What Machine Learning Is
When we first hear the phrase machine learning, it can sound larger and more mysterious than it really is. At its core, machine learning is a way for computers to learn patterns from data so they can make predictions or decisions without us writing every rule by hand. That is why people use it for things like spam filtering, recommendations, fraud detection, and other jobs where examples are easier to teach than a pile of rigid instructions.
So what is machine learning, really? Imagine teaching a friend to recognize dogs by showing them lots of pictures instead of giving them a strict checklist for every breed, coat color, and ear shape. The idea is similar: we feed a model examples, and during training it looks for patterns that help it answer new questions later. The important word here is generalization, which means doing well on fresh data, not only on the examples it already saw.
That training step is where the learning happens. NIST describes machine learning as having a training stage, where the model is learned, and a deployment stage, where it is used on new data to generate predictions. Some learning uses labeled data, which means the examples come with the correct answer attached, while other approaches work with unlabeled data and try to discover structure on their own. This is one reason machine learning feels a little like both studying and pattern hunting at the same time.
It also helps to separate machine learning from the broader world of artificial intelligence, or AI. AI is the larger field, and machine learning is one part of it; not every AI system learns from data, because some systems rely on rules that humans write explicitly. In other words, a rules-based program follows instructions we hand it, while a machine learning system builds those instructions from examples it has seen. That difference is small in wording but huge in practice, because it changes how the system improves over time.
You can think of a trained model as a memory with a job description. During training, it absorbs useful patterns from the data; during use, it applies those patterns to new cases, like deciding whether a message looks like spam or whether a product suggestion fits your taste. IBM describes this as learning patterns from training data and then making inferences about new data, while Google Cloud notes that machine learning is used to extract knowledge from data through techniques such as supervised and unsupervised learning. That is the heart of machine learning: not memorizing answers, but learning how to recognize the shape of an answer in unfamiliar situations.
Once that picture clicks, the rest of the topic starts to feel less intimidating. We are not asking a computer to become magical; we are teaching it to improve from examples, test that improvement, and then carry those lessons into the real world. With that foundation in place, we can start looking at how different kinds of models learn, what data they need, and why the quality of the examples matters so much.
Data, Features, and Labels
Now that we know a model learns from examples, the next question is the one that makes the whole picture start to click: what does machine learning data actually look like? In supervised learning, a dataset is a collection of examples, and each example usually holds two parts: features, which are the inputs, and a label, which is the answer the model is trying to predict. You can think of an example as one row in a spreadsheet, where the features describe the situation and the label says what happened or what should happen next.
Features are the clues, and they are not all equally useful. A feature is any value the model can use to spot patterns, while a feature set is the group of features the model trains on; in practice, that might mean things like location, size, temperature, or age, depending on the problem. One of the quiet surprises in machine learning is that not every feature has predictive power, so part of the craft is choosing the inputs that actually help the model see the pattern instead of distracting it. That is why a model predicting car price may care a lot about mileage and year, but far less about color or wheel size.
This is where feature engineering enters the story. Feature engineering means deciding which features might be useful and then converting raw data into forms the model can work with efficiently, almost like sorting loose ingredients into recipe-ready bowls before cooking. A raw dataset might contain text, numbers, categories, timestamps, or sensor readings, but the model usually needs those values translated into a clean feature vector, which is the array of feature values used during training and later during inference, meaning when the trained model makes predictions on new data. That translation step matters because machine learning data is only as helpful as the way we present it to the model.
Labels are the anchor point that keeps the lesson honest. In plain language, a label is the answer we want the model to learn, and in supervised learning that answer often comes from ground truth, which means the real outcome we are using as the reference point. Sometimes the label is direct, meaning it matches the exact prediction we want; other times it is a proxy, meaning it is close but not identical, like using “recently bought a bicycle” as a stand-in for “owns a bicycle.” Direct labels are usually better, but real-world datasets do not always give us perfect answers, so we often have to work carefully with the best available version.
Once we start labeling data, quality becomes the next big character in the story. A model can only learn well if the labels are accurate and the features are not noisy, missing, or misleading, because bad input leads to bad patterns. Good machine learning data also needs enough size and enough diversity to cover the situations the model will face later, since a huge dataset can still be narrow and a varied dataset can still be too small. When values are missing, teams may delete the example or fill in the gap through imputation, which means replacing the missing value with a reasonable estimate so training does not stumble over an empty spot.
So when we talk about features and labels, we are really talking about the two sides of the learning conversation. The features describe the world as the model sees it, and the labels tell the model what that world means, while the quality of the dataset decides how trustworthy that lesson will be. If we choose and prepare those pieces carefully, machine learning starts to feel less like magic and more like a disciplined way of teaching from examples.
Split Train, Validate, Test
Once you’ve gathered features and labels, the next quiet but crucial move in machine learning is to divide the data into three parts. Why not use the same examples for everything? Because a model can start to fool us if it studies the same data it is later graded on, so the usual train, validate, test split gives us a fairer story about how well it really learns. The training set is where the model learns patterns, the validation set is where we check those choices while building the model, and the test set is saved for the final, unbiased evaluation on unseen data.
The training set is the model’s practice room. Here, we let it see examples again and again so it can fit its internal parameters, which are the numbers it adjusts while learning. This is where the model does its actual studying, and it is also where overfitting can begin if it starts memorizing the practice examples instead of learning patterns that carry over to new data. That is why a strong machine learning workflow does not stop at training accuracy; it cares about whether the model can handle fresh inputs later.
The validation set is the checkpoint in the middle. Think of it like the practice quiz we use before the final exam: we look at it while training is still happening, and it tells us whether we should keep going, change a model setting, or step back because the model is starting to overfit. Those model settings are often called hyperparameters, meaning choices we make around the model rather than values the model learns directly, and the validation set helps us tune them without touching the final test data. In TensorFlow examples, validation metrics often peak and then start to stall or fall, which is the warning sign we are watching for.
The test set stays hidden until the end for a reason. It acts like the final exam, so we do not keep looking at it while making decisions, because that would let test-set knowledge leak into the model and give us an overly optimistic score. Scikit-learn’s guidance is explicit here: if we keep tweaking settings based on the test set, we stop measuring generalization, which means performance on truly new data. Google’s crash course also notes that validation and test sets can “wear out” if we use them too often, so the cleanest habit is to save the test set for one last check.
In practice, there is no magic split ratio that works everywhere, and that is a relief once you understand the goal. What matters most is that each split reflects the same general data distribution, contains no duplicates from the training set, and leaves enough examples in each bucket for a trustworthy result. It also helps to split the data before doing preprocessing, because steps like normalization or feature selection should learn from the training data only; otherwise, information from the validation or test set can sneak into training and distort the results. If the dataset is small, cross-validation can help during model selection, but even then a separate test set should still be held out at the end.
So when we split train, validate, test, we are not adding ceremony for its own sake. We are building a small honest courtroom for the model: one room for learning, one for course correction, and one for the final verdict. That structure keeps us from mistaking memorization for skill, and it gives us a much better chance of building a model that performs well outside the notebook.
Choose Your First Model
Now that we’ve prepared the data and set aside fair training, validation, and test sets, we arrive at the moment that often feels bigger than it is: choosing your first model. If you are asking, “Which machine learning model should I start with?”, the safest answer is usually the simplest one that can still solve your problem. A first model is not a lifelong commitment; it is more like a rough sketch that helps us see whether the data contains a real pattern at all.
The easiest way to narrow the field is to start with the shape of the problem. If you are predicting a number, such as price or temperature, you are working on a regression task, which means the model predicts a continuous value. If you are predicting a category, such as spam or not spam, you are working on a classification task, which means the model chooses among labels. That one distinction already points you toward different machine learning models, and it keeps the search from feeling endless.
For a first model, a linear model is often the best place to begin. A linear model is a model that tries to draw a straight-line relationship, or a weighted combination, between inputs and the thing you want to predict. In regression, that might be linear regression; in classification, it might be logistic regression, which is a classification model that estimates the probability of one class versus another. These models are popular first picks because they are quick to train, easy to inspect, and surprisingly strong on many beginner machine learning problems.
Why start simple instead of jumping to something flashy? Because a simple model gives us a clean baseline, which is the first meaningful score we compare everything else against. Think of it like using a plain map before trying a GPS with extra features; the plain version tells you whether you are even heading in the right direction. If a simple model performs well, we may not need anything more complicated. If it performs poorly, that result still teaches us something valuable: the pattern may be harder, the features may be weak, or the data may need more work.
Sometimes a linear model feels too limited, and that is where a decision tree can help. A decision tree is a model that asks a sequence of if-then questions, like “Is the value above this threshold?” and “Is the category equal to this option?” It is a friendly first tree because it is easy to explain to ourselves and easy to visualize. We can often see how it makes choices, which makes it useful when we want a balance between model performance and interpretability, meaning how easy it is to understand why the model made a prediction.
Not every first model should be chosen for accuracy alone. We also want to think about the size of the dataset, the number of features, and how much transparency we need. A small or medium-sized dataset often works well with simpler models, while a very noisy problem may tempt us toward more flexible ones later. If your project needs answers that people can trust and explain, a more interpretable model can be worth more than a tiny gain in score.
There is also a practical reason to begin with a modest machine learning model: it helps us catch problems early. A simple model can reveal missing labels, broken features, or a split that does not reflect the real world before we spend time tuning something expensive. It can also show whether overfitting is already lurking, which means the model is learning the training data too closely and struggling on new data. That early feedback is gold, especially when we are still learning the rhythm of the workflow.
So the first model we choose is really the first conversation we have with our data. We start with the easiest sensible option, check whether it learns anything useful, and then decide whether to stay with it or move toward something more flexible. That habit keeps machine learning grounded, and it turns model selection from a guessing game into a steady, thoughtful process.
Train and Evaluate It
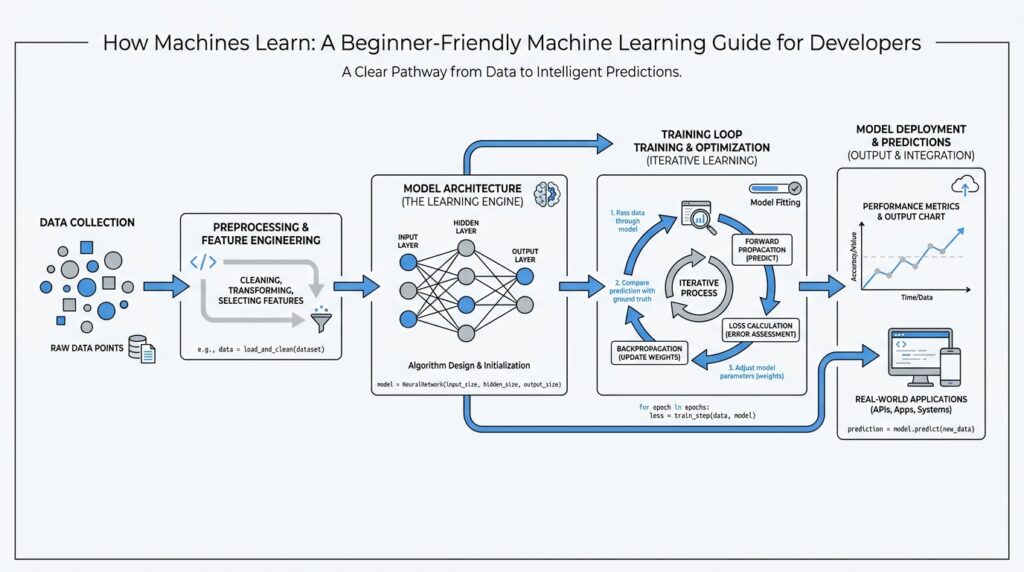
Now the model leaves the workshop and starts doing the real work of machine learning: train and evaluate. If you have ever wondered, how do you train and evaluate a machine learning model without fooling yourself? this is the part where the answer starts to feel concrete. Training is the phase where the model looks at the training set, adjusts its internal numbers, and tries to reduce its mistakes. Evaluation is the check afterward, where we ask whether those changes actually helped on data the model has not already studied.
Training usually happens in small loops that feel a bit like practice rounds. The model makes a prediction, compares it with the correct label, and measures how far off it was using a loss function, which is a formula that turns mistakes into a score the model can try to lower. Then an optimizer, meaning the rule that tells the model how to update itself, nudges those internal values in a better direction. One full pass through the training data is called an epoch, and that word matters because many models need several passes before they settle into a useful pattern.
As training moves forward, you start watching two stories at once. The first story is the training loss, which usually goes down as the model gets better at the examples it sees every day. The second story is the validation result, which tells you whether that improvement is real or just memorized. When training performance keeps improving but validation performance stalls or gets worse, the model may be overfitting, which means it is becoming too attached to the practice data and losing its ability to handle new cases.
That is why evaluation is not one number whispered at the end of the process. It is a set of clues that help you understand what kind of learner you built. In classification, accuracy tells you how often the model is right overall, while precision tells you how many of the model’s positive predictions were actually correct, and recall tells you how many real positive cases it managed to catch. Those terms can feel slippery at first, but they become easier if you imagine a spam filter: precision cares about false alarms, while recall cares about missed spam.
The trick is to choose a metric that matches the job you actually care about. A model can look strong on accuracy and still behave badly if one class appears much more often than another, because it may keep guessing the common answer and still seem impressive. That is why evaluation in machine learning is less about chasing the biggest score and more about asking whether the score reflects real usefulness. In some projects, a confusion matrix—a table that shows correct and incorrect predictions by category—can make the model’s behavior easier to see than a single percentage ever could.
As you train and evaluate, it helps to think like a careful coach rather than a cheerleader. We want to notice patterns, but we also want to notice warning signs early: training that improves too fast, validation scores that wobble wildly, or predictions that only work on one narrow slice of data. A good workflow often means making small changes, retraining, and rechecking the results instead of changing everything at once. That steady rhythm is what turns machine learning from guesswork into a thoughtful process.
When the model finally looks promising on the validation set, the test set gets its turn as the final judge. This last evaluation matters because it shows how the model behaves on truly unseen data, not on examples we used while making decisions. If the test result still looks healthy, we have a stronger reason to trust the model in the real world. And if it does not, that is not failure; it is useful feedback that tells us to revisit the data, the features, or the model itself before we move on.
Avoid Overfitting Early
When a first machine learning model starts looking impressive, it can be tempting to celebrate too soon. That is where overfitting can sneak in: the model learns the training examples too closely, like a student who memorizes practice questions but freezes when the exam wording changes. If you are wondering, how do I avoid overfitting in machine learning before it becomes a problem?, the answer starts with restraint. We want the model to learn patterns early, not memorize noise, because that early balance usually decides whether it will be useful later.
The easiest way to spot trouble is to watch the gap between training performance and validation performance. If the model keeps improving on the data it has already seen but starts slipping on validation data, it is telling us a clear story: it has begun to fit the training set too tightly. That does not always mean the model is broken, but it does mean we should slow down and listen. In machine learning, overfitting is often less dramatic than it sounds; it usually begins as a small mismatch that grows while we keep training and tweaking.
So what do we do first? We make the model earn its complexity. A simpler baseline often protects us better than an ambitious model with too many moving parts, especially when the dataset is small or noisy. We can also limit how flexible the model is by reducing depth, narrowing the number of features, or choosing a less expressive algorithm at the start. Think of it like teaching a child to recognize animals: we begin with the broad shape of the problem before asking them to notice every whisker and feather.
Data preparation matters just as much as model choice. If a feature is noisy, redundant, or only weakly related to the outcome, it can give the model too many excuses to memorize quirks instead of learning the real signal. That is why feature selection and careful preprocessing help so much early on. When we remove obvious clutter, the model has fewer chances to chase meaningless details, and machine learning becomes more about pattern recognition than pattern hunting.
Training discipline also plays a big role here. One of the most useful habits is early stopping, which means we stop training when validation performance stops improving, even if the training score still looks like it could climb. Another useful guardrail is regularization, a method that gently discourages the model from becoming too complex by adding a small penalty for overly large or numerous internal weights. Both techniques work like a speed limit: they do not stop learning, but they keep learning from turning into memorization.
More data can help too, but only if it adds variety rather than repetition. A model that sees many examples from the same narrow corner of the world may still overfit because it has not learned enough variation to stay steady when conditions change. That is why diverse examples, clean labels, and realistic validation data matter so much in machine learning. Overfitting early is often a signal that the model has had too much freedom and too little perspective.
The practical habit is to check often, change one thing at a time, and trust the validation set more than your excitement. Smaller steps make it easier to see what actually helped, and they keep you from overcorrecting in the wrong direction. A strong early workflow does not try to squeeze perfection out of the first pass; it tries to build a model that can still perform when the data stops looking familiar. That is the real test, and it is where a careful approach pays off.