Why Transformers Replaced RNNs
If you’ve ever watched a sentence unfold one word at a time, you already have the right picture for how recurrent neural networks, or RNNs, used to work in NLP. An RNN reads text in order and carries a running memory forward, which sounds natural at first because language itself arrives sequentially. The problem is that this same step-by-step habit becomes a bottleneck: each new token has to wait for the one before it, so training is harder to parallelize and slower on modern hardware. The original Transformer paper made this tradeoff visible by showing a model built entirely on attention, with better quality and much less training time than the recurrent systems that came before it.
That slowdown mattered because language rarely behaves like a neat little line of dominoes. In an RNN, information has to travel through a chain of hidden states, which are the model’s internal memory snapshots at each step, and that long chain can make distant words harder to connect. It is a bit like passing a rumor through several rooms: the message may survive, but the path is long and fragile. Transformers replaced that chain with self-attention, and a later evaluation paper notes that self-attentional networks can connect distant words through shorter network paths than RNNs. That shorter route is one of the biggest reasons transformers replaced RNNs in NLP.
Self-attention, which means each word can look at other words and decide which ones matter, changes the whole mood of the computation. Instead of one narrow memory moving forward like a flashlight beam, the model gets to see the whole table at once and compare clues from different places in the sentence. That matters for tasks where context hides in several directions at once, because the model can weigh nearby and distant words together rather than hoping useful information survives a long march through time. In practice, this is why the Transformer feels less like a relay race and more like a group conversation where every token can listen before speaking.
So when people ask, “Why did transformers replace RNNs for NLP?”, the answer is not that RNNs were foolish or broken. It is that transformers made the learning process easier to scale, faster to train, and better suited to the way today’s language systems are built and deployed. Once we can process many tokens in parallel, we spend less time waiting on sequential steps and more time learning useful patterns from data. That shift is what turned the transformer from a clever idea into the architecture that reshaped modern language processing.
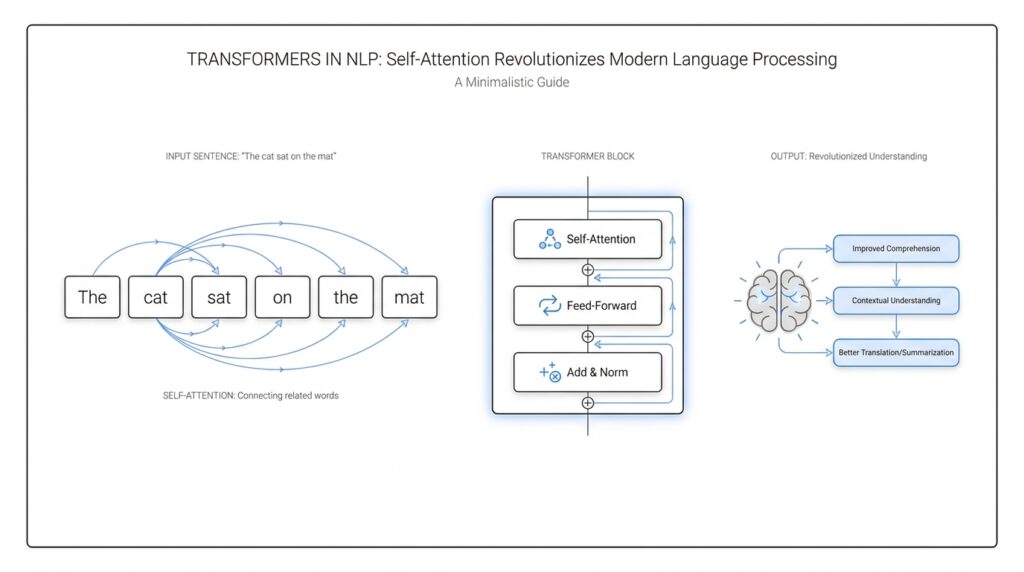
How Self-Attention Works
When a Transformer reads a sentence, self-attention is the part that lets every token compare notes with every other token. That sounds abstract at first, but the idea is very human: if we hear one clue, we naturally look back at the rest of the sentence to see what it belongs with. In the Transformer paper, this mechanism is described as relating different positions in a single sequence so the model can build a representation of the whole sentence. That is the heart of self-attention in NLP.
The easiest way to picture it is to imagine each word walking into a room with three name tags: a query, a key, and a value. A query is what a token is looking for, a key is what it offers as a match, and a value is the information it will pass along if it matters. The model compares the query against all the keys, turns those comparisons into weights with softmax, and then forms a weighted sum of the values. So when people ask, “How does self-attention work in a Transformer?”, the answer is that each token learns how much attention to give every other token before updating itself.
The next piece is the scaling factor, which keeps those comparisons from getting too sharp too quickly. In scaled dot-product attention, the model takes dot products between queries and keys, divides by the square root of the key size, and then applies softmax to get attention weights. The original paper says this scaling helps prevent large dot products from pushing softmax into tiny-gradient territory, which would make learning harder. In plain language, it keeps the model from getting overconfident too early, like a student circling an answer before checking all the clues.
Once we have that basic mechanism, multi-head attention adds another layer of perspective. Instead of letting one attention pattern do all the work, the Transformer projects the same input into several smaller spaces and runs attention in parallel across those “heads.” The paper found this useful because different heads can focus on different kinds of relationships at the same time, such as grammar in one head and long-range meaning in another. It is a bit like a group of editors reading the same draft, each with a different specialty, and then combining their notes into one cleaner version.
This is also where the idea becomes especially powerful for language. Because every token can look directly at every other token in the sequence, self-attention gives the model a short route for connecting distant words, rather than forcing information to travel through a long recurrent chain. The Transformer paper notes that this reduces the number of sequential operations and shortens the path between positions compared with recurrent layers. In NLP, that means the model can connect words that are far apart in the sentence without waiting for them to pass through many intermediate steps.
But there is one catch: self-attention alone does not know order. If we shuffled the tokens and gave the model no clue, it would see relationships but not sequence, so the Transformer adds positional encodings to the input embeddings. The original paper uses sine and cosine functions at different frequencies, specifically to give the model a sense of where each token sits and to help it reason about relative positions. That small addition is what lets self-attention stay flexible without becoming blind to word order.
In the decoder, there is one more careful rule: tokens are not allowed to peek ahead. The model masks out illegal future positions so each prediction can depend only on earlier tokens, preserving the auto-regressive setup used for generation. That detail may feel fussy, but it is what keeps the Transformer honest when it writes one token at a time. Once you see these pieces together, self-attention starts to feel less like magic and more like a disciplined way for NLP models to read, compare, and decide all at once.
Positional Encoding and Token Order
Once self-attention can look across an entire sentence at once, one quiet problem remains: how does it know which token came first, which one came next, and which one belongs at the end? That is where positional encoding steps in. Without it, a Transformer would see what words are present, but not where they sit, and token order is the difference between “dog bites man” and “man bites dog.” So when we ask, “How does positional encoding help a Transformer know word order?”, we are really asking how the model gets a sense of sequence without the step-by-step machinery that RNNs used to provide.
The original Transformer handles this by adding positional encodings to the input embeddings at the bottom of the encoder and decoder stacks. An embedding is a learned vector that represents a token’s meaning, and the positional encoding is a second vector that carries location information; because they have the same dimension, the model can add them together. That design is elegant because it keeps meaning and position in the same “sentence” the model can read at once, like writing both a word and its line number on the same note card. In other words, the Transformer does not trade away order to gain parallelism; it restores order with a separate signal.
For that signal, the paper uses sine and cosine functions at different frequencies. Each dimension of the positional encoding follows a sinusoid, and the wavelengths grow in a geometric pattern from short to long scales. That means nearby positions stay related in a smooth way, while far-apart positions still leave distinct traces across the vector. The authors chose this form because they expected it would make relative positions easier to learn, since a fixed offset between positions can be expressed as a linear function of the encoding at another position.
That idea matters because language is not only about absolute slots like “the third word in the sentence.” Often, the model needs to notice relationships such as “this noun is two words before that verb” or “the opening phrase reaches across the clause.” Sinusoidal positional encoding gives the Transformer a stable coordinate system for those relationships, almost like a ruler laid across the sentence. It lets self-attention compare tokens by content and then interpret those comparisons with a sense of distance and order.
The authors also tried learned positional embeddings, which are position vectors the model learns from data instead of generating with a formula. In their experiments, the learned and fixed versions performed about the same, but they kept the sinusoidal version because it may generalize better to sequence lengths longer than the ones seen during training. That is a subtle but important point: positional encoding is not only about fitting the training set, but about helping the model cope when the sentence is longer than the examples it has already seen.
There is one more place where token order matters: the decoder. When the Transformer generates text, it must not peek at future tokens, so the model masks out illegal connections and preserves the auto-regressive setup. That mask works alongside positional encoding to keep generation honest, because the model needs both the right order and the right timing. Once we put those two ideas together, the picture becomes clear: self-attention gives the Transformer a wide view, and positional encoding gives that wide view a map.
Multi-Head Attention in Practice
Once we move from the idea of self-attention to the way a Transformer actually uses it, the design starts to feel more like a workshop than a single machine. Multi-head attention is the part that lets the model look at the same sentence through several different lenses at once, and that is what makes Transformer attention so flexible in practice. Instead of asking one attention pattern to carry every kind of meaning, the model divides the job into several smaller attention heads, each one free to notice a different relationship in the text.
The practical setup is surprisingly tidy. The model takes the same input and creates separate query, key, and value projections for each head, which means each head works with its own learned view of the sentence. A projection is just a learned linear transformation, or a way of remapping the numbers so the head can focus on a particular slice of the information. Because these heads run in parallel, the Transformer can compare many patterns at the same time without slowing down into a step-by-step process.
That parallelism matters because language rarely offers one clean clue at a time. One head might latch onto a subject and its verb, another might track a pronoun back to the noun it refers to, and another might notice that a nearby phrase changes the meaning of a later word. If you have ever reread a sentence and paid attention to different things on each pass, you already understand the intuition behind multi-head attention in practice. What is multi-head attention doing in a Transformer? It is giving the model several ways to read the same sentence before it decides what matters most.
The real payoff comes after each head finishes its work. The Transformer does not keep the heads separate; it concatenates their outputs, meaning it places the results side by side, and then sends that combined vector through one more linear layer. That final layer acts like an editor that blends the heads’ notes into a single coherent message. In other words, the model first explores the sentence from several angles, then recombines those perspectives into one representation that the next layer can use.
This design helps because different heads often learn different kinds of patterns. Some heads become good at local syntax, which is the grammar around nearby words, while others learn longer-range dependencies, which are relationships between words that sit far apart. The point is not that every head becomes perfectly human-readable or neatly specialized, but that the collection of heads gives the model a richer set of clues than one attention map could provide on its own. That is one reason multi-head attention appears in so many modern NLP systems: it turns a single broad lookup into a small committee of focused readers.
There is also a practical trade-off hiding inside that convenience. More heads do not automatically mean a better model, because each extra head uses memory and compute, and too many heads can fragment the representation into pieces that are too small to be useful. Designers have to balance the number of heads against the hidden size, which is the width of the model’s internal vectors. That balance is part of what makes Transformer attention feel engineered rather than magical: it works because the pieces fit together cleanly, not because we keep adding more of them.
In the decoder, multi-head attention shows up in two different jobs. One set of heads handles masked self-attention, which keeps the model from looking ahead while it generates text, and another set handles cross-attention, which lets the decoder look back at the encoder’s output when the task involves an input sequence such as a source sentence in translation. Cross-attention is the bridge between “what we have written so far” and “what we are trying to produce next.” Once you see that pattern, the architecture becomes easier to picture: one part reads broadly, another part writes carefully, and multi-head attention helps both sides stay in sync.
So in practice, multi-head attention is less about multiplying complexity and more about distributing attention across several useful viewpoints. It gives the Transformer room to notice syntax, meaning, and distance at the same time, then compress those discoveries into a single working representation. That combination is what makes the mechanism so effective in real NLP systems, and it sets us up to look at how those representations support whole tasks like translation, summarization, and text generation.
Encoder-Decoder Architecture
Now that we have seen how self-attention lets tokens look around a sentence, the next question is how a Transformer turns that ability into a full language system. The encoder-decoder architecture is the answer. It splits the job into two cooperating parts: the encoder reads the input and builds a rich internal picture, while the decoder uses that picture to produce the output one token at a time. If you have ever wondered, “How does the encoder-decoder architecture work in a Transformer?”, the simplest answer is that one side understands and the other side speaks.
The encoder is the first room in this story. It takes the source sequence, which is the text we start with, and passes it through a stack of layers that repeatedly refine each token’s representation. At every layer, self-attention helps the encoder decide which other words matter, and the feed-forward network, a small neural network applied to each position, sharpens those representations further. By the time the encoder finishes, it has not memorized the sentence word for word; it has turned it into a dense map of meaning, context, and relationships that the decoder can later consult.
That map is what makes Transformer encoder-decoder architecture so useful for tasks like translation, summarization, and question answering. These problems are not about labeling a sentence in place; they are about transforming one sequence into another sequence. The encoder handles the reading part without worrying about output order, and that freedom lets it look at the whole input at once. In practice, this is like having a careful editor read the entire page before any new sentence is written.
Then the decoder steps in, and its job feels more delicate. It generates the target sequence token by token, which means it must predict the next word from the words it has already produced. To stay honest, it uses masked self-attention, a form of attention that hides future tokens so the model cannot peek ahead. That mask matters because generation has to happen in time order; the decoder should sound like it is writing, not cheating.
But the decoder does not work alone. In the middle of each decoder layer, cross-attention lets it look back at the encoder’s output, which is the encoded source sentence. Cross-attention means the decoder asks, “What parts of the input are relevant to the word I am trying to produce right now?” That bridge is the heart of the sequence-to-sequence setup: the encoder provides context, and the decoder uses that context to choose the next token with more confidence. The architecture feels a little like reading notes from one room while drafting in another.
Training this system has its own rhythm. During training, we usually feed the decoder the correct previous target tokens, a practice called teacher forcing, which means the model learns from the true sequence instead of only from its own guesses. The target sequence is shifted so the model predicts each token from the earlier ones, and the loss function, a measure of prediction error, tells the network how far off it was. This setup helps the encoder and decoder learn together, because the decoder gradually learns how to lean on the encoder’s representation at the right moments.
There is also a subtle design advantage here. Because the encoder and decoder are both stacks of attention-based layers, the Transformer encoder-decoder architecture stays flexible enough to handle long inputs without the sequential bottleneck that slowed older recurrent models. At the same time, it keeps generation disciplined by separating reading from writing. That separation is one reason the Transformer became so effective in NLP: it gives us one part that understands the source deeply and another part that turns that understanding into fluent output.
So when we put the pieces together, the architecture starts to feel very natural. The encoder builds a context-rich summary of the input, the decoder generates output one token at a time, and cross-attention ties the two halves into one coherent system. With that foundation in place, we can next see how the model is trained to assign probabilities to the right next words and make those predictions improve over time.
Pretraining and Fine-Tuning
When we finally reach the training stage, the Transformer starts to feel less like a clever architecture and more like a student with a long apprenticeship. Pretraining means the model first learns from huge amounts of unlabeled text, where “unlabeled” means the text does not come with answers attached, and fine-tuning means we then adapt that same model to one specific job with labeled examples. If you have ever wondered, how does a Transformer go from reading the internet to answering questions? this two-step path is the bridge. In BERT, for example, the model is first built to learn general language representations, and then it is reused for downstream tasks with only small task-specific changes.
The first stage is the long one, and it teaches the model the shape of language before we ask it to solve anything specific. BERT’s pretraining uses a masked language model (MLM), which means we hide some tokens and ask the model to predict them from context, and it also uses next sentence prediction (NSP), which asks whether one sentence really follows another. That combination matters because language understanding is not only about guessing words; it is also about learning how sentences connect. In the original paper, BERT masks 15% of tokens at random, so the model has to learn from the surrounding words instead of copying the answer from the input.
What we get from that stage is a reusable foundation rather than a brittle trick for one benchmark. The model learns deep bidirectional representations, which means it can use both the left and right context of a word at the same time, instead of reading only from left to right. That is why pretraining feels so powerful: we are not teaching the model a single task yet, we are teaching it grammar, word choice, sentence relationships, and a broad sense of meaning all at once. In the BERT paper, this broad pretraining is what makes the model strong enough to transfer cleanly to question answering, language inference, and many other NLP tasks.
Then fine-tuning enters like a tailor adjusting a suit after the cloth has already been woven. We start from the pretrained weights, add only a small output layer for the task at hand, and train on labeled data such as question-answer pairs or classification labels. The BERT authors emphasize that the architecture changes very little between pretraining and fine-tuning, and that all parameters are updated during fine-tuning, not just the last layer. That is the key practical advantage: instead of learning language from scratch each time, we reuse the same language knowledge and teach the model how to aim it at a new problem.
This is also why pretraining and fine-tuning became the default recipe for many NLP systems. Compared with pretraining, fine-tuning is relatively inexpensive, and the BERT paper reports that many of its downstream results could be reproduced in about an hour on a Cloud TPU or a few hours on a GPU. That matters because real-world datasets are often much smaller than the web-scale corpora used for pretraining, so the model needs a head start before it can learn efficiently from limited labeled examples. In plain terms, pretraining teaches the language; fine-tuning teaches the assignment.
There is one more lesson hidden here: pretraining is not magic, and the recipe still matters. RoBERTa later showed that BERT had been significantly undertrained and could match or exceed later systems when trained longer, with bigger batches, and on more data, while also changing details like the masking strategy. That tells us the Transformer story is not only about the architecture; it is also about how we prepare the model before the task-specific lesson begins. Once we understand that, we can see why modern NLP often treats the pretrained model as a foundation and fine-tuning as the careful last mile that turns general language skill into useful behavior.



