What Embeddings Are
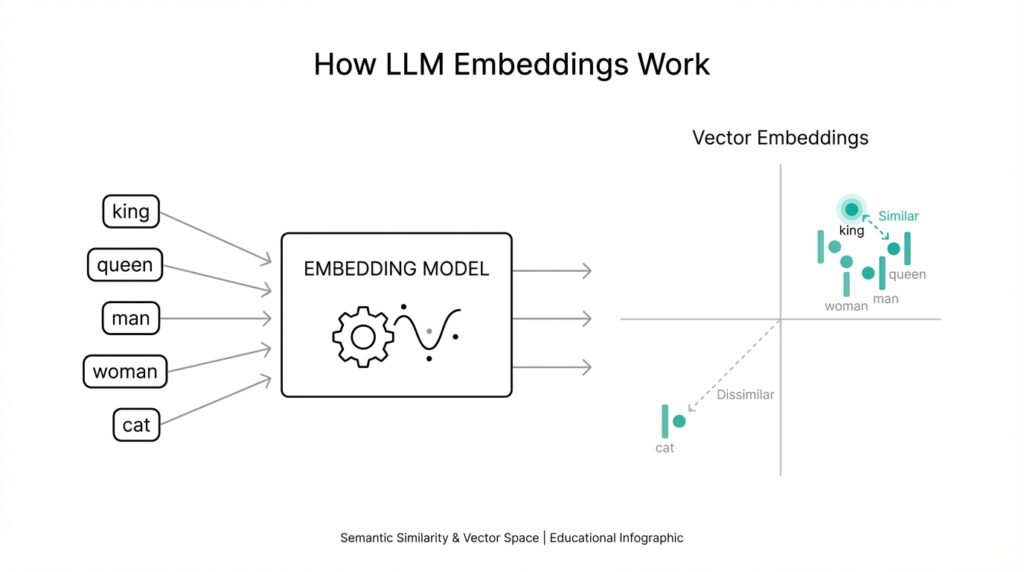
Imagine you ask a model a question like, “How do embeddings help a computer understand meaning?” and it seems to answer in the right neighborhood even when the exact words change. That little bit of magic comes from embeddings, which are numerical representations of words, phrases, or even whole documents. In plain language, an embedding turns something messy and human, like language, into a vector—a list of numbers—that a machine can work with. Building on this foundation, we can think of embeddings as a map where similar ideas end up near each other.
That map idea is the easiest way to picture what embeddings are doing. Instead of treating every word like an isolated label, an embedding gives each word a position in a high-dimensional space, which means a space with many directions, not just the two you see on paper. If two words mean related things, their vectors land close together; if they are unrelated, they end up farther apart. So “cat,” “kitten,” and “dog” might sit in one neighborhood, while “banana” lives somewhere else entirely.
This is where embeddings feel different from older word representations. A plain word list is like giving every item its own locker number: useful, but not very expressive. An embedding is more like a GPS coordinate, because it carries hints about meaning, usage, and relationship to other words all at once. In machine learning, that matters because models can use those coordinates to detect patterns, compare concepts, and generalize beyond exact wording. If you have ever wondered, “Why does the model understand that ‘car’ and ‘vehicle’ are related?” embeddings are a big part of the answer.
Now that we understand the shape of the idea, let’s see what those numbers actually buy us. When a model reads text, it does not see words the way you do; it sees vectors, and vectors are easy to measure, combine, and compare. A vector representation is powerful because distance and direction can encode meaning in a way raw text cannot. For example, the vector for “Paris” may be close to “France” and far from “banana,” which gives the model a useful sense of context before it ever predicts the next word or retrieves a document.
Taking this concept further, embeddings are not only for single words. Modern systems often create embeddings for sentences, paragraphs, images, or product descriptions, which lets the model compare larger chunks of meaning. Think of it like summarizing a whole paragraph into a compact mental note rather than memorizing every sentence. That compact note is not a perfect copy of the original text, but it keeps the important signals, which is why embeddings work so well for search, recommendation, clustering, and retrieval tasks. The same idea applies whether you are matching a user query to a document or grouping similar articles together.
One detail that often feels tricky at first is that embeddings are learned, not hand-written. During training, a model adjusts the numbers so that useful relationships become easier to spot, much like a musician slowly tuning an instrument until the notes sound right together. That means the embedding for a word is not fixed by nature; it depends on the data and the task the model learned from. In other words, embeddings are a learned language of coordinates, and once you start reading that language, the rest of machine learning feels much less mysterious.
What makes embeddings so valuable is that they let us move from exact matching to meaning-based matching. Instead of asking whether two pieces of text are identical, we can ask whether they are close in vector space, which is a far more flexible question. That shift is the heart of many modern AI systems, and it is why embeddings show up everywhere from chat search to semantic retrieval. Once that idea clicks, the next step is to explore how models create these vectors and why their geometry matters so much.
Text to Vectors
Building on this foundation, we can now follow the path from raw words to a machine-readable vector representation. That shift starts with a question many beginners ask: How do you turn a sentence into numbers without flattening its meaning? The answer is that a model does not memorize text as a string of characters; it breaks the text into pieces, studies the relationships between those pieces, and then places the result into a numerical space where meaning can be measured. This is the heart of text to vectors, and it is where embeddings become practical rather than abstract.
The first step is usually to split text into tokens, which are small units such as words or word fragments. Think of tokens like the ingredients in a recipe: before we can cook anything, we need to separate the parts we are working with. Once the model sees those pieces, it converts each one into a set of numbers that reflects patterns it learned during training. In other words, the model is not asking, “What does this word look like?” It is asking, “What role does this token usually play in language, and what tends to appear near it?”
From there, the model builds a vector embedding, which is a list of numbers that places the text in a high-dimensional space. High-dimensional sounds intimidating, but you can picture it as a map with many more directions than a paper map can show. A short phrase like “rainy day” and a nearby phrase like “stormy weather” may end up with similar vectors because the model has learned that they often carry related meaning. This is why vector representation is so powerful: it lets a computer compare meaning instead of relying on exact wording alone.
As we discussed earlier, embeddings are learned rather than hand-written, and that detail matters here. When a model converts text to vectors, it is using patterns from training data to decide which numbers should sit close together and which should drift apart. That means the same word can land in a different neighborhood depending on context, which is a big improvement over older systems that treated every word as fixed and isolated. So when you ask why the phrase “bank” can mean a financial institution in one sentence and a river edge in another, the vector changes because the surrounding text changes too.
Now that we understand the machinery, it helps to see why this conversion is so useful. Once text becomes a vector, the model can compare two pieces of language with mathematical tools such as distance and similarity. That lets a search system find a helpful paragraph even when it does not share the exact keyword, or lets a recommendation engine group related descriptions that never use the same phrasing. In practice, text to vectors opens the door to semantic search, clustering, retrieval, and other tasks where meaning matters more than matching letters.
There is also a nice side effect: vectors compress a lot of information into a form that is easier for machines to handle. A paragraph of text may be long and messy, but its vector can act like a compact fingerprint that still preserves the important signals. That does not mean the vector is a perfect copy of the original sentence; instead, it is more like a well-drawn map than a photograph. The map leaves out tiny details, but it keeps the routes, landmarks, and relationships that matter most for decision-making.
Taking this concept further, the conversion from text to vectors is the bridge that lets language models move from reading words to reasoning about them. Once the text has been transformed, the model can do useful work with it: compare, cluster, retrieve, rank, and predict. That is why vector representation sits at the center of so many modern machine learning systems. When you understand this step, the rest of the pipeline starts to feel much less mysterious, because you can see how raw language becomes something a model can actually think with.
Embedding Space Basics
Building on this foundation, imagine we have moved from numbers that represent text to the room those numbers live in. That room is the embedding space: a high-dimensional coordinate system where each text gets a position, and nearby positions usually signal related meaning. OpenAI describes embeddings as vector representations in high-dimensional space, with each dimension capturing some aspect of the input. That is why the map analogy works—you are not storing a sentence, you are placing it somewhere meaningful.
The next puzzle is what nearby actually means. Here we lean on a simple idea from distributional semantics: words and phrases that appear in similar contexts tend to receive similar vectors. So doctor and physician cluster together not because the model memorized a dictionary, but because language keeps using them in overlapping neighborhoods. Think of it like learning about people at a party by who they talk to most often.
If you ask how do you compare two embeddings, the answer is geometry. Models often use cosine similarity, which measures how aligned two vectors are, and OpenAI notes that its embeddings are normalized to length 1, so cosine similarity and Euclidean distance rank results the same way. In practice, that means the model can ask whether two meanings point in the same direction, not just whether their raw numbers match. That small shift is what makes embedding space feel so powerful.
This is where clusters become useful. In embedding space, related items tend to form neighborhoods, and those neighborhoods power tasks like semantic search, clustering, and classification. OpenAI’s documentation explicitly ties text-similarity embeddings to clustering, visualization, and classification, while its search guidance shows how embeddings can retrieve relevant documents even when the query and passage do not share keywords. The practical payoff is clear: meaning becomes measurable, so a model can find ideas instead of only matching words.
But we should not treat the space like a perfect truth machine. The same word can land differently depending on context, especially in contextual embeddings, which adapt the representation to the surrounding sentence. Research comparing BERT, ELMo, and GPT-2 found that the same word in different contexts still shares some similarity, but the representation becomes more context-specific as you move through the model. That is why bank can feel financial in one sentence and riverside in another.
One last wrinkle is visualization. We often draw embeddings on a two-dimensional chart, but that picture is only a shadow of a much larger space. Real embedding spaces can have many dimensions, so a flat plot can show only a rough sketch of the relationships. That sketch is still useful—it helps us notice clusters, outliers, and gaps—but we should remember that the full structure lives in higher-dimensional geometry. With that in mind, the next step is to see how models learn that geometry in the first place.
Similarity and Distance
Now that we have a map of embedding space, the next question feels natural: how do we tell whether two points are meaningfully close? This is where similarity and distance become the quiet workhorses of embeddings. Think of it like standing in a city with a compass and a ruler: one helps you compare direction, the other helps you compare separation. In machine learning, those two ideas let us measure whether two pieces of text are likely to mean the same thing, talk about the same topic, or belong in the same neighborhood.
When people ask, “How do you compare two embeddings?”, they are really asking how to turn meaning into a number a model can use. That number comes from a similarity measure or a distance metric, which is a rule for judging how alike or how far apart two vectors are. Similarity says, “These look related,” while distance says, “These are separated by this much.” The nice part is that both ideas point toward the same practical goal: helping the model rank useful matches above weak ones.
The most common similarity measure is cosine similarity, which checks whether two vectors point in the same direction. You can imagine two arrows on a sheet of paper: if they lean the same way, they are similar even if one is longer than the other. That matters because in many embedding systems, the length of the vector is less important than its direction. So when “car” and “vehicle” end up pointing in nearly the same direction, the model reads that as a sign that they live close together in meaning.
Distance metrics tell a related story, but from another angle. Euclidean distance, for example, measures the straight-line gap between two points, like stretching a string between them on a map. If the string is short, the vectors are close; if it is long, they are far apart. In practice, similarity and distance often work side by side, because a small distance usually means high similarity, and a large distance usually means low similarity. That is why vector search systems can sort results by whichever measurement best fits the task.
This idea becomes especially useful when you want meaning-based search instead of exact keyword matching. Suppose a user types “how to fix a slow laptop,” but the document says “speed up an underperforming computer.” The words do not match perfectly, yet the embeddings may land near each other because the underlying idea is the same. That is the real power of similarity and distance: they let the system recognize related meaning even when the surface language changes. In other words, the model stops reading only the spelling and starts reading the signal.
Clustering is another place where this geometry matters. If embeddings for similar items gather into tight groups, a machine can organize articles, products, or support tickets without being told the labels in advance. You can picture it like sorting socks after laundry: items that look and feel alike naturally end up in the same pile. In the same way, vector distance helps the model decide which texts belong together and which ones should stay apart, making similarity and distance useful for both retrieval and grouping.
One small but important wrinkle is that these measurements only make sense relative to the embedding space they come from. A distance of 0.2 in one model may not mean the same thing in another model, because each system learns its own geometry. That is why practitioners usually compare vectors produced by the same embedding model and often rely on ranking rather than raw numbers alone. Once you see that, the numbers stop feeling mysterious: they are not absolute truth, but a practical guide for comparing meaning.
So when we talk about similarity and distance in embeddings, we are really talking about how machines decide which ideas belong together. The model does not need to understand language the way a person does; it only needs a reliable way to measure closeness in vector space. That measurement is what turns embeddings from a neat representation into a working tool, and it sets us up for the next step: how those measurements power retrieval, ranking, and smarter search.
Common LLM Use Cases
Building on this foundation, we can finally answer the practical question that usually comes next: what do embeddings and large language models (LLMs, or large language models) do for you in the real world? The short answer is that they help software work with meaning instead of only matching words. That matters any time you want a system to find the right passage, recommend the right item, or group related ideas together. In other words, the same vector representation that felt abstract a moment ago becomes the engine behind everyday AI features.
The most common place you see this is semantic search, which means searching by meaning rather than exact keywords. How do you find the right answer when the user’s question and the document use different wording? You turn both into embeddings, compare their vectors, and return the closest matches. This is why a query like “How do I reset my account password?” can still surface a help article titled “Recover access to your profile.” The model is not looking for identical phrases; it is looking for nearby ideas in embedding space.
Retrieval is the next natural step, and it is where many modern chat systems become genuinely useful. Retrieval means fetching relevant text before the LLM writes its answer, almost like handing a student the right pages before an exam. This pattern is often called retrieval-augmented generation, which is a mouthful for a simple idea: let the model consult trusted documents instead of relying only on memory. When embeddings power that retrieval layer, the system can pull in the most relevant notes, policies, or product details and then use the LLM to explain them clearly.
Embeddings also shine in recommendation systems, where the goal is to suggest things that feel relevant rather than random. Think of a streaming app, an online store, or a news feed: each item can be represented as a vector, and items with similar vectors can be recommended together. That same logic helps with clustering, which means sorting similar items into groups without labeling them one by one. If you have a pile of customer tickets, research articles, or product descriptions, clustering can reveal hidden patterns that are hard to spot by eye.
Another useful case is classification, which means assigning a label to text based on what it is about. Instead of writing a long rule for every possible phrase, you can use embeddings to capture the meaning of each example and train a simpler model on top. That approach is helpful for spam detection, topic tagging, sentiment analysis, and routing support messages to the right team. The reason it works is the same reason we spent time on vector distance earlier: texts with similar meanings tend to land near each other, so a label can often be predicted from neighborhood patterns.
There is also a quieter but very practical use case: duplicate detection and content matching. Suppose you are cleaning a dataset full of repeated job posts, similar product listings, or near-identical customer questions. Exact text matching will miss many of those duplicates because small wording changes hide the overlap. Embeddings make those similarities visible, which helps you merge records, reduce clutter, and keep your data much easier to work with. That can save both time and money, especially in systems that grow fast.
Once you start seeing these patterns, a bigger picture emerges. Embeddings are not only a feature of LLMs; they are the bridge that lets language models support search, retrieval, recommendations, clustering, and classification in one shared framework. If you have ever wondered, “Why does the same model help answer questions and organize content?” the answer is that vector representations give it a common language for meaning. And with that in place, we can move on to the next layer of the story: how these vectors get stored, searched, and connected to a working application.
Creating Embeddings in Practice
Imagine you are ready to turn a pile of notes, support tickets, or product descriptions into something a machine can compare. This is where creating embeddings in practice begins: you take raw text, send it through an embedding model, and receive a vector representation that captures meaning in numbers. The idea is familiar now, but the workflow matters because real data is messy, long, repetitive, and sometimes oddly formatted. So the first question is not “What is an embedding?” but “How do you prepare text so the model can give you useful vectors?”
The practical journey usually starts with choosing the right embedding model for the job. An embedding model is the part of a system that turns text into vectors, and different models are tuned for different trade-offs, such as speed, cost, and accuracy. If you are building semantic search for a small knowledge base, you may care about fast responses. If you are comparing customer feedback across many categories, you may care more about nuanced meaning. That choice shapes everything that follows, because the model decides how your text will be represented in vector space.
Before you send anything to the model, it helps to clean and shape the text a little. You do not need to rewrite your content, but you do want to remove obvious noise such as duplicate spaces, broken formatting, or stray headers that do not add meaning. If the text is long, you may also need to chunk it, which means splitting one large document into smaller sections. Think of chunking like cutting a long loaf of bread into slices: each slice is easier to handle, and together they still represent the whole loaf.
This step matters because embedding models have limits on how much text they can process at once. If you give a document that is too long, the model may truncate it, which means it cuts off part of the input and silently leaves information behind. That is a real problem when the most important detail sits near the end of a page. A practical fix is to embed smaller passages, then keep track of which passage came from which document so you can reconnect the pieces later.
Once the text is ready, the next move is batching, which means sending several pieces of text through the model at the same time. Batching is like carrying groceries in one trip instead of making ten separate walks; it saves time and makes the process more efficient. After the model returns the vectors, you usually store them in a database, often a vector database, which is a system designed to save and search embeddings efficiently. That storage step is what turns a one-time computation into something your application can actually use.
Now comes the part that makes embeddings feel useful instead of theoretical: testing them with real queries. You take a sentence that represents what a user might ask, create its embedding, and compare it with the embeddings already stored in your collection. If the closest matches look sensible, you are on the right track. If the results feel off, the issue may be the model, the chunk size, the cleanup step, or the way you are measuring similarity. How do you know whether your embeddings are working well? The honest answer is to try real examples and see whether the nearest neighbors make sense to a human reader.
There is one more practical detail that often gets overlooked: different tasks may need different embedding strategies. Short labels, full paragraphs, and mixed-format documents do not always behave the same way, so it is worth experimenting with input length and chunk boundaries. You may also want to normalize vectors, which means scaling them so they are easier to compare consistently. Small choices like these can change search quality more than people expect, especially when your dataset grows and the differences between similar items become subtle.
In the end, creating embeddings in practice is less about a single magic step and more about a careful pipeline. You choose a model, prepare the text, split long passages when needed, generate vectors in batches, and store them where your application can retrieve them later. That workflow is what turns embeddings from a concept into a tool, and it sets the stage for the next part of the story: how those vectors are searched, ranked, and used inside real systems.



