What Is Multi-Token Prediction
Imagine you are asking a language model to keep writing a sentence, and instead of peeking ahead one word at a time, it tries to see a few words down the road at once. That is the basic idea behind multi-token prediction. If you have ever wondered, what is multi-token prediction in deep learning?, the shortest answer is that the model learns to predict several future tokens, not only the very next one. A token is a small piece of text a model works with, such as a word, part of a word, or even punctuation, depending on the system.
This matters because ordinary language models usually learn in a very step-by-step way. They read a sequence, then predict the next token, then move forward and do it again. That works well, but it can also feel a little like walking across a room by staring only at the floorboards directly in front of you. With multi-token prediction, the model is asked to look a bit farther ahead, which can give it a stronger sense of where the sentence is going. In other words, multi-token prediction teaches the model to think in short stretches, not just single steps.
The training process is where the idea becomes concrete. During training—the stage where a model learns from examples—the model sees a text sequence and is given several future tokens as targets. A target is the answer the model is supposed to learn to produce. So instead of learning only “what comes next,” it may learn “what comes next, and what comes after that, and maybe one more step beyond that.” This is a form of sequence prediction, which means making guesses about an ordered series of items. The key shift is that the model is no longer rewarded only for short-term accuracy; it is also pushed to capture a little more structure across time.
Why does that help? Because language is full of patterns that stretch beyond one token. A phrase, a clause, or a code snippet often makes more sense when you consider several pieces together. Multi-token prediction can encourage the model to build richer internal representations, which are the hidden patterns it stores while learning. You can think of it like learning a melody instead of isolated notes. When the model predicts multiple tokens at once, it gets more practice noticing how nearby pieces fit together, and that can improve fluency, consistency, and sometimes efficiency.
There is also a practical side to this idea. Predicting multiple tokens can reduce the number of decision points the model needs to make during generation, at least in some designs. That can make the model feel more direct, as if it is planning a few moves ahead before speaking. The tradeoff is that the task becomes harder, because the model must balance several future possibilities instead of focusing on one simple answer. So multi-token prediction is not magic; it is a different learning strategy that asks the model to carry a little more context in its head.
It helps to separate the concept from a common misunderstanding. Multi-token prediction does not mean the model becomes omniscient or skips reasoning altogether. It still relies on patterns learned from data, and it still makes mistakes. What changes is the shape of the task: the model is trained to map one stretch of context to several future tokens in the sequence, rather than treating each token as an isolated event. That is why the idea shows up so often in discussions of multi-token prediction methods, faster decoding, and newer language model training strategies.
By the time we zoom back out, the picture is fairly simple. Multi-token prediction is a way of teaching a deep learning model to forecast more than one future token at a time, giving it a slightly wider view of the road ahead. That wider view can make the model better at capturing patterns that unfold across several words, which is exactly why this technique has become such an interesting part of modern language modeling.
Why Next-Token Prediction Falls Short
When you watch a model finish a sentence, it can look like it is thinking ahead, but next-token prediction is really a tiny relay race: one token hands off to the next, over and over. Why does next-token prediction feel so strong and yet still fall short when a task needs planning? The reason is that the objective rewards the model for the immediate continuation in front of it, which can nudge it toward local patterns instead of broader structure. That is why multi-token prediction starts to matter: it asks the model to look a little farther down the road instead of staring only at the next step.
The training setup is part of the trap. During teacher forcing, which means the model is trained on the correct previous tokens rather than its own guesses, the learning problem looks cleaner than real generation does. The pitfalls paper argues that this can hide a deeper issue: in some tasks, teacher forcing can fail to learn an accurate next-token predictor in the first place, even when the task seems straightforward to us. So the model may look competent during training while still missing the kind of planning the task actually needs.
Then comes the moment where the model has to stand on its own. During generation, each new token becomes part of the next input, so a small mistake can change the context and make the next guess harder, which is the familiar compounding-error problem. Think of it like taking one wrong turn on a road trip: the error is small at first, but every later turn is made from the wrong map. Next-token prediction trains one move at a time, yet real use asks for a sequence that stays coherent across many moves.
This is where multi-token prediction offers a different kind of lesson. Instead of asking for only one future token, the model predicts several future tokens at once using independent output heads on top of a shared trunk, which pushes it to learn more than the easiest local continuation. In the Meta paper, that change improved sample efficiency and downstream performance, especially on code tasks, and models trained with four-token prediction were reported to be up to 3× faster at inference. In other words, the model is no longer practicing only the first step of the dance; it is rehearsing a short sequence.
So the limitation is not that next-token prediction fails at everything. It is that it can be too short-sighted for tasks where the right answer depends on a few moves of planning, not a single guess. Multi-token prediction widens the training signal and gives the model more reason to connect nearby tokens into a larger pattern. That wider view is the bridge to what comes next: how chunked prediction changes the way a model learns to organize context.
Model Architecture and Output Heads
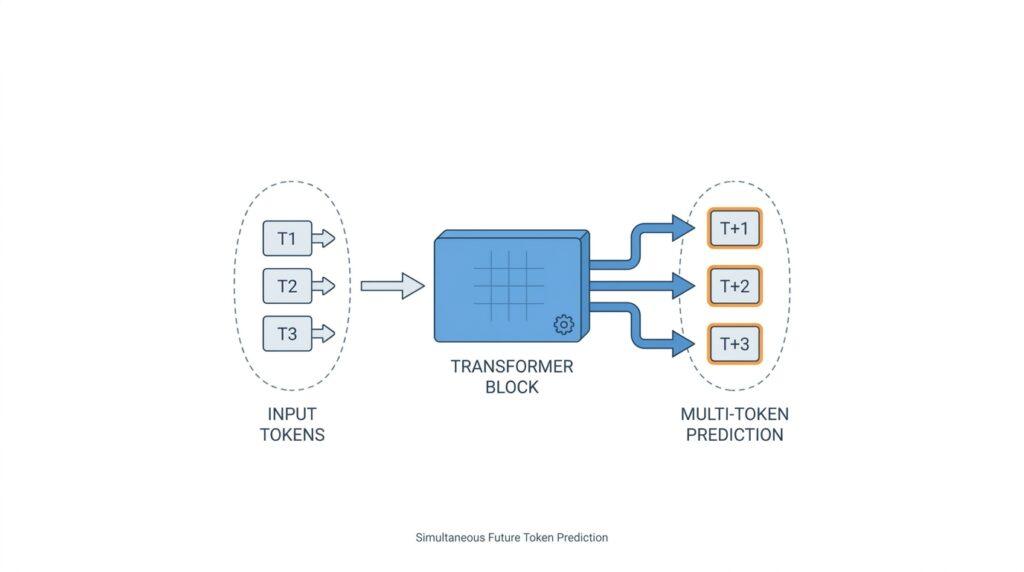
Now that we know why looking only one token ahead can feel cramped, the architecture starts to make sense. In multi-token prediction, the model usually keeps one shared backbone, sometimes called the trunk or base model, and adds several output heads, which are small prediction layers that each make a separate guess about the future. If you have ever wondered, how does multi-token prediction work inside a language model?, this is the key idea: one body, many “speaking” mouths, each responsible for a different step ahead.
The shared trunk does the heavy lifting. It reads the input text and turns it into hidden states, which are the model’s internal summaries of what it thinks the sequence means so far. Think of hidden states like a traveler’s notebook: they are not the final answer, but they store the route, landmarks, and warnings we will need next. Because every output head can read from the same notebook, the model does not have to relearn the whole context for each future token. Instead, it reuses the same core representation and lets each head focus on a different horizon.
That arrangement is what makes the design feel different from ordinary next-token prediction. In a standard setup, one output head takes the final hidden state and predicts only the next token. In multi-token prediction, several heads sit on top of the shared backbone, and each head is trained to predict a different future token offset, such as the next token, the one after that, and the one after that again. The result is a model architecture for multi-token prediction that behaves a bit like a group of hikers checking the trail at different distances instead of one person peering at the ground right in front of their shoes.
This also explains why the heads are usually kept lightweight. Each output head is often just a small linear layer, meaning it applies a learned weighted mapping from hidden states to vocabulary scores, where vocabulary scores are the model’s confidence values for each possible token. The backbone learns the shared understanding of context, while the heads specialize in turning that understanding into multiple forecasts. That division of labor matters because it keeps the system efficient: the model does not need a separate full network for each prediction step, only a separate decision layer.
Training ties everything together. For each position in the text, the model produces several predictions at once, and each output head is compared against its own target token. A target is the correct answer the model is trying to learn, and the loss is the measure of how far its guesses are from that answer. When all heads contribute to the loss, the backbone gets a richer learning signal, because it must create representations that support both the immediate continuation and the nearby future. That is one reason multi-token prediction can encourage better planning inside the model, not just better guesswork.
The design also raises a practical question: why not make every head completely separate? The answer is that sharing the trunk helps the model stay compact and consistent. Each head sees the same context, so the model can learn a coherent short-range forecast rather than a set of disconnected guesses. At the same time, the multiple heads nudge the representation to carry more structure across the sequence, which is exactly what we want when the next few tokens depend on one another.
Seen this way, the architecture is not complicated so much as carefully arranged. The shared backbone builds the understanding, the output heads turn that understanding into several future predictions, and the training objective teaches them to cooperate. That is the real heart of multi-token prediction: one internal model of the text, many short-range forecasts, all working together to widen the model’s view of what comes next.
Training Objective and Loss Design
Once we know the model has several heads, the next question is how we teach those heads to work together. The training objective in multi-token prediction starts from the same idea as ordinary language modeling: we compare the model’s guess with the correct next piece of text using cross-entropy, which is the standard loss that penalizes wrong predictions more when the model is confidently wrong. The difference is that multi-token prediction asks for several future tokens at the same position, so one hidden context must support several answers instead of only one. If you are asking, “How does the loss work when multi-token prediction looks ahead more than once?”, that is the heart of the design.
The cleanest way to picture it is as a row of overlapping checkpoints. At each training position, the shared trunk builds one internal summary of the text, and each output head is assigned a different future token to predict from that same summary. So the first head learns the next token, the second head learns the token after that, and so on, with each head carrying its own cross-entropy loss. Because all of those losses are active at once, the backbone is pushed to encode context that stays useful a few steps ahead, not only the easiest immediate continuation.
This is also where the training objective becomes more interesting than a simple “predict many tokens” slogan. The paper’s implementation treats the extra heads as a lightweight auxiliary task on top of a shared model trunk, and it computes their losses in a way that lets gradients flow back into the same backbone. In practice, the heads can be processed sequentially so the model does not need to hold every head’s logits and gradients in memory at the same time. That makes multi-token prediction feel less like building several separate models and more like asking one model to answer several nearby questions before moving on.
What does that do to the loss itself? For the two-token case, the paper shows an information-theoretic decomposition: the objective splits into a local next-token term, a shifted next-token term, and a mutual-information term that gets extra weight. In plain language, that means the model is nudged to preserve features that matter for the next step and to pay more attention to tokens that change what comes later. This helps explain why multi-token prediction can encourage planning-like behavior: the loss does not only reward short-term accuracy, it also rewards representations that make future decisions easier.
That matters because teacher forcing, the usual training setup where the model sees the correct previous tokens during training, can hide planning weaknesses. The “pitfalls” paper argues that next-token training can fail even before generation begins, so the model may never learn a truly reliable one-step predictor in some tasks. Its proposed teacherless variant uses dummy tokens to predict multiple steps in advance, which gives the model a broader training signal and reduces the gap between training and real decoding. In other words, multi-token prediction is not only about speed; it is also about giving the loss a better-shaped job to do.
So the practical lesson is small but important: the loss is not just a scorecard, it is the lesson plan. Multi-token prediction changes that lesson plan from “get the next word right” to “learn a short stretch of the road ahead,” and that wider signal is what makes the method so appealing for code, reasoning, and other tasks where the next few tokens depend on one another. From here, the natural question becomes how those extra heads help during generation, because the same training signal that widens the model’s view can also be used to speed up decoding.
Inference Speed and Efficiency Gains
The moment a model starts generating text, the real bottleneck shows up: it usually has to pause after every single token and decide again. Multi-token prediction changes that rhythm by letting the model prepare a short run of future tokens instead of one step at a time, which is why it can improve both speed and efficiency during inference. In the original paper, models trained with 4-token prediction were reported to be up to 3× faster at inference, even at large batch sizes.
How does multi-token prediction actually make generation faster? The answer is that it reduces the number of sequential decoding rounds, which are the slow part of autoregressive generation. Instead of making one forward pass, emitting one token, and repeating that loop forever, the model can use its extra output heads to draft a small block ahead through self-speculative decoding, a draft-and-check style of generation that reuses the same model rather than adding a separate draft model. Think of it like packing a few errands into one trip instead of driving back home after every stop.
That same design also keeps the system tidy. During plain inference, the model can still behave like a normal next-token predictor and use only the first output head; the extra heads are optional helpers when we want more speed. In the training setup, the paper also reports no train-time overhead, and its memory-efficient implementation reduces peak GPU memory pressure by processing each head in sequence instead of storing everything at once. In everyday language, that means the model is not dragging a pile of extra machinery around unless we ask it to.
The phrase “up to” matters here, because the gains are not a promise that every prompt will always run 3× faster. Speedups depend on how many drafted tokens get accepted, how long the response is, and how the hardware handles batching. Still, the idea has held up well enough that newer work has pushed it further: a 2026 self-distillation paper says multi-token prediction can turn a pretrained autoregressive model into a standalone multi-token model that decodes more than 3× faster with less than a 5% accuracy drop on GSM8K, while keeping the implementation simple and avoiding auxiliary verifier code.
That is the heart of the efficiency story. Multi-token prediction does not make the model “think less”; it makes each thinking step cover more ground. Fewer decoding turns mean less waiting for the user, less repeated compute for the GPU, and better throughput, which is the amount of text the system can produce per second. For chat assistants, code generators, and any workflow where you feel every extra second, that shift from many tiny steps to fewer larger ones is what makes the technique feel so practical.
Limitations and Practical Tradeoffs
When we first meet multi-token prediction, it can feel like a clean upgrade: why stop at one token when the model could glance a few steps ahead? The catch is that this wider view is harder to learn well. Recent papers note that multi-token prediction often helps most with short-range structure, while the gains can be modest once a task depends on longer-horizon planning rather than the next few words in a row.
The biggest tradeoff shows up during training, where the model has to solve several nearby prediction problems at once. In the common design, one shared trunk feeds multiple output heads, and each head learns a different future position; that gives a richer learning signal, but it also makes optimization more delicate. Newer work specifically points to two pain points: limited acceptance rates, meaning the share of drafted tokens that survive checking, and difficulty training all of the heads together so they help rather than compete.
Speed is the other side of the bargain. Multi-token prediction can reduce the number of sequential decoding rounds, which is why the original paper reported that 4-token models could run up to 3× faster at inference. But that speedup is not a free lunch, because it depends on how often the extra predictions are trusted, and newer self-distillation work still reports an accuracy tradeoff, even when the system is made simpler to deploy. In that 2026 paper, the authors report more than 3× faster decoding on GSM8K at under a 5% accuracy drop, which is impressive but also a reminder that latency and quality still pull against each other.
There is also a practical mismatch between the training story and the real world. The pitfalls paper argues that teacher forcing, where training feeds the model the correct previous tokens, can hide deeper failures in certain planning tasks and even fail to learn an accurate next-token predictor in the first place. That means multi-token prediction is not automatically a cure; it can widen the training signal, but it does not guarantee long-term reasoning, and the model may still lean on the easiest local continuation unless the task and data reward deeper structure.
So the working mental model is a balanced one: multi-token prediction can buy us better throughput and a broader training signal, but it asks for more careful tuning and more tolerance for uneven gains across tasks. It tends to shine when local continuity matters, like code or short structured generations, and it can feel less decisive when the real challenge is multi-step planning. That is why the next question is not whether multi-token prediction is useful, but when the extra heads are worth the added complexity.