orchestration layer can pause, alert, or stop later tasks before bad data spreads farther.
Alerting matters just as much as scheduling. When a job breaks at 2:00 a.m., the goal is not to wake someone up for every harmless delay, but to surface the problems that actually need attention. A missing file, a failed dependency, or a sudden schema change should create a clear signal with enough context to act on. In mature ETL engineering, orchestration gives you that early warning system, which is far better than discovering the problem when a dashboard looks wrong the next morning.
Backfills are another reason orchestration matters. A backfill is a rerun of historical data for a past time window, often because logic changed or a source issue left a gap. Without a careful orchestration plan, backfills can collide with normal daily runs and create duplicate records, conflicting updates, or unnecessary load on the source systems. With the right controls in place, though, you can replay a missed week, isolate the affected partitions, and keep the rest of the pipeline moving normally.
When all of this comes together, reliable pipeline runs start to feel less like a series of fragile commands and more like a well-rehearsed routine. The scheduler keeps time, the dependency graph keeps order, the validation checks guard quality, and the retry logic gives the system a second chance when the world gets messy. That same structure is what lets ETL engineering scale from a handful of scripts into a process you can trust on ordinary days and stressful ones alike.
Add Validation, Alerts, and Logging
Building on this foundation, we now add the safeguards that keep a pipeline from quietly drifting off course after it has been orchestrated. Validation, alerts, and logging are the three signals that tell us whether ETL engineering is healthy, uneasy, or in trouble. If orchestration is the conductor, these are the sheet music checks, the stage manager’s warnings, and the notebook that remembers what happened. Without them, a run can finish on time and still deliver the wrong answer.
Validation is the first checkpoint, and it works like a careful hand at the door asking, “Does this data look like what we expected?” In practice, data validation means checking rules such as row counts, required fields, allowed values, freshness, and simple totals before bad data moves any farther downstream. For example, if yesterday’s sales feed usually contains 50,000 rows and today it suddenly contains 200, we want that difference to stand out immediately. This is why ETL engineering treats validation as a guardrail, not a nice-to-have, because a fast pipeline that accepts broken input is still broken.
How do you decide which checks matter most? Start with the rules that protect business meaning, not the ones that merely look tidy. A customer table may tolerate blank middle names, but it should probably not tolerate missing customer IDs or negative order amounts. A payments feed may need a freshness check because a late file can affect reporting, while a reference table may need a schema check, which is a test that confirms the columns and data types still match what the pipeline expects. Taking this concept further, strong validation turns hidden assumptions into explicit tests, and that makes ETL engineering far easier to trust.
Once validation can tell us something is off, alerts tell the right people in time to act. An alert is an automatic warning sent when a pipeline crosses a threshold or fails a rule, and it should point to the problem with enough context to investigate quickly. Think of the difference between a smoke detector and a loud bang in the kitchen: one is designed to warn you early, while the other means the damage may already be done. In a mature data pipeline, alerts should focus on the events that need human attention, such as missing source files, failed loads, stalled jobs, or a sudden drop in incoming records.
That balance matters because too many alerts can become background noise, and noisy alerts are easy to ignore. We want the pipeline to speak clearly, not constantly. A good alert tells you what failed, where it failed, when it failed, and how severe the issue is, so you do not waste time hunting through three different systems just to understand the basics. In ETL engineering, alerting works best when it is tied to validation, because a failed check should create a useful signal rather than a vague panic.
Logging is the third piece, and it gives the pipeline a memory. Logs are timestamped records of what the job did, what inputs it saw, what outputs it produced, and what errors it encountered along the way. If validation tells us “something is wrong,” logs help us answer, “where did it go wrong and why?” We often record the start and end time of each task, row counts before and after transformation, source file names, exception messages, and a correlation ID, which is a tracking label that ties events from one run together.
This is where ETL engineering becomes much easier to support in real life. When a dashboard looks off, logs let you trace the story backward: the source arrived late, the validation failed, the alert fired, and the transformation never loaded the final table. That sequence is far more useful than a cryptic failure message with no context. With good logging, we can also compare normal runs against unusual ones, which helps us spot patterns like repeated retries, growing latency, or a specific source that keeps changing shape.
Taken together, validation, alerts, and logging create a safety net that keeps the pipeline honest. Validation checks the data, alerts call attention to the problems we should not miss, and logging preserves the evidence we need to debug and improve the system. When these three work together, pipeline observability stops feeling abstract and starts feeling practical: you can see what happened, understand why it happened, and decide what to do next before a small issue becomes a larger one.



