What Are LLMs?
When people first hear about LLMs, they often imagine a machine that somehow “knows” a lot of things. That picture is close, but the real story is more interesting: a large language model is a deep learning system trained to read enormous amounts of text and learn patterns in how words, sentences, and ideas fit together. In plain language, it is a model that gets very good at predicting what text should come next. If you have ever asked, “What are LLMs, really?” the answer starts there.
To make that idea feel less mysterious, let’s break the name apart. A model is a mathematical system that learns from data. Language means the model works with human text, not numbers in a spreadsheet or images of cats. Large refers to the size of the training data and the number of internal settings the model can adjust while learning. In deep learning, those internal settings live inside a neural network, which is a network of layered calculations inspired by the way the brain handles information, though it is much simpler than a real brain.
The training process is where an LLM becomes useful. During training, the model sees text cut into small pieces called tokens, which can be whole words, parts of words, or even punctuation marks. Its job is to guess the next token again and again, like a reader trying to finish your sentence before you do. Over time, it gets better at spotting grammar, style, common facts, and even subtle relationships between ideas. That is why LLMs can sound fluent: they have practiced the rhythm of language on a scale that would be impossible for a human to match.
Here is the part that often surprises beginners: an LLM does not store language like a dictionary or a notebook full of facts. Instead, it learns statistical patterns, which are regularities that show up repeatedly in the text it studied. Think of it like a musician who has listened to thousands of songs and can now anticipate how a melody might move next. The model is not “thinking” in the human sense, but it is making highly informed guesses based on patterns it has learned from deep learning.
That is also why LLMs are useful for so many tasks. They can answer questions, summarize articles, translate text, draft emails, rewrite paragraphs, and help with coding because each of those tasks depends on understanding and generating language. They do not perform these tasks by opening a hidden encyclopedia in their memory; they do them by producing text that fits the patterns they learned during training. In other words, an LLM is less like a storage cabinet and more like an extremely practiced autocomplete engine.
Of course, that power comes with limits, and those limits matter. Because LLMs generate likely text rather than checking reality on their own, they can make mistakes, sound confident when they are wrong, or reflect biases found in their training data. That is why we should think of LLMs as powerful assistants rather than perfect authorities. As we move forward, the next useful question is not only what they are, but how they learn so much language in the first place and why deep learning makes that possible.
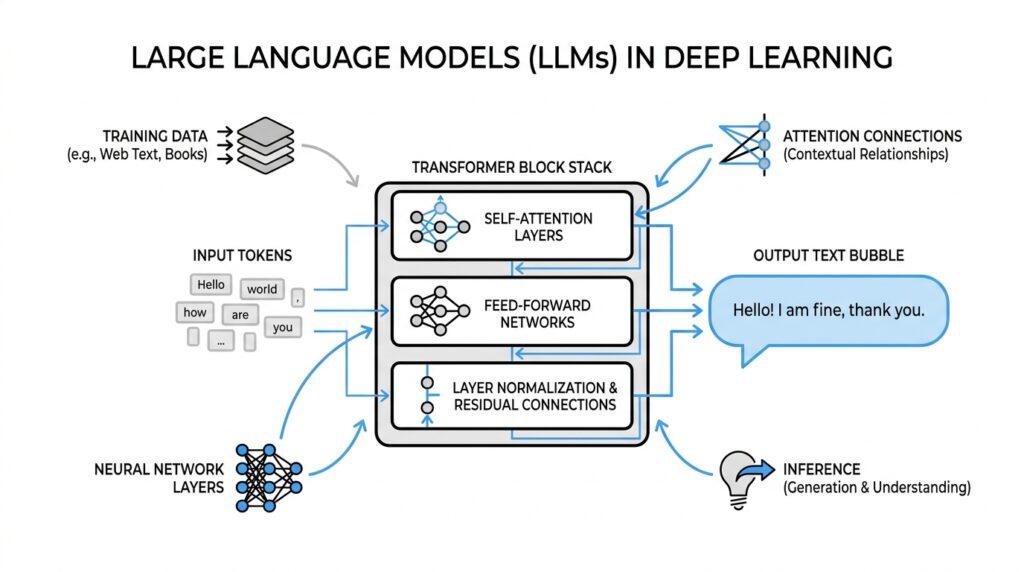
Transformer Basics
Now that we know LLMs learn patterns in text, the next question is how they keep those patterns organized. How does a transformer read a sentence without marching through it word by word? The answer is that it looks at the whole sequence and lets each token borrow context from the others through attention, the core idea behind the Transformer architecture introduced in the original paper. That shift away from step-by-step processing is what makes the model feel so responsive when it handles language.
Think of self-attention as a room full of notes on a table. When you pick up one note, you can glance at the others to decide what it means, and the Transformer does something similar with tokens. In the paper’s language, a token acts like a query, nearby tokens provide keys and values, and the model blends those values into a new representation. That sounds abstract at first, but the everyday idea is simple: each word learns to pay attention to the words that matter most around it.
This is where transformers differ from older recurrent neural networks (RNNs), which process tokens one after another. RNNs must wait for the previous step before they can move on, and that makes long sequences slower to train and harder to parallelize, meaning to run many calculations at the same time. Transformers remove that bottleneck by connecting tokens through attention instead of a chain of steps, so the model can handle many positions together. The original paper showed that this design trained faster and performed better on machine translation tasks.
The model also does not use a single lens. It uses multi-head attention, which means several attention heads work in parallel, each with its own learned projection, or custom view of the same tokens. One head might focus on local grammar, another on a distant subject, and another on a phrase that clarifies meaning later in the sentence. When those heads are combined, the model gets a richer picture than one attention pass could provide on its own.
There is one catch, though: attention alone does not know word order. If we shuffled the same tokens, the model would need some extra signal to tell ‘cat bites dog’ from ‘dog bites cat,’ so the Transformer adds positional encodings, which are numbers that mark where each token sits in the sequence. The original paper used sine and cosine patterns of different frequencies, a choice that gives the model a sense of relative distance as well as absolute position. That small addition is what lets a transformer read a sentence as a sentence, not just as a bag of tokens.
Inside each transformer block, attention is followed by a feed-forward network, a small fully connected network that processes each position separately, and the model wraps these pieces with residual connections and layer normalization, which help information flow and keep training stable. In the decoder, the model also uses masking, meaning it hides future tokens so it can only predict from what it has already seen. Once those pieces click into place, an LLM stops looking like a black box and starts looking like a stack of organized reading steps, each one refining the meaning of the text a little more.
Tokenization And Embeddings
Before a model can pay attention to language, it has to meet language in a form it can work with. That is where tokenization and embeddings enter the story: tokenization breaks text into small pieces a model can handle, and embeddings turn those pieces into numbers that carry meaning. If you have ever wondered, how does an LLM turn a sentence into something a neural network can read? this is the bridge we need. It is the quiet beginning of the whole process, and it matters more than it first appears.
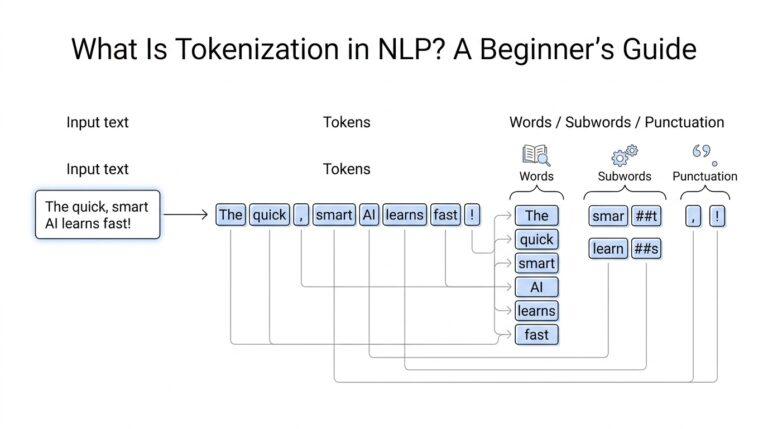
Tokenization feels a little like sorting a long ribbon of words into manageable beads. A tokenizer is the tool that decides where one piece ends and the next begins, and those pieces are called tokens, which can be whole words, parts of words, or punctuation marks. This choice is important because language does not always arrive in neat, separate blocks; some words are rare, some are long, and some are new to the model. By splitting text into tokens, the model gets a stable way to handle familiar phrases, awkward word endings, and even words it has never seen before.
That last part is where tokenization becomes especially useful. Instead of giving up on a strange word, many tokenizers break it into smaller subword pieces, which are word fragments that often recur across different words. A name, a technical term, or a misspelling can still be represented because the model can assemble meaning from pieces it already knows. In practice, this makes tokenization a kind of compromise between precision and flexibility, giving the model enough structure to read efficiently without forcing every word to live in a rigid dictionary.
Once the text has been tokenized, the model still has one more job: it has to turn those tokens into something that looks like understanding. That is the role of embeddings, which are learned numeric representations that place tokens in a vector space, meaning a coordinate system made of numbers. You can think of this space like a map where similar words live in nearby neighborhoods, so tokens with related meanings end up closer together than unrelated ones. Instead of seeing the word as a raw label, the model now sees a bundle of numbers that hints at how the word behaves in language.
This is where embeddings become more than a technical detail. A token like “king” might end up near “queen,” while “apple” sits closer to other fruit-related words than to a programming term. These relationships are not hand-built by a human; the model learns them during training by noticing which tokens appear in similar contexts. That is why embeddings are so powerful: they give the model a way to compare meanings, not just spellings, and they turn tokenization from a simple splitting step into the start of semantic understanding.
We can also see why embeddings are such a natural fit for transformers. The attention mechanism from the previous section does not work directly on text; it works on vectors, the numeric patterns produced by embeddings. In other words, tokenization creates the pieces, and embeddings give those pieces shape and direction before the transformer begins its reading pass. Without that translation step, the model would have nothing useful to compare, no way to measure closeness, and no structured input to guide attention.
There is one more small but important idea here: embeddings are learned, not fixed. As training continues, the model keeps adjusting them so the numeric space reflects the patterns it finds in real language. That means the embedding for a token is not a dictionary definition; it is more like a living summary of how that token tends to behave around other tokens. When tokenization and embeddings work together, the model stops seeing text as raw symbols and starts seeing it as organized, meaningful structure.
Pretraining And Fine-Tuning
After tokenization and embeddings have done their quiet work, the model is finally ready to learn from experience, and that is where pretraining and fine-tuning enter the story. If you have ever asked, how does an LLM go from reading the internet to answering your specific question? the answer lives in this two-step training process. Pretraining gives the model its broad language sense, while fine-tuning helps it adapt that knowledge to a narrower purpose, like a student who first studies an entire subject and later practices for one exam.
Pretraining is the long, expensive first chapter. During this stage, a large language model sees huge amounts of text and learns by trying to predict the next token, which is a small piece of text such as a word fragment or punctuation mark. This is why pretraining matters so much: it teaches the model grammar, common facts, writing rhythms, and the hidden patterns that make language feel coherent. In deep learning, this phase is often called self-supervised learning, meaning the model creates its own training signal from the text itself instead of relying on hand-labeled answers.
You can picture pretraining as wandering through a giant library with no tutor beside you, only a very strict game: every time you read a sentence, you must guess what comes next. At first, the guesses are clumsy, but over time the model notices repeated structures, familiar phrases, and long-range relationships between ideas. That is how pretraining builds the general-purpose power of LLMs. It does not teach one narrow skill; it gives the model a broad foundation so it can later move into many different tasks without starting from zero.
Fine-tuning comes next, and it feels much more focused. In this stage, we take a pretrained model and train it further on a smaller, more targeted dataset, which is a collection of examples chosen for a specific job. That job might be customer support, medical note drafting, legal summarization, or a chatbot that speaks in a particular style. Fine-tuning is a form of transfer learning, which means reusing knowledge learned from one task to improve performance on another task.
This is the moment where the model becomes more useful for real-world work. A general pretrained model may know language well, but it does not yet know your preferred format, your domain vocabulary, or your rules for tone and safety. Fine-tuning narrows the behavior so the model responds in ways that fit the task more closely. It is a little like taking a musician who already knows music theory and helping them rehearse one specific song until the performance feels polished and natural.
There are different ways to fine-tune an LLM, and the names can sound intimidating at first. Supervised fine-tuning means the model learns from example input-and-output pairs, so it sees a prompt and the response it should imitate. Instruction tuning is a nearby idea, where the model practices following human-written instructions more reliably. Both approaches shape the pretrained model into something more helpful, because they teach it not only what to say, but how to say it in the format people expect.
The key thing to remember is that pretraining and fine-tuning serve different jobs. Pretraining builds general language ability at scale, while fine-tuning refines that ability for a particular use case. One gives the model breadth; the other gives it direction. When these two stages work together, we get an LLM that can start as a broad learner and then become a focused assistant, ready to handle specialized prompts without losing the language fluency it learned earlier.
That partnership also explains why LLMs can feel so flexible. The same pretrained foundation can be adapted into a writing helper, a code assistant, or a domain-specific chatbot, depending on what kind of fine-tuning it receives. In the next step of the journey, what matters is not only how the model learned language, but how we guide that learning so it behaves in useful, reliable ways.
Prompting And RAG
When we start using an LLM in the real world, the story changes from what can it do? to how do we guide it? That is where prompting and retrieval-augmented generation (RAG) come in. A prompt is the instruction or question you give the model, and prompting is the practice of shaping that instruction so the model has a clearer path forward. If you have ever wondered, “How do you get better answers from an LLM when it doesn’t know your exact documents?” RAG is the next piece of the puzzle.
Prompting feels a little like talking to a smart helper who can read quickly but still needs direction. The model does not magically know which angle you want, how detailed the answer should be, or whether you want a summary, a list, or a step-by-step explanation. So we give it clues: we set the role, the task, the audience, and sometimes even the style. In practice, good LLM prompting often looks less like issuing a command and more like handing someone a well-labeled note with enough context to do the job well.
That context matters because an LLM can only work with what fits inside its context window, which is the amount of text it can consider at one time. Think of that window like a desk with limited space: if the desk is full, the model can only “see” what is already there. Prompting helps us use that space wisely by placing the most useful information first and keeping the request focused. A vague prompt invites a vague answer, while a clear prompt gives the model a better map to follow.
RAG solves a different problem, and this is where things get interesting. Sometimes the model needs information that is too specific, too recent, or too private to rely on memory alone. Retrieval-augmented generation means we first retrieve relevant documents, passages, or notes from an external source, then give those materials to the model along with the prompt. It is a bit like asking a friend to answer a question after we have already placed the right books on their desk.
That extra retrieval step changes the game. Instead of asking the model to guess from general training patterns, we let it ground its answer in source material we chose. In a business setting, those sources might be policy documents, product manuals, or internal knowledge bases. In a personal project, they might be class notes or research summaries. RAG does not replace the model’s language skill; it gives that skill something concrete to hold onto, which often makes the response more accurate and easier to trust.
Prompting and RAG work best together, and the partnership is easy to picture. RAG gathers the relevant facts, while prompting tells the model how to use them. If the retrieved text is the stack of ingredients on the kitchen counter, the prompt is the recipe card that says what meal we want to make and how to present it. Without the prompt, the model may use the right sources but answer in the wrong shape; without RAG, the model may sound polished while still missing the exact details you needed.
This is why people often talk about prompt engineering, which means designing prompts carefully so the model behaves more usefully. Good prompt engineering is not about secret phrases or tricks; it is about clarity, constraints, and context. We can ask the model to cite the provided text, avoid making assumptions, or answer only from the retrieved material. Those small instructions help turn a general-purpose language model into a much more dependable assistant.
Taken together, prompting and RAG show a useful lesson: an LLM becomes more powerful when we stop treating it like a mind reader and start treating it like a collaborator. We bring the right information into view, and we phrase the request so the model knows what to do with it. That is the real bridge from a fluent language model to a practical tool we can trust in everyday work.
Evaluating Model Outputs
Once we start prompting an LLM or grounding it with RAG, the next question arrives quickly: how do we know the answer is good? Evaluating model outputs is the part of the journey where we stop admiring fluent text and start checking whether it is actually useful. That matters because a polished paragraph can still be wrong, incomplete, biased, or strangely off-topic. In other words, LLM evaluation helps us tell the difference between a model that sounds confident and a model that earns our trust.
The first thing we usually look for is whether the answer matches the task. If we asked for a summary, did the model compress the main ideas without inventing new ones? If we asked for a factual explanation, did it stay anchored to the source material? This is where the idea of a rubric comes in, which is a simple scoring guide that tells us what to value, such as correctness, clarity, completeness, and tone. When we evaluate model outputs with a rubric, we give ourselves a steadier way to judge quality instead of relying on a vague gut feeling.
That judgment can happen in two broad ways: by humans or by automated metrics, which are numerical measures used to compare outputs. Human review is valuable because people notice things that numbers miss, like whether an answer feels misleading, evasive, or unhelpfully wordy. Automated checks are useful because they scale, so we can compare many responses quickly and consistently. In practice, the best LLM evaluation often mixes both, because a model can score well on a metric and still fail a real user in a subtle way.
A common concern is hallucination, which means the model produces information that sounds plausible but is not supported by evidence. If you have ever asked, “How do we evaluate model outputs when the model sounds right but is actually making things up?” that is the problem we are trying to catch. For that reason, we often test whether the answer is grounded in the prompt, the retrieved documents, or the expected reference answer. We also look for consistency: if we ask the same question in slightly different ways, does the model keep its facts straight, or does it drift?
This is where side-by-side comparison becomes especially helpful. Instead of asking whether one answer is perfect, we compare two model outputs and ask which one better follows the instructions, uses evidence, and stays readable. That method works well in model development because it reveals tradeoffs we might miss in a single score. One answer may be shorter and cleaner, while another may be more complete but less precise. By comparing them directly, we learn what kind of behavior we actually want the model to repeat.
We also need to pay attention to safety and fairness, not only accuracy. A response can be factually correct and still be harmful if it amplifies stereotypes, mishandles sensitive topics, or gives advice with too much confidence. So evaluation should include checks for bias, refusal behavior, and appropriate uncertainty, especially when the model is used in high-stakes settings. A strong LLM output is not only fluent; it is also careful about what it claims and where its limits begin.
In real projects, evaluation works best when we treat it like a habit rather than a one-time test. We define what good looks like, create representative prompts, review outputs against those expectations, and repeat the process as the model changes. That gives us a practical loop for LLM evaluation: we can see whether prompting changes helped, whether RAG improved grounding, and whether a fine-tuned model is actually better for the job. Once that loop is in place, we are no longer guessing at quality; we are watching it take shape, one model output at a time.
Deployment And Optimization
How do you deploy an LLM without it feeling slow or expensive? This is where LLM deployment and optimization stop being abstract ideas and start acting like practical design choices. We move from training a model to serving it, which means we care about latency (how long one answer takes) and throughput (how many requests the system can handle over time). The goal is not to make the model bigger on paper; it is to make it responsive enough that a person can actually use it.
The first surprise is that the main bottleneck is often memory, not imagination. During inference, the model must keep a KV cache—short for key-value cache, a stored record of earlier tokens—so it can remember the conversation as it generates the next words. In real serving systems, that cache can grow and shrink quickly, and inefficient handling wastes space through fragmentation and duplication. PagedAttention, the core idea behind vLLM, was designed to reduce that waste and let more requests fit into the same GPU memory, which in turn raised throughput by 2–4× in the paper’s evaluations.
Once that memory pressure is under control, batching becomes the next quiet hero. Batching means grouping multiple requests so the GPU can work on them together, like carrying several grocery bags in one trip instead of many tiny ones. Modern serving stacks such as TensorRT-LLM and vLLM support features like in-flight batching, paged KV caching, and custom attention kernels because these tools help keep the hardware busy instead of waiting between requests. When people ask why one LLM feels snappy while another drags, the answer is often not the model alone but the serving engine behind it.
Another major lever is quantization, which means using lower numerical precision so the model needs less memory and less compute. Instead of storing every number in a larger format, we compress them into smaller representations such as INT8, FP8, or even 4-bit variants, depending on the system. SmoothQuant is a good example of this approach: it is a training-free post-training quantization method that moves difficulty from activations to weights, enables INT8 for both weights and activations, and reports up to 1.56× speedup with 2× memory reduction. In practice, that can turn a model that barely fits into one that serves comfortably.
We also get wins by making attention itself more memory-aware. Attention is the mechanism that lets the model compare tokens with one another, but it becomes costly on long sequences because it moves a lot of data between different layers of GPU memory. FlashAttention addresses that problem by tiling the computation and reducing reads and writes between high-bandwidth memory and on-chip SRAM, which is faster and more efficient. For long prompts, this kind of optimization matters because the model is not only thinking harder; it is also shuffling more information around.
A final trick is speculative decoding, which speeds up generation by asking a small draft model to guess upcoming tokens and then having the larger model verify them. Think of it like sketching a route before a guide checks it, instead of waiting for the guide to plan every step from scratch. Research shows that the speedup depends heavily on the draft model’s latency, not just on how strong it is at language modeling, so the fastest setup is not always the fanciest one. That is why LLM optimization is really a search for the right bottleneck to remove first, whether that bottleneck is memory, precision, attention movement, or decoding itself.