What Tokenization Means in NLP
When you first meet tokenization in NLP, it helps to picture text as a crowded suitcase. A model cannot do much with the whole suitcase at once, so we unpack it into smaller pieces called tokens—often words, punctuation marks, or subword pieces. This is the first step that turns human language into something a computer can count, compare, and learn from, which is why tokenization sits at the front of many NLP pipelines.
The important part is that tokenization is not one fixed rulebook. In English, a token might look like a word or a punctuation mark, but language rules can make the job messier than it first appears. Hyphenated forms, contractions, and languages that do not separate words with spaces all create choices the tokenizer has to make, so tokenization is really a language-aware decision rather than a universal cutting pattern.
That is why libraries exist to handle this work for us. spaCy’s tokenizer takes raw Unicode text and builds Doc objects, which are structured text containers that later NLP tools can work with, while NLTK includes tokenization as one of its core text-processing capabilities. If you are wondering, “What is tokenization in NLP?” the most practical answer is that it is the step that turns a sentence into manageable units for a program.
As we move into modern models, the story gets a little more interesting. Many Transformers use subword tokenization, which means a word can split into smaller pieces instead of being kept whole. Hugging Face documents three major approaches here: Byte Pair Encoding (BPE), WordPiece, and Unigram. This helps models deal with rare words, unusual spellings, and brand-new names without treating each unfamiliar word as an unsolved puzzle.
You can think of this like organizing a drawer of mixed tools. One tokenizer might keep “don’t” together, another might split it into smaller parts, and a subword tokenizer might break an uncommon word into familiar fragments the model has seen before. None of these choices is automatically best for every situation; the right tokenization depends on the language, the task, and how much detail the model needs to preserve.
So when tokenization in NLP comes up, remember that it is more than a technical pre-step. It is the bridge between messy human language and structured machine input, and that bridge can be built in different ways depending on what we want the model to understand. Once we are comfortable with tokens, we are ready to ask the next natural question: how does a model turn those tokens into meaning?
Why Tokenization Matters for Models
Why does tokenization matter for models at all? Because the model never meets your sentence as a smooth stream of human language; it meets a row of tokens and then turns those tokens into token IDs, which are the numbers it can actually process. Hugging Face describes tokenizing as splitting text into words or subwords and converting them to IDs through a lookup table, so tokenization is the step that makes language readable to a model.
That matters because tokenization decides how much the model can recognize with a fixed vocabulary, which is the limited list of tokens it knows. With subword tokenization, common words can stay whole while rare or unfamiliar words break into smaller pieces, giving the model a way to represent new names, misspellings, and odd phrasing instead of leaving them as blanks. In practice, that is a big reason modern models lean on subword schemes such as BPE, WordPiece, and Unigram.
Tokenization also affects how much context a model can carry at once. Since the model spends one slot for each token, a sentence that becomes many small tokens uses up the available space faster than a sentence that stays compact, which means tokenization can change how much of the surrounding text the model sees at the same time. That is why the same sentence can feel longer or shorter to a model depending on the tokenizer, even though the human reader sees the same words.
There is another quiet job tokenization performs: it gives the model signposts. Hugging Face’s tokenizer tools can add special tokens, which are extra markers such as start, end, or sentence-pair boundaries, before the text goes into the model. Those markers help the model tell where one sequence begins and another ends, which is especially useful when we ask it to classify text or compare two passages.
This is also why tokenization is not a throwaway preprocessing trick. A model is trained to expect a specific token pattern, so if we change the tokenizer, we change the exact sequence of IDs the model receives. Even small shifts in segmentation can change how the model lines up what it learned with what it sees at inference time, which is why the tokenizer is usually treated as part of the model stack rather than a separate convenience step.
So when you think about tokenization in NLP, picture a translator standing at the doorway between messy text and machine logic. It does not decide the meaning for us, but it decides the form in which meaning becomes visible to the model, and that form shapes everything that follows. Once we have that bridge in place, the next question is how the model turns those tokens into representations it can learn from.
Word, Subword, and Character Tokens
Once we see that pattern, the bigger picture becomes easier to hold onto. Tokenization is not one fixed recipe, and the difference between word, subword, and character tokens changes how a model reads, remembers, and generalizes. In other words, the tokenizer is doing more than packing text into smaller boxes; it is deciding the size of the pieces the model will learn from. That is why the same sentence can look simple to us but land very differently inside a machine. And now that we have seen the pieces at different sizes, we are ready to follow how those pieces turn into numerical representations the model can actually learn from.
Common Tokenization Methods Explained
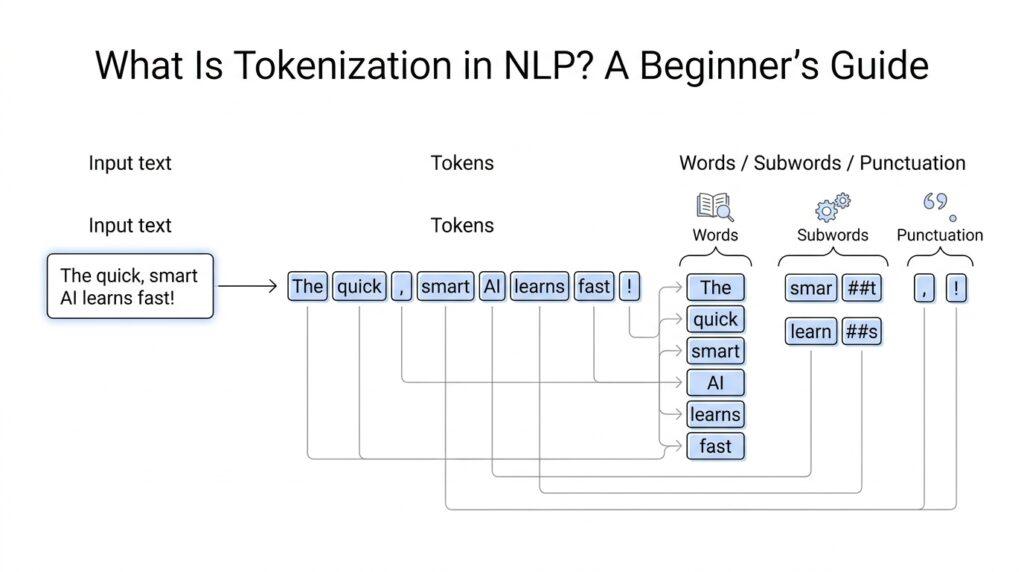
When we start looking at tokenization in NLP, the first surprise is that there is no single “correct” way to cut text apart. A tokenizer is more like a set of kitchen tools than a single knife: one tool chops at the word level, another trims words into smaller fragments, and another slices all the way down to characters. If you have ever wondered, what are the common tokenization methods in NLP?, the answer begins with understanding that each method makes a different trade-off between simplicity, detail, and flexibility.
The most familiar approach is word tokenization, which splits text into words and usually keeps punctuation as separate tokens too. This feels natural because it mirrors how we read, so a sentence like “The cat slept.” becomes a short list of familiar pieces. Word tokenization works well when language has clear spaces between words, but it can stumble when contractions, hyphenated terms, or languages without spaces enter the scene. That is why word tokenization is often the first stepping stone in tokenization in NLP, but not always the final answer.
From there, we move into subword tokenization, which breaks words into smaller meaningful chunks called subwords. A subword is not necessarily a full word; it is more like a fragment that the model can reuse across many different words, which helps with rare names, misspellings, and new vocabulary. This is the method many modern Transformer models prefer because it gives the model a balanced view: large enough pieces to preserve meaning, small enough pieces to handle unfamiliar text. In practice, methods like Byte Pair Encoding, WordPiece, and Unigram all belong to this family, and they are popular because they make tokenization in NLP much more flexible.
If word tokens are like cutting a loaf into slices, subword tokens are like keeping a few slices whole while breaking the crusty parts into smaller, reusable bits. That may sound messy at first, but it is actually the opposite: the model gets a cleaner way to deal with language it has never seen before. Instead of failing on an unusual word, it can rebuild that word from pieces it already knows. This is one reason subword tokenization has become the default choice for many large language models, especially when vocabulary size and coverage both matter.
Then we have character tokenization, which splits text into individual letters, numbers, and symbols. This method is the most detailed of the common tokenization methods, and it can be helpful when spelling matters a great deal or when a language has complex word forms. The trade-off is that character-level text becomes much longer, so the model must process many more tokens to read the same sentence. That extra length can make learning slower and context harder to hold, which is why character tokenization is powerful in some tasks but less practical as a general-purpose choice.
There is also sentence tokenization, which divides text into sentences instead of words or characters. This is not usually the format a language model consumes directly, but it is extremely useful when we want to break a document into manageable sections before doing another kind of analysis. Think of it as opening a long letter and placing little tabs between the thoughts before we sort the finer details. In tokenization in NLP, sentence tokenization often works alongside word or subword methods, giving us a cleaner path from a full document to smaller pieces.
The real decision, then, is not which method sounds smartest, but which one fits the job in front of us. Word tokenization gives us readability, subword tokenization gives us flexibility, character tokenization gives us precision, and sentence tokenization gives us structure. When we choose among them, we are deciding how much meaning to keep together and how much to break apart, and that choice shapes how well the model can learn from the text. Once those pieces are in place, we can move from how text is split to how those splits become the numerical form a model can actually use.
Simple Tokenization Example in Python
When you first try tokenization in NLP in Python, the big leap is realizing that a sentence stops being a sentence and starts being a list. NLTK describes tokenizers as tools that divide strings into substrings, and its word_tokenize() example shows punctuation becoming its own token instead of vanishing into the text. If you have ever wondered, “How do I tokenize a string in Python for NLP?”, this is the moment where the answer turns from theory into something you can print on the screen.
from nltk.tokenize import word_tokenize
text = "Small steps make tokenization feel less mysterious."
tokens = word_tokenize(text)
print(tokens)
When you run that code, you get a list of pieces rather than one long sentence. That is the heart of tokenization in NLP: we are not asking Python to understand the sentence yet, only to break it into manageable units. In a real example, word_tokenize() can also separate punctuation, which is why a period often appears as its own token.
Now we can take the next small step and turn those tokens into numbers. Real models do not read plain words the way we do; Hugging Face’s tokenizer docs explain that tokenization splits text into tokens and converts them to token IDs through a vocabulary lookup. To make that idea feel concrete, we can build a tiny toy vocabulary and map each token to a number, which mirrors the shape of what a model does without adding any heavy machinery.
toy_vocab = {
"Small": 101,
"steps": 102,
"make": 103,
"tokenization": 104,
"feel": 105,
"less": 106,
"mysterious": 107,
".": 108
}
token_ids = [toy_vocab.get(token, 0) for token in tokens]
print(token_ids)
That little 0 is a helpful placeholder for “unknown token” in our example, which means “this word is not in our toy vocabulary.” In a larger tokenizer, the vocabulary is learned from training data, and the IDs are part of the model’s expected input format. Hugging Face also notes that special tokens can be added to the vocabulary and kept isolated from normal splitting, which is why token IDs and special markers often travel together.
This is where the example starts to feel more like the real world. A tokenizer does not only carve up text; it also helps the model know where a sequence begins, where it ends, and when two pieces of text belong together. Hugging Face’s tokenizer API documents special tokens such as [CLS], [SEP], and [MASK], and it explains that these markers are handled separately from ordinary words so they can be skipped during decoding when needed.
If you want one mental picture to keep, make it this: tokenization in NLP is the moment raw language gets handed a label maker. First we split the text, then we assign IDs, and then the model can work with something structured instead of something messy. That is why a tiny Python snippet can teach so much—it shows the entire bridge from human words to machine-friendly input, one small piece at a time.
Common Challenges and Edge Cases
Now that we have seen how tokenization in NLP works in the ordinary case, the harder question appears: what happens when text refuses to behave neatly? This is where tokenization stops feeling like a tidy classroom exercise and starts looking like real language, with all its wrinkles, shortcuts, and surprises. A tokenizer can split a sentence perfectly one moment and then stumble over an apostrophe, a hyphen, or a name it has never seen before. That is why common challenges in tokenization matter so much—they are the places where the difference between a good tokenizer and a great one becomes visible.
One of the first surprises is punctuation that seems harmless to us but carries real meaning for the model. Contractions such as “don’t” can become “do” and “n’t,” which may be useful in one setting and confusing in another, while hyphenated forms like “state-of-the-art” can be treated as one idea or several separate pieces. Numbers create their own puzzle too, because “3.14,” “2026,” and “1,000” look simple to us but may be split differently depending on the tokenizer’s rules. Why does tokenization in NLP sometimes split a simple sentence in a surprising way? Because the tokenizer is not reading meaning the way a person does; it is following patterns it was designed to recognize.
Names and rare words create another kind of edge case. A word that appears constantly in your training data may stay whole, while a new brand name, a misspelling, or a technical term gets broken into fragments. That can be helpful, because subword tokenization gives the model a way to cope with unfamiliar text instead of failing outright. Still, it can also produce awkward splits that make a single idea feel scattered, especially when the text includes product names, medical terms, or social media handles. In tokenization in NLP, these small fragments are not errors so much as compromises, and the compromise matters more in some tasks than others.
Then there is the question of language itself. English gives us spaces between words, so token boundaries often feel obvious, but many languages do not offer that convenience. In Chinese, Japanese, and Thai, for example, the tokenizer has to infer where one word ends and the next begins, which adds an extra layer of difficulty. Even within space-based languages, multilingual text can switch scripts, alphabets, and spelling conventions in a single sentence, and that can push a tokenizer far outside its comfort zone. The moment we move beyond clean textbook examples, tokenization becomes less like cutting a loaf of bread and more like sorting a mixed drawer full of objects that do not all share the same shape.
Normalization is another quiet challenge that often hides in plain sight. Text may contain curly apostrophes, accented letters, emojis, repeated punctuation, or invisible formatting marks, and the tokenizer may treat those characters differently depending on how the input was cleaned first. A sentence written as plain ASCII looks almost the same to us as a sentence with typographic symbols, but to a tokenizer those details can change the token list. That is why preprocessing and tokenization often travel together: before we split the text, we often need to decide whether we want to preserve every detail or smooth some of them away.
Special tokens add one more layer of care. Earlier, we saw markers such as start and end tokens, but edge cases appear when these markers collide with real text or when a dataset includes unusual formatting. If a chatbot transcript, code snippet, or document archive already uses bracketed labels, the tokenizer has to keep those labels separate from its own special markers. This is one reason tokenization in NLP is not just a mechanical step; it is a negotiation between the text we received and the structure the model expects.
The practical lesson is that there is no perfect tokenizer for every situation. A tokenizer that works beautifully for news articles may struggle with tweets, legal contracts, poetry, or multilingual chat messages. So when we see odd splits, we should not assume the tokenizer is broken; often it is revealing a mismatch between the text we have and the rules we chose. Once we learn to expect these edge cases, tokenization becomes less mysterious, and we can make better choices about how to prepare text for the model that will read it next.