What Is Token Classification
Imagine you feed a sentence to a model and ask it to mark what each piece means. That is the heart of token classification: a natural language processing task where we assign a label to each token in a text, one token at a time. A token can be a full word, but it can also be a smaller piece created by a tokenizer, which is why this task feels a little more detailed than plain text classification. It is the technique behind familiar jobs like named entity recognition, part-of-speech tagging, and chunking.
How do you teach a model to do that without getting lost? First, we break the sentence into tokens, then we give each token a tag from a fixed label set, much like putting a colored sticker on every bead in a necklace. In many token classification setups, labels use a scheme such as B, I, and O, where B means a chunk begins, I means it continues, and O means the token does not belong to any chunk. That labeling pattern is what lets a model learn where one meaningful span ends and another begins.
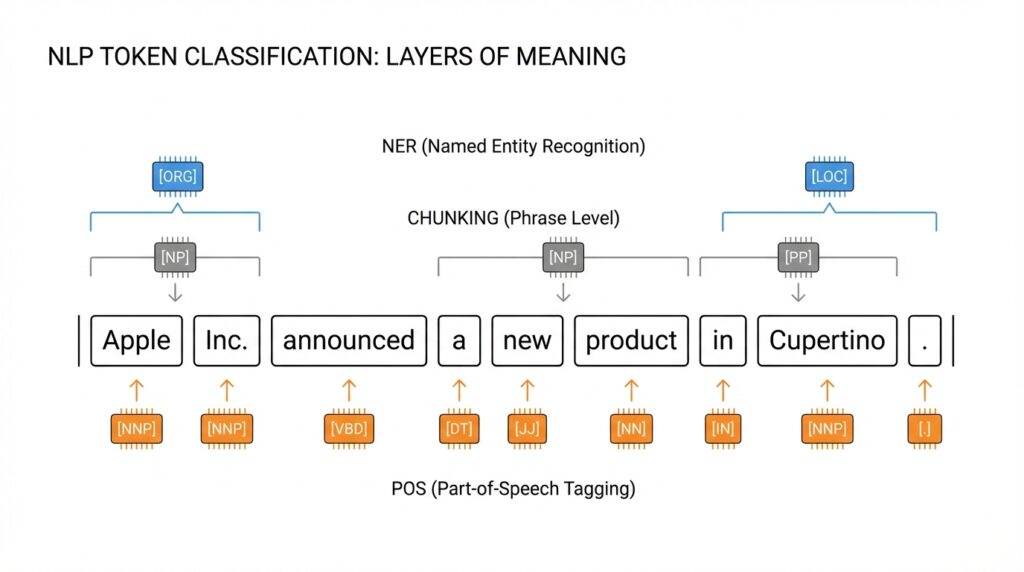
This is where the familiar subtasks start to feel distinct. Named entity recognition, or NER, teaches the model to spot things like people, locations, and organizations inside a sentence. Part-of-speech tagging, or POS tagging, labels grammar roles such as noun, verb, adjective, or punctuation, so the model can tell how a word is being used in context. Chunking goes a step further by grouping neighboring tokens into phrases, which is helpful when you want the model to see a sentence as a set of meaningful parts instead of a flat string of words.
A small wrinkle appears when modern tokenizers split a single word into subwords. If a model breaks one word into several pieces, the labels have to stay aligned, or the training signal gets messy. Hugging Face’s token-classification guidance explains that practitioners often give the main label to the first subtoken and ignore the extra subtokens with a special value such as -100 during training. That detail matters because token classification is not only about meaning; it is also about keeping the labels lined up with the exact pieces the model sees.
Why does that matter in practice? Because token classification turns raw text into structured information you can search, filter, count, or route into another system. A customer-support app might use NER to pull names and account IDs from messages, while a language tool might use POS tagging to improve grammar analysis or translation behavior. Libraries like spaCy and Hugging Face expose these tasks directly in their NLP pipelines, which is a good sign that token classification is not an academic side note but a core way machines learn to read with precision.
NER, POS, and Chunking
Building on this foundation, it helps to see token classification as three different ways of reading the same sentence. One view asks, “What real-world thing is this token pointing to?” That is named entity recognition (NER), which spots people, places, organizations, and similar entities. A second view asks, “What grammar job is this token doing?” That is part-of-speech tagging (POS tagging), which labels words like noun, verb, and adjective. A third view asks, “Which neighboring tokens belong together?” That is chunking, which groups tokens into short phrases or spans.
NER is usually the first idea people latch onto because it feels so practical. When a sentence says “New York City” or “Hugging Face,” you do not want the model to treat those tokens as unrelated scraps; you want it to recognize one entity that carries meaning as a unit. In token classification, NER often assigns one label per token, with one class for each entity type and another class for “no entity,” so the model can mark where an entity begins and continues. That is why NER shows up so often in extraction pipelines for search, support, and information routing.
POS tagging feels subtler, but it gives the sentence its grammar skeleton. The same word can play different roles depending on context, and POS tagging helps the model hear that difference instead of guessing blindly. Think of a word like “bank”: in one sentence it may behave like a noun, and in another like a verb, and the tagger captures that shift by labeling each token with its grammatical role. Tools such as spaCy expose POS tagging as a standard pipeline step, alongside tokenization and NER, because later components often depend on those grammatical signals.
Chunking takes the story one step further by turning a line of tokens into small phrase-sized pieces. Instead of asking whether a token is a person or a verb, chunking asks which tokens belong in the same span, such as a base noun phrase. That is where the familiar B, I, and O pattern comes in: B marks the beginning of a span, I marks tokens inside it, and O marks tokens outside it. Hugging Face’s token-classification guidance shows this directly, and NLTK describes chunkers as tools for finding non-overlapping groups in text, typically base syntactic constituents.
Here is where things get interesting: these three tasks are related, but they are not interchangeable. NER cares about identity, POS cares about grammar, and chunking cares about phrase boundaries, so each one answers a different question about the same input. In practice, a single dataset can carry all three label sets, like CoNLL-2003, and a pipeline may use POS tags before or alongside other analyses. spaCy even notes that noun chunks depend on part-of-speech tagging and parsing, which is a good reminder that token classification often behaves like a small chain of clues rather than one isolated prediction.
So how do you tell them apart when you are learning token classification for the first time? A useful shortcut is to ask whether the model is naming, grammatically labeling, or grouping. If it is naming something concrete, you are in NER; if it is explaining a word’s job in the sentence, you are in POS tagging; if it is bundling tokens into a phrase, you are in chunking. Once that distinction clicks, the labels stop feeling like a blur and start looking like three lenses over the same text, which makes the next step—feeding those labels cleanly into a model—much easier to follow.
Prepare Labeled Training Data
Building on this foundation, the next challenge is turning real sentences into labeled training data that a model can actually learn from. If token classification is the lesson, then annotations are the answer key we hand to the model, one token at a time. How do you prepare that answer key without creating confusion? We start by collecting plain text, then we mark each token with the label scheme we want the model to follow, whether that is for NER, POS tagging, or chunking. The important part is consistency: the model learns patterns from repeated examples, so even a small mismatch in labeling can feel like mixed messages during training.
Before anyone starts tagging, it helps to write clear annotation guidelines. These are the rules that tell you what counts as an entity, where a phrase begins, and how to handle tricky cases like punctuation, abbreviations, or names that appear in different forms. Think of guidelines like a recipe shared with a team of cooks: if one person adds salt by eye and another measures carefully, the final dish will not taste the same. In token classification, that same idea shows up when two annotators label the same sentence differently. Good guidelines reduce that drift and make labeled training data more trustworthy.
This is where the label scheme matters in a very practical way. Many projects use a BIO-style setup, where B marks the beginning of a span, I marks the inside of a span, and O means the token is outside any span. For POS tagging, the labels look different, but the same principle applies: every token needs one clear tag, and every tag needs to mean the same thing every time it appears. When you prepare token classification data, you are not only naming things or grouping phrases; you are building a map the model can follow without hesitation. If the map changes shape halfway through, the model will struggle to learn anything stable.
A second wrinkle appears when tokenizers split words into smaller pieces. This happens often with modern models, and it is one of the easiest places for beginners to lose alignment. If one word becomes multiple subword tokens, the labels still need to line up with the original meaning, which is why many pipelines assign the main label to the first subtoken and mark the rest so they do not interfere with training. That step may sound technical, but the idea is familiar: if a name gets split into pieces, we still want the model to recognize it as one name, not several unrelated fragments. Careful alignment is what keeps labeled training data usable instead of noisy.
Once the labels are in place, we still need to think about balance and quality. A dataset for NER that contains only people’s names but no locations or organizations will teach the model a lopsided lesson, and the same problem can happen in POS tagging or chunking if one label appears far more often than the others. We also want to split the data into training, validation, and test sets so we can learn from one part, tune on another, and check our final performance on a third. That separation gives us a more honest view of how well the token classification model will behave on new text.
If you are preparing your first dataset, a good question to ask is: would another person, reading the same guidelines, label this sentence the same way I did? That question catches many problems early. It nudges us to review edge cases, compare samples, and fix inconsistency before training begins. In the end, labeled training data is less like a pile of tags and more like a carefully arranged set of examples that teaches the model how to see structure in language. Once that foundation is clean, the model has a much better chance of learning NER, POS tagging, and chunking in a way that feels reliable rather than random.
Build a Tagging Pipeline
Building on that clean dataset, we can finally turn token classification into a working tagging pipeline. This is the point where the story stops being about labels on paper and starts becoming a system that can read new text, one token at a time. How do you build a token classification pipeline that keeps NER, POS tagging, and chunking aligned from raw sentence to final prediction? We move in order: first we split the text, then we match labels to those tokens, then we send everything through the model, and finally we translate the model’s output back into human-readable tags.
The first step is tokenization, which means breaking text into the exact pieces the model will see. That sounds ordinary, but it is the foundation of everything that follows, because the model can only predict labels for tokens it knows about. If the tokenizer splits a word into subwords, our pipeline has to remember which piece owns the label and which pieces are carried along for the ride. In practice, that means building the tagging pipeline around the tokenizer the model was trained with, so the input and the labels stay in the same lane.
Once the tokens are in place, we create a label map, which is a simple lookup table that connects each tag name to a number the model can process. Think of it like a translation card between human language and machine language. This matters because NER labels, POS tags, and chunking tags all live in different label spaces, even though they follow the same overall token classification pattern. When the model sees the sentence, it does not understand “PERSON” or “VERB” directly; it sees IDs, and the label map keeps that translation consistent from training to prediction.
Now we connect the labels to the tokens using alignment. Alignment means making sure each token receives the correct tag, especially when one word becomes several subword tokens. This is where many beginners first feel the friction, because a neat sentence on screen can turn into a slightly messy sequence underneath. The pipeline has to decide whether the first subtoken carries the real label and the rest are ignored, or whether a special scheme is used to share information across pieces. That decision is not cosmetic; it is what keeps token classification training honest.
With aligned inputs and labels, the model can learn patterns through a small classification layer, sometimes called a model head, which sits on top of the main language model. The language model builds a contextual representation, meaning it tries to understand each token by looking at the tokens around it, and the classification layer turns that representation into tag probabilities. In plain language, the model reads the sentence, weighs the context, and chooses the most likely label for each token. This is the heart of a tagging pipeline, because it transforms language understanding into structured output.
Training is where the pipeline starts to behave like a dependable tool rather than a clever demo. We feed it many labeled examples, compare its predictions with the true tags, and use that gap to improve the model step by step. For token classification, evaluation matters just as much as training, because accuracy alone can hide weak spots. A pipeline for chunking may look strong overall but still miss span boundaries, while an NER pipeline may find entities but attach the wrong label to the first token. That is why we test on held-out data and inspect a few examples by hand.
After training, the final step is decoding, which means turning the model’s numeric predictions back into readable tags and spans. This is where the pipeline becomes useful for real applications, because you can now extract names from support tickets, part-of-speech information from text analysis, or phrase chunks from an input sentence. The same tagging pipeline can also power clean downstream systems, such as search, analytics, or content routing, because it turns free text into organized structure. Once that path is in place, token classification stops feeling abstract and starts acting like a repeatable process you can trust.
Train the Sequence Model
Building on the pipeline we just assembled, we can now train the sequence model that actually learns the token classification patterns. This is the moment where all those aligned labels, tokenized inputs, and label maps start working together like a lesson plan for a very patient student. How do you train a sequence model so it can recognize names, grammar roles, and phrase boundaries without getting confused? We feed it many labeled examples, compare its guesses with the correct tags, and adjust its internal weights, which are the numbers that control how strongly the model responds to patterns it sees in text.
At the start, the model knows almost nothing useful about your task, so training looks a lot like guided correction. Each sentence goes through the tokenizer, the sequence model makes a prediction for every token, and then a loss function, which is a score that measures how wrong the prediction is, tells us how far off the model was. Think of that score like a classroom red pen: the model does not need a lecture, it needs a clear signal about which guesses were helpful and which were not. In token classification, that signal has to stay aligned with the exact tokens the model saw, especially when words split into subwords.
Once that flow is in place, we train in batches, which means we group several examples together before updating the model. Batching helps the process run efficiently and also smooths out noise, because one sentence can be unusual while a small group gives the model a steadier picture of the task. You will usually hear about epochs too, and an epoch is one complete pass through the training dataset. In practice, sequence model training often needs several epochs before the model stops stumbling over obvious cases and starts recognizing the repeating shapes in your labels.
This is where beginners often notice that the model can learn too quickly or too broadly. If it memorizes the training set instead of learning general patterns, it is overfitting, which means it performs well on the examples it has already seen but poorly on new text. To watch for that, we keep a validation set, which is a separate slice of labeled data used for tuning, not for teaching. When validation performance stops improving while training performance keeps climbing, the model may be learning the answers instead of the lesson, and that is a useful warning sign rather than a failure.
Transfer learning makes this stage much friendlier. Instead of training a language model from zero, we often start with a pre-trained model, which is a model that has already learned broad language patterns from large text collections. Then we fine-tune it, meaning we adapt it to our token classification task with our labeled data. That is like taking a skilled reader and showing them the specific color code for NER, POS tagging, or chunking. The model already understands language structure, so the sequence model training only has to teach it your label scheme and your domain.
While the model learns, we also need to pay attention to imbalance in the data. If one tag appears far more often than the others, the model can become lazy and favor the common label because it feels safe. To prevent that, we may rebalance examples, inspect rare classes more closely, or watch per-label metrics instead of relying on one overall score. Metrics are measurements of performance, and in token classification they often include precision, recall, and F1 score, which together tell us whether the model is accurate, complete, and balanced in its predictions.
As we discussed earlier, the labels must stay lined up with the tokens, and training is where that alignment either proves itself or falls apart. If the sequence model predicts the right entity type but only on half of a split word, the result can look correct at a glance while still being unusable downstream. That is why we test real examples after training, not only aggregate numbers. We want to see whether the model can handle messy, ordinary text, because that is the kind of language it will meet outside the lab.
By the time the model is trained, you are no longer looking at raw text and hoping for structure. You are looking at a learned system that can trace patterns across sentences, repeat them reliably, and return token-level predictions that feel grounded in the input. That is the practical reward of sequence model training: it turns the earlier setup work into a tool that can read with context, not just guess word by word.
Evaluate and Improve Results
Building on this foundation, the real question becomes: how do you know whether your token classification model is actually helping? Once the model starts predicting NER, POS tagging, or chunking labels, we need a way to look past the excitement and see what it is doing well, what it is missing, and where it is quietly guessing its way through the sentence. This is why evaluation matters so much in token classification: it turns a promising training run into something we can trust, improve, and explain.
The first thing we usually check is whether the model is learning the right lesson from the right data. Accuracy can look impressive and still hide problems, especially when one label like “O” appears far more often than the others. That is why precision, recall, and F1 score are so useful here. Precision tells us how many predicted tags were correct, recall tells us how many real tags the model found, and F1 score balances those two views so we do not overrate a model that is either too cautious or too noisy. For token classification, that balance matters more than a single headline number.
Now that we understand the basic scorecard, we can look deeper than the average. A model might do well on person names in NER but stumble on organizations, or it might recognize verbs in POS tagging while repeatedly confusing adjectives and adverbs. That is where per-label evaluation helps. Instead of asking, “Did the model do well overall?” we ask, “Which labels are carrying the weight, and which ones are falling behind?” This kind of breakdown often reveals the hidden shape of the problem, especially when the dataset contains rare entity types or phrases that appear only a few times.
Here is where error analysis becomes the most human part of the process. We read a handful of mistakes and look for patterns, much like a teacher reviewing a student’s marked-up homework. Did the model miss the first token of a chunk because the boundary was unclear? Did it split a multiword entity in the wrong place? Did subword tokenization make the alignment messy again? These are the questions that show us whether the problem comes from the data, the labels, or the model itself. In chunking, for example, a boundary error can be more important than the label type, because one misplaced tag can break the whole span.
Once we spot the pattern, improvement stops feeling mysterious. Sometimes the fix is better data, such as more examples of rare labels or cleaner annotation guidelines. Sometimes the fix is model-side, like lowering the learning rate, adding early stopping, or choosing a stronger pre-trained model that already understands language structure. And sometimes the fix is a pipeline issue, especially when the tokenizer and labels are not perfectly aligned. If the model keeps failing on the same kind of split word or phrase, that is often a sign that the input representation needs attention before the model can improve in a meaningful way.
A useful habit is to compare validation results with test results and watch for a gap. If the model looks strong on the validation set but weaker on the test set, it may have learned the quirks of the training process instead of the broader pattern. That is not a dead end; it is a clue. It tells us to revisit the dataset split, check for label imbalance, and inspect whether the training examples are too similar to one another. In token classification, the best improvements usually come from a mix of cleaner data, clearer labels, and a model that is being asked to learn one honest pattern at a time.
As we discussed earlier, token classification is really about turning language into structure. Evaluation shows us whether that structure is stable, and improvement gives us a path to make it sharper. The more carefully we inspect mistakes, the more the model starts to feel less like a black box and more like a tool we can shape. That is the point where NER, POS tagging, and chunking become not only tasks we can train, but systems we can refine with confidence.



