Define Relevance and Recall Goals
Building on this foundation, the next step is to decide what you actually want the retrieval system to do for you. In a retrieval-augmented generation (RAG) system, a similarity threshold is the cutoff that decides whether a retrieved chunk is close enough to the user’s question to be trusted. If that bar is too low, you invite weak matches and increase the chance of AI hallucinations; if it is too high, you may reject useful evidence and leave the model guessing. So before tuning any numbers, we need to define two goals that often pull in different directions: relevance and recall.
Relevance is about quality. It asks, “Does this passage truly help answer the question?” Think of it like sorting books in a library: a relevant result is the book you would actually hand to a reader, not one that merely shares a few words with the request. In similarity thresholds for RAG systems, relevance means the retrieved text should be semantically close enough to the query that the language model can use it without stretching, guessing, or filling in missing facts. When we talk about reducing hallucinations, relevance is usually the first guardrail we care about.
Recall is about coverage. It asks, “Did we find all the useful evidence we needed?” That sounds a little less glamorous, but it matters just as much. Imagine searching for a recipe and finding one perfect instruction page, but missing the one line that tells you the oven temperature; the answer is incomplete even though part of it was relevant. In RAG, recall measures how often the system surfaces at least one good chunk among all the possible good chunks. If recall is too low, the model may answer with partial context, which can also lead to hallucinations because the missing piece forces the model to improvise.
The real challenge is that these two goals often compete. A stricter similarity threshold improves relevance because it filters out noisy matches, but it can hurt recall by throwing away borderline passages that still contain valuable clues. A looser threshold improves recall because it casts a wider net, but it can flood the model with near-misses, duplicates, or tangential material. How do you set a similarity threshold when both sides matter? The answer is to define which mistake is more expensive in your use case: a false positive, where you retrieve something misleading, or a false negative, where you miss something useful.
That tradeoff becomes clearer when you tie it to the task itself. If you are building a customer support assistant, relevance may matter more because a confident but wrong answer can frustrate users fast. If you are building a research helper, recall may deserve more weight because the user would rather see a broader set of candidate passages than miss an important source. In other words, the right threshold is not a universal number; it is a policy decision shaped by the job your RAG system is trying to do.
Once you define those goals, you can measure them in plain language before you measure them in code. Relevance tells you whether retrieved context looks genuinely useful to a human reviewer, while recall tells you whether the system is finding enough of the answer space to support the model. A practical way to think about this is to ask: would I trust this chunk if I had to answer the question myself, and did I get enough chunks to feel confident I am not missing the key fact? Those two questions keep the tuning process grounded in real outcomes instead of abstract scores.
With those goals in mind, similarity thresholds stop being a mysterious knob and become a deliberate filter. You are not trying to make every retrieved result perfect; you are deciding how much uncertainty your RAG system can tolerate before it starts to drift into hallucination. That framing gives you a stable starting point for tuning, testing, and comparing different thresholds against the balance of relevance and recall that your application actually needs.
Choose a Similarity Metric
Building on this foundation, the next question is not where to draw the line, but what ruler to use in the first place. A similarity metric is the rule your RAG system uses to compare a user’s question with a stored chunk of text, and that choice shapes every similarity threshold you set afterward. If the ruler is a bad fit, even a carefully tuned threshold can produce weak matches or miss good evidence, because the system is measuring closeness in the wrong way. So when we ask how to reduce hallucinations, we need to start by choosing a similarity metric that matches the kind of meaning we want the system to recognize.
In practice, most RAG systems work with embeddings, which are number lists that represent text in a machine-readable form. Think of an embedding like a map coordinate: two passages with similar coordinates are usually similar in meaning, even if they do not share the same words. The similarity metric is the method we use to compare those coordinates. That may sound like a small technical detail, but it is a foundational one, because the metric decides whether your search behaves more like a careful editor or a sloppy keyword matcher.
How do you choose a similarity metric when the same query can look close in one scale and distant in another? The three names you will see most often are cosine similarity, dot product, and Euclidean distance. Cosine similarity checks whether two vectors point in the same direction, which makes it useful when you care more about meaning than raw size. Dot product also measures alignment, but it can be influenced by the length or magnitude of the vectors, which sometimes helps and sometimes creates noise. Euclidean distance measures straight-line distance between vectors, which feels intuitive if you imagine points on a graph, but it can behave differently from the other two when vector lengths vary.
For many RAG systems, cosine similarity is the safest starting point because it focuses on semantic direction rather than vector magnitude. That makes it a good fit when you want the similarity threshold to reflect “does this passage mean the same thing?” instead of “does this passage have a large embedding?” If your application uses normalized embeddings, cosine similarity and dot product can end up behaving very similarly, which is why people sometimes discuss them together. The important part is not memorizing formulas; it is understanding that the similarity metric should match the shape of the embedding space your model produces.
This is where a practical mindset helps. If you are building a support assistant that needs to find the most relevant policy paragraph, a metric that rewards semantic closeness usually gives you cleaner retrieval and fewer misleading near-misses. If you are working with a model or vector database that already expects a specific metric, then matching that expectation matters more than personal preference. In other words, the best similarity metric is the one that fits your embeddings, your retrieval engine, and your tolerance for false matches. A similarity threshold only makes sense once those pieces agree on what “close” actually means.
Before you settle on a metric, it also helps to test it against real queries, not just synthetic examples. A passage can look similar on paper and still feel wrong to a human reviewer, especially if it shares a topic but not the exact intent behind the question. That is why we compare retrieved chunks side by side and ask whether the metric is surfacing the kind of evidence a person would trust. When the ranking feels natural, your similarity threshold becomes much easier to tune, because the underlying similarity metric is already pointing in the right direction.
So the goal here is not to find a perfect mathematical answer. It is to choose a similarity metric that makes your RAG system behave predictably, then use that stability to keep hallucinations in check. Once that foundation is set, the threshold becomes a true control knob instead of a guessing game, and we can move on to shaping the cutoff itself with far more confidence.
Set the Initial Threshold
Building on that foundation, the next move is to pick a starting point for your similarity threshold that gives you room to learn. You are not trying to solve the whole tuning problem on day one; you are creating a first filter that is strict enough to keep weak evidence out, but not so strict that your RAG system starves. In practice, the best initial threshold is a conservative one, because hallucinations often begin when the retriever becomes too generous and starts feeding the model material that only looks relevant at a glance.
So how do you choose that first cutoff without guessing in the dark? Start by thinking of the threshold as a gatekeeper at the door of your answer pipeline. If the gate opens too easily, the model sees too many near-misses, and those fuzzy matches can push it toward confident but incorrect answers. If the gate barely opens at all, you may end up with too little context, which is another path to hallucinations because the model fills in the blanks on its own. The initial threshold should therefore lean toward precision first, then recall later, because it is easier to relax a threshold after review than to explain why the system accepted noisy context from the start.
A practical way to set the first threshold is to sample a small set of real user questions and inspect the retrieved chunks by hand. This step matters because similarity scores can look tidy on a dashboard while still feeling wrong to a person reading the text. Ask yourself whether the top passages would make sense to you if you had to answer the question directly, and note where the retrieved context starts drifting from the user’s intent. If a chunk feels vaguely related but not genuinely helpful, that is a sign your threshold is probably too low for a RAG system that needs to reduce hallucinations.
It also helps to remember that the best initial threshold depends on the score scale your vector search engine returns. Some systems expose similarity as a higher-is-better score, while others expose distance as a lower-is-better value, so the number itself matters less than the behavior it creates. If your retrieval setup uses cosine similarity, for example, you are usually looking for a cutoff that keeps clearly aligned passages and excludes softer thematic matches. The exact number is less important than the principle: choose a value that makes the retriever behave like a careful editor, not a broad-topic browser.
This is where your use case starts to shape the decision. If your RAG system supports customer support, legal summaries, or medical-style guidance, you usually want a stricter starting threshold because the cost of a misleading chunk is high. If your system is a brainstorming assistant or a research explorer, you may tolerate a looser first pass because breadth can be more useful than narrow certainty. What causes hallucinations in one setting may look different in another, which is why the initial threshold should reflect the consequences of being wrong, not just the raw similarity score.
Once you set that first cutoff, write down what it is protecting you from. That note becomes your tuning compass when the results start to feel uneven, because you can compare real outcomes against the original goal instead of changing the number at random. If the model still receives too many shaky passages, raise the bar a little and test again. If it misses obvious evidence, lower the threshold in small steps and watch whether recall improves without opening the door to noisy matches.
The important thing is to treat the initial threshold as a working hypothesis, not a final truth. You are giving your RAG system its first rule for deciding what counts as trustworthy context, and that rule will only become better through observation. With a thoughtful starting point in place, you can move into testing and adjustment with more confidence, because the similarity threshold is already doing the main job it was meant to do: keeping hallucination-prone context from slipping through unnoticed.
Filter Low-Score Chunks
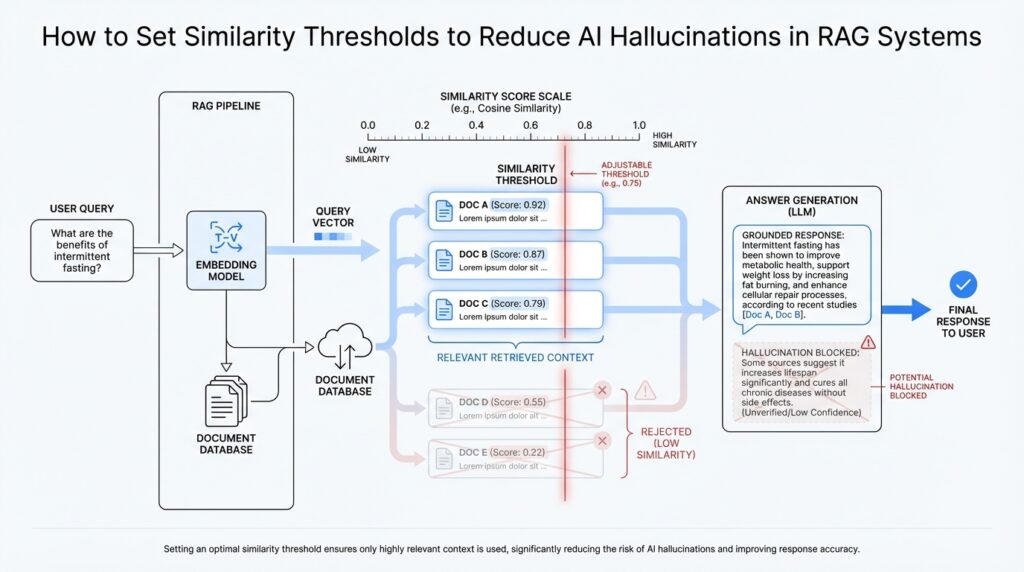
The moment you start filtering low-score chunks, the retrieval pipeline feels less like a noisy crowd and more like a careful conversation. A chunk is a small passage cut from a larger document, and low-score chunks are the ones that barely resemble the user’s question. They are risky because they can look close enough to sneak past a casual glance, but not close enough to support a trustworthy answer. When you filter them out early, you give your RAG system a cleaner set of clues and a much better chance of avoiding hallucinations.
This matters because not every retrieved passage deserves a seat at the table. Some chunks match only a keyword, some share the right topic but the wrong intent, and some are simply remnants of broader text that happened to land near the query in vector space, which is the mathematical space where embeddings live. If you let those weak matches through, the model may treat them as evidence anyway, and that is where a confident-sounding mistake often begins. How do you reduce AI hallucinations in RAG systems without starving the model of context? One of the most effective moves is to remove low-score chunks before generation ever starts.
The cleanest way to think about this is to imagine a bouncer at a venue. The bouncer does not need to know whether every guest is perfect; the job is to keep out the people who clearly do not belong. A similarity threshold plays that role for retrieval, and the low-score filter is the moment where we enforce it. Anything below the cutoff gets dropped, even if it appears in the top results, because “ranked highly” and “good enough to trust” are not the same thing.
That distinction becomes especially important when the query is broad or ambiguous. A search for “refund policy” might return chunks about billing, cancellations, chargebacks, and account closure, but only one of those may actually answer the question the user asked. Low-score filtering helps us avoid feeding the model a pile of nearly relevant text that encourages it to stitch together an answer from fragments. In a RAG system, that kind of stitching is dangerous, because the model can sound organized while quietly inventing the missing pieces.
You can make this filter more useful by thinking in terms of both absolute score and relative distance from the best match. A chunk with a mediocre score may still be worth keeping if every other result is equally weak, because that tells you the query itself may need clarification rather than stricter filtering. On the other hand, if one chunk scores clearly higher and the rest fall off sharply, the low-score group is probably clutter rather than evidence. That pattern is one of the clearest signals that your similarity threshold is doing its job well.
It also helps to watch for a common trap: filtering so aggressively that you leave the model with almost nothing. At that point, the system may answer from memory instead of context, which brings hallucinations back through the side door. So we are not trying to delete every imperfect chunk; we are trying to remove the ones that are weak enough to mislead. In practice, that means keeping a small number of strong passages, dropping the low-score tail, and making sure the remaining context still covers the user’s intent.
Once that cleanup happens, the next step becomes much easier. The model now receives passages that are more likely to agree with the question, which makes its answer more grounded and less dependent on guesswork. That is the real value of filtering low-score chunks: it turns retrieval into a focused handoff instead of a messy dump of text, and it gives the rest of the RAG pipeline a much steadier foundation to work from.
Test With Retrieval Evaluation
Building on this foundation, the next question is the one that turns tuning into proof: how do you know your similarity threshold is actually helping your RAG system? Retrieval evaluation is the practice of checking retrieval results against real examples so you can see whether your cutoff is keeping useful evidence in and noisy evidence out. Think of it like taste-testing a recipe after changing one ingredient; you are not guessing whether the dish improved, you are comparing the result against something you already trust. In RAG systems, that trust comes from seeing whether the retrieved chunks still support the answer instead of nudging the model toward hallucinations.
The best place to start is with a small set of questions that reflect how people really use the system. We often call this a golden set, which means a carefully chosen group of test queries with known good answers or known good source passages. A golden set does not need to be huge at first; it needs to be honest. If your app answers support questions, include messy customer phrasing, not only polished search terms. If it summarizes internal documents, include questions that ask for dates, exceptions, and overlapping policies, because those are the places where similarity thresholds tend to matter most.
Once you have those test questions, we can look at the retrieved chunks one by one and ask a human-friendly question: would I trust this context if I were answering the user myself? That review step is the heart of retrieval evaluation, because it tells you whether your threshold is filtering out weak matches or accidentally removing the one passage that actually matters. A good test is to compare the top results from a looser threshold and a stricter threshold side by side. When the stricter version removes obvious distractions but still keeps the key evidence, you are moving in the right direction for reducing hallucinations in RAG systems.
This is also where simple metrics become useful, as long as we treat them like guideposts rather than verdicts. Precision means how many retrieved chunks are actually relevant, while recall means how many of the useful chunks you managed to find. If your threshold is too low, precision usually drops because the retriever brings in more weak passages. If your threshold is too high, recall can suffer because you miss evidence that was helpful even if it was not a perfect match. A strong retrieval evaluation checks both, because a system that finds the wrong evidence quickly can be just as misleading as one that finds almost nothing.
Now that we understand the basic scorecard, the next step is to test the threshold against real failure modes, not just average performance. This is where borderline questions become especially valuable. Ask queries that are intentionally vague, queries with overlapping terms, and queries where the answer lives in a short, specific sentence buried inside a longer document. Those are the cases where a similarity threshold can look fine on easy examples but still let hallucination-prone context slip through. If the model starts sounding more certain while the evidence gets weaker, that is a sign the retrieval layer is giving it too much room to improvise.
A practical retrieval evaluation also includes disagreement, and that is a good thing. If one reviewer says a chunk is useful and another says it is too vague, you have found a threshold boundary worth studying. Those disputed cases often reveal whether your RAG system is being too strict or too permissive. Instead of trying to force perfect agreement immediately, keep a record of these edge cases and see how they behave across different thresholds. That pattern tells you more than a single average score, because it shows you where the system becomes fragile.
The real goal of retrieval evaluation is not to crown one magical number. It is to create a feedback loop where the threshold, the retrieved chunks, and the final answer all get checked against the same standard: does this context help the model stay grounded? When you test that loop with real questions, you stop tuning in the dark and start making decisions with evidence. That is what turns a similarity threshold from a guess into a controlled way to reduce hallucinations, one reviewed query at a time.
Tune Thresholds Per Query Type
Building on this foundation, the next step is to remember that not every question deserves the same similarity threshold. A RAG system often behaves like one reader with many moods: sometimes the user wants a precise fact, sometimes they want a broad explanation, and sometimes they are only trying to narrow down what to ask next. How do you tune a similarity threshold when the query itself keeps changing shape? The answer is to stop thinking in terms of one universal cutoff and start thinking in terms of query type, because different questions create different risks for hallucinations.
The easiest way to see this is to separate questions by intent. A direct request like “What is our refund window?” usually needs a stricter threshold, because the best supporting chunk should match the policy language very closely. A broader question like “Why are customers asking for refunds?” may need a looser threshold, because the model needs a wider set of clues to build a useful answer. Think of it like choosing a flashlight beam: a narrow beam helps when you already know exactly where to look, while a wider beam helps when you are still scanning the room. If you use the same beam for both, one of them will feel wrong.
That is why query routing matters. Query routing means recognizing the shape of the question before retrieval, then applying a matching retrieval rule. You do not need a complicated system to begin with; even a simple split between exact, exploratory, and ambiguous questions can make a big difference. Exact queries usually benefit from a higher similarity threshold because you want strong semantic agreement and fewer near-misses. Exploratory queries can tolerate a lower threshold, but they often need extra guardrails, like a reranker or a smaller set of returned chunks, so the model does not drown in loosely related text.
Ambiguous queries deserve special care, because they often look harmless while hiding the biggest hallucination risk. A user might ask, “Can I change it?” and the system has no idea whether “it” means a booking, an address, or a plan. In cases like that, a very strict threshold can leave the retriever with almost nothing, but a very loose one can feed the model a confusing mix of possibilities. This is where you may want the system to pause and ask a clarifying question instead of forcing a guess. Sometimes the safest similarity threshold is the one that tells the system to stop and gather more context.
It also helps to tune thresholds alongside the user’s intent rather than in isolation. For a support assistant, query types tied to policy, billing, or account changes should usually lean stricter because a wrong answer creates immediate frustration. For a research assistant, questions that ask for background, comparisons, or brainstorming may benefit from a broader net, because the user cares more about coverage than about a single exact passage. In other words, the right threshold is not only about text similarity; it is about the kind of answer the user expects and the cost of getting that answer wrong.
Once you start thinking this way, the tuning process becomes much more practical. You can review real logs, label the question types, and see where the RAG system succeeds or fails for each group. If exact questions keep pulling in weak matches, raise the threshold for that class. If exploratory questions keep coming back empty, lower the threshold a little or let the system retrieve more candidates before filtering. That pattern is what makes similarity thresholds for RAG systems feel manageable: you are no longer chasing one magic number, but shaping the retrieval behavior to fit each kind of question.
The goal here is consistency, not perfection. When the threshold matches the query type, the retriever stops fighting the user’s intent and starts supporting it, which gives the generator cleaner evidence and fewer chances to improvise. With that in place, we can move from one-size-fits-all filtering toward a more adaptive approach that reacts to the question in front of us.



