Why Leaderboards Mislead
If you have spent time looking at AI leaderboards, it is easy to feel like the answer is sitting right there in a neat ranking. The model at the top looks like the safest bet, the next one looks close enough, and the rest seem to fall neatly into place. But once you move from the chart to real work, that neatness starts to crack, because large language models are not competing in a vacuum—they are competing inside your task, your constraints, and your expectations.
That is the first reason leaderboards mislead: they turn a living, messy problem into a single number. A benchmark score is a little like a test grade in school. It tells you something useful, but it does not tell you whether the student can lead a project, explain an idea to a customer, or notice a mistake in a draft that looks fine on paper. How do you know whether a model is actually good for your job? You have to ask what the score is measuring, and what it is quietly leaving out.
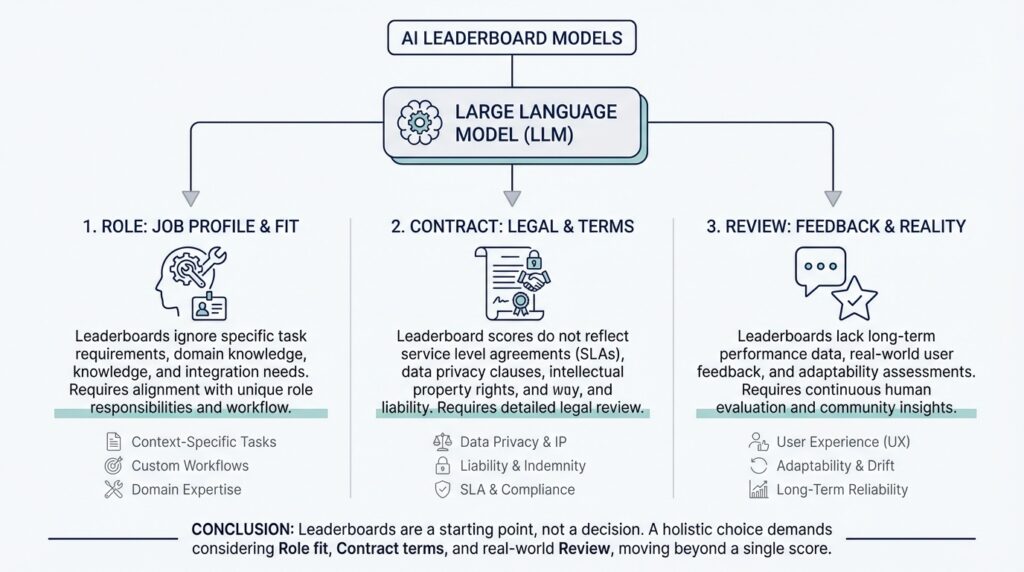
This is where the idea of role matters. A role is the job you want the model to play, such as a brainstorming partner, a customer support assistant, a data extractor, or a careful editor. One model may shine when you want broad, creative answers, while another may be far better when you need strict formatting and exactness. AI leaderboards usually flatten all of that into one general-purpose ranking, which makes it look as if every task rewards the same behavior. In practice, the model that wins a leaderboard may be the wrong choice for the role you actually need.
Now let us take a step deeper and talk about the contract. A contract is the set of promises your system needs from the model: speed, cost, privacy, tone, output length, and even how often it should say “I do not know.” Think of it like ordering food for a group. The best-rated restaurant on the street is not automatically the best choice if it is too expensive, too slow, or cannot handle allergies. In the same way, a model can top AI leaderboards and still fail your contract because it is costly to run, too slow for live use, or too verbose for a small interface.
Leaderboards also hide the difference between a model that looks smart and a model that is reliably useful. A benchmark often rewards the model that gets the expected answer on a carefully designed test set, but real work is full of awkward edges: incomplete prompts, unusual inputs, ambiguous instructions, and users who want different things from the same response. That is why a large language model can score well and still stumble when the conversation becomes messy. The leaderboard tells you how it performs under test conditions, not how it behaves when your users start improvising.
This is where review becomes essential. Review means having humans inspect real outputs from the model and judge whether they fit the task, the audience, and the rules you care about. A review can catch the kinds of failures that a benchmark misses, like a polite answer that still invents facts, a technically correct answer that sounds wrong for your brand, or a fast response that breaks your formatting contract. In other words, review brings the model back into the world where people actually use it.
So the problem is not that leaderboards are useless; the problem is that they are incomplete. They can help you narrow the field, but they cannot tell you whether a model fits your role, honors your contract, or survives human review in the real setting you care about. Once you see that gap, the ranking stops feeling like a verdict and starts feeling like a starting point, which is exactly the shift we need before we choose a model with confidence.
Define the Job Role
Building on this foundation, the next question is not which model looks strongest on paper, but what job you are asking it to do. A well-defined job role is the model’s assignment in your system: the specific kind of work it must carry out, the kind of user it serves, and the kind of output that counts as success. When people compare large language models, this step is often skipped, and that is where confusion begins. How do you choose a model if you have not first decided whether you need a patient tutor, a fast support agent, or a careful data checker?
The easiest way to understand a job role is to think of it like casting a part in a play. One actor can be brilliant in a dramatic scene and awkward in a comic one, even though both performances are “good” in different ways. A model works the same way: a brainstorming role rewards creativity and range, while a document-review role rewards precision, restraint, and consistency. If you blur those roles together, AI leaderboards start to look more decisive than they really are, because they rank models without showing you which kind of performance you actually need.
Taking this concept further, the job role also tells you what the model should not do. A role is not only a task description; it is a boundary. For example, a support assistant should answer clearly, stay on topic, and know when to escalate, while a research assistant might be expected to explore possibilities and surface alternatives. Those are different kinds of usefulness, and they demand different behaviors from the model. Once you define the role this way, you can see why a model that wins a benchmark may still feel wrong in practice: it may be too chatty, too cautious, too narrow, or too willing to improvise.
This is where the role connects directly to the contract we discussed earlier. The contract says what the system must promise, such as speed, cost, tone, or privacy, but the role says what work the model is actually there to perform. In other words, the role gives the contract a target. A customer service role may require warm, brief answers, while a data extraction role may require rigid formatting and almost no creative freedom. When the role is clear, you can judge large language models against the right expectations instead of asking one model to be excellent at everything.
A good role definition also makes evaluation much more honest. Instead of asking, “Is this model smart?” you start asking, “Did it behave like the worker we needed in this situation?” That shift sounds small, but it changes everything. It helps you notice whether the model can follow instructions, stay within scope, and produce output that a human can trust without rewriting. It also gives reviewers a shared standard, which makes human review more useful because everyone is judging the same job, not their own personal idea of what the model should have done.
Once you start naming the role clearly, the leaderboard loses some of its magic and gains something more useful: context. You stop treating the ranking as a universal answer and start treating it as one clue among many. That is the real payoff of defining the job role: it turns a vague comparison into a concrete decision, and it gives you a way to match the model to the work instead of hoping the work matches the model.
Set Contract Requirements
Building on this foundation, the next step is to turn a vague preference into a clear set of contract requirements. If the role says what the model is doing, the contract says what the model must promise while doing it. That promise can include response time, cost per request, privacy limits, output format, tone, and how carefully the model should avoid guessing. When people compare large language models only through AI leaderboards, they often miss this part entirely, even though it is the part that decides whether the model can survive real use. How do you know whether a model is a fit if it cannot meet the basic rules of your system?
Think of a contract like the instructions you give a delivery driver before a long trip. You do not only care that the driver reaches the destination; you care whether the package arrives on time, stays sealed, and follows the right route. The same idea applies here. A model might be impressive in a benchmark, but if it takes too long to respond, costs too much to run at scale, or sends back answers in the wrong format, it breaks the contract even when the content looks good. For many teams, that is the moment when AI leaderboards stop being useful and the contract starts becoming the real decision tool.
This is where contract requirements become concrete. If you are building a customer support assistant, you may need short replies, a calm tone, and a strict rule that the model should escalate uncertain cases instead of inventing answers. If you are building a data extraction workflow, you may need exact field names, no extra commentary, and near-perfect consistency from one request to the next. Those are not small preferences; they are requirements that shape the model’s job from the ground up. A model that writes beautifully but ignores formatting is a poor fit for one contract, while a more restrained model may be exactly right.
Now we can see why the contract matters so much in practice. It gives you a way to compare large language models against the realities of your system, not just the elegance of a benchmark. A model with a high score on AI leaderboards may still be the wrong choice if it exposes sensitive data, drifts in tone, or cannot stay within your latency budget, which is the maximum acceptable delay before a user gets a response. In other words, the contract turns abstract quality into operational quality. It asks not, “Is this model capable?” but “Can this model behave well inside our rules, every day, at our scale?”
A good contract also protects you from hidden surprises. Without one, teams tend to judge models by the most memorable answer instead of the most dependable behavior. One model may sound polished, another may be faster, and a third may be cheaper, but those strengths only matter if they line up with the promises you actually need. That is why the best way to choose among large language models is to define the contract before you compare the scores. Once the requirements are clear, AI leaderboards become a helpful clue instead of a misleading finish line.
When you start this way, you also make later review much more meaningful. Reviewers are no longer asking whether the model seems good in a general sense; they are checking whether it honored the contract you already wrote down. Did it stay within the word limit? Did it avoid unsupported claims? Did it keep the right tone for the user facing the answer? Those questions are much easier to answer when the contract is specific. And that is the real shift: once the requirements are set, you stop evaluating models as if they were interchangeable and start judging them by whether they can keep their promises in the world you built for them.
Build a Review Process
Building on this foundation, the next move is to create a review process that tells you how the model actually behaves in your hands. This is where large language models stop being abstract winners on AI leaderboards and start becoming tools you can inspect, compare, and trust. How do you know whether a model is right for your role and contract if you never look at real outputs? You need a repeatable way to watch the model work, notice what it gets right, and catch the mistakes that a score alone will never reveal.
A good review process starts small, with examples that feel close to the real world. Think of it like tasting a dish before serving it to guests: you are not trying to judge the whole restaurant, only whether this recipe works for the people at your table. Pick a handful of prompts that reflect your actual use case, then compare the model’s answers side by side. You want to see whether it follows instructions, stays in scope, and produces output that a human would be comfortable using without heavy editing.
Taking this concept further, the best review process does not ask a vague question like “Is this answer good?” It asks a set of focused questions that match your contract. Did the model stay within the expected tone? Did it avoid unsupported claims? Did it return the right format? Did it know when to say it was unsure? Those questions matter because a model can sound confident and still fail your needs in quiet ways, especially when it is doing something as delicate as customer support, summarization, or data extraction.
It also helps to separate review into two kinds of judgment. First, there is task review, where you check whether the output solves the problem. Then there is policy review, where you check whether the output respects the rules you set. A model might answer the question correctly but still break your privacy boundary, and another might be safe but too vague to be useful. When you review both sides together, you get a much clearer picture of whether the model can survive real production use.
As we discussed earlier, human review is what pulls the model back into the messy world where real users live. That means you should involve the people who understand the work best, not just the people who understand the model. A support lead will notice tone problems that a spreadsheet cannot, while an analyst will notice when a response is technically clean but operationally wrong. This is why a review process is so valuable: it turns personal intuition into shared criteria, so the team is not arguing over impressions but checking the same expected behavior.
Once you have that rhythm, you can start comparing large language models with much more confidence. The leaderboard still has a place, but now it acts like a map, not a verdict. Your review process tells you whether the model can actually carry the role, honor the contract, and behave consistently under real conditions. And once that becomes the habit, the conversation shifts from “Which model ranks highest?” to “Which model keeps its promises when it matters?”
Test Real Use Cases
Building on this foundation, we now move from theory into the place where model choice becomes real: your own workflows. This is where AI leaderboards start to lose their shine, because a model that looks strong on paper can still feel clumsy when it meets the exact work you need done. If you have ever wondered, ‘How do you know whether a model will actually work for my team?’, the answer is to test real use cases, not just benchmark-style prompts.
The best place to start is with the tasks your users already do every day. Think of these as the scenes in the story where the model has to perform under pressure: answering a customer, summarizing a report, extracting fields from messy text, or drafting a short reply in the right tone. Each of those tasks reveals something different about large language models, because the same model can sound impressive in one situation and awkward in another. When you test real use cases, you are not asking whether the model is clever in general; you are asking whether it can do the job in your environment.
That distinction matters more than it first appears. A leaderboard often rewards broad skill, but real work rewards fit. For example, a model that writes rich, detailed answers may be a poor match for a support flow that needs short responses and strict escalation rules. Another model may be less flashy but better at staying inside a template, which is exactly what a data extraction process needs. This is why testing large language models in your own scenarios gives you better signal than comparing scores alone: you see the model under the same constraints your users will face.
Now that we understand the idea, the next step is to make the test feel like the real world, not a classroom exercise. Use prompts that include the messiness people actually bring: incomplete questions, vague wording, mixed priorities, and occasional errors in the source material. A clean demo can hide problems, but a realistic test usually reveals them quickly. You might notice that one model handles polished input beautifully while another stays calm when the prompt is unclear, which is often the more valuable skill in production.
It also helps to test more than one example of the same task. Real use cases are rarely one-note, so you want a small collection of situations that reflect the range of your workflow. A summarizer, for instance, should be tested on a short note, a long report, and a badly organized draft. A support assistant should be tested on a simple question, a frustrated user, and a case that needs escalation. This kind of testing shows you whether the model is reliable or merely lucky on a single sample.
Taking this concept further, you should watch for the small failures that a benchmark never highlights. Does the model keep the right tone when the conversation gets tense? Does it stay within the format you asked for when the input becomes noisy? Does it admit uncertainty when the answer is unclear, or does it drift into confident guesses? These details sound minor until they reach real users, and then they become the difference between a tool people trust and a tool they quietly stop using. Testing real use cases makes those failures visible before they become expensive.
This is also where human judgment earns its place. A reviewer can tell you whether the answer feels useful, whether it matches the role, and whether it honors the contract you defined earlier. That human check is especially important when you are comparing large language models that all sound competent at first glance. In practice, the best choice is often the one that performs consistently on your actual tasks, not the one that wins the most impressive-looking ranking.
When you test real use cases, you shift from asking which model looks best to asking which model behaves best where it matters. That is the point where AI leaderboards stop acting like a final verdict and start acting like a rough first pass. And once you have that mindset, the next step is much easier: you can compare models by how they perform in the work you truly care about, not by how they perform in someone else’s test room.
Make the Final Choice
Building on this foundation, the final choice starts to feel less like picking the best model and more like choosing the right partner for a very specific job. By this point, AI leaderboards have already done their narrow job: they helped you spot a few promising candidates. Now the question becomes: how do you choose between large language models when the top scores no longer settle the matter? You do it by weighing the role, the contract, and the review results together, instead of letting any one signal pretend to be the whole story.
The cleanest way to think about this moment is as a short, careful tradeoff conversation. One model may be the strongest writer, another may be the safest, and a third may be the fastest to respond. None of those strengths are meaningless, but they only matter inside the job you defined earlier. If your role needs precise extraction and your contract demands strict formatting, the model that sounds the smartest may still be the wrong pick, while the quieter one that follows instructions more faithfully becomes the better choice.
This is where a simple decision frame helps. First, ask whether the model fits the role you named. Then ask whether it honors the contract requirements you set, such as cost, latency, tone, privacy, and output shape. Finally, ask whether human review showed that it behaves consistently on real examples, not just polished test cases. When those three answers line up, you are no longer choosing on instinct; you are choosing with evidence.
That evidence often reveals an important truth: the best model is rarely the one that wins every category. In real systems, you may accept a slightly weaker benchmark score if the model is cheaper, steadier, or easier for reviewers to trust. On the other hand, you may pay more for a model that handles ambiguity with care because the cost of a mistake is high. This is why the final choice is less about searching for perfection and more about finding the model whose strengths match the consequences of your use case.
A practical question can help you sort through the last round of hesitation: what failure would hurt you most if this model were wrong? If the answer is slow responses, then speed matters more than a tiny gain in reasoning quality. If the answer is hallucinated details, then caution and reviewability matter more than fluency. If the answer is brand trust, then tone and consistency may outweigh raw capability. Once you name the failure that matters most, the decision stops feeling vague and starts feeling grounded.
Taking this concept further, the final choice should also leave room for the world to change. Large language models improve, prices shift, product needs evolve, and user expectations move with them. That means your decision is not a forever verdict; it is the best answer for the current role, current contract, and current review evidence. In practice, the smartest teams do not treat AI leaderboards as a one-time purchase guide. They treat them as one input inside a living selection process that can be revisited when the workload changes.
So when you reach the end of the comparison, resist the urge to crown a universal winner. Choose the model that fits the work you actually have, the promises you can actually keep, and the review process that shows you how it behaves in real use. That is the point where large language models stop being abstract rankings and start becoming dependable tools. And once you make decisions that way, the next improvement is easier to see: you are no longer asking which model is highest on the chart, but which one will keep proving itself where it matters most.



