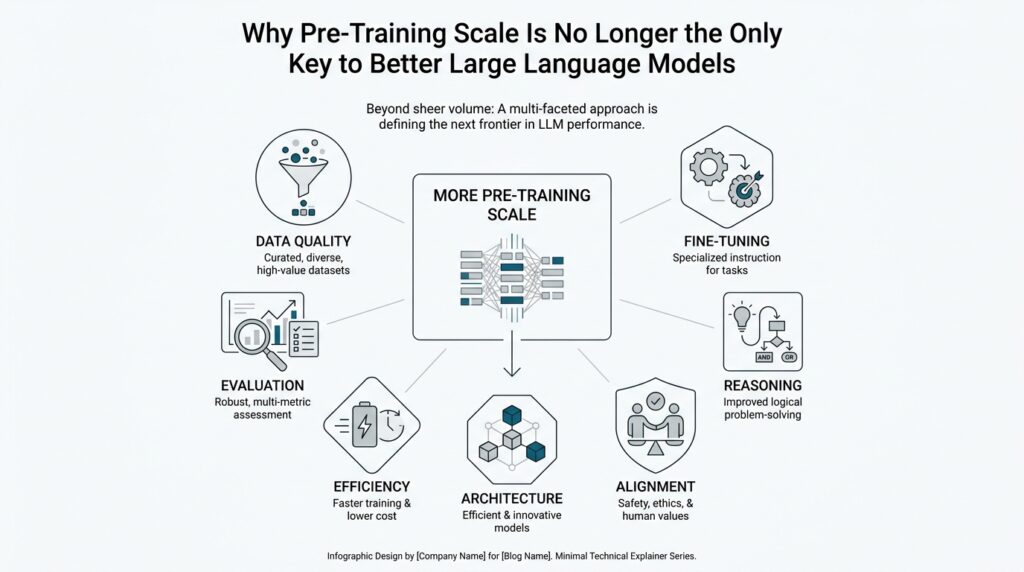
The Limits of Bigger Models
When we first meet large language models, it is tempting to think they grow wiser in the same way a library grows wiser: add more books, and knowledge keeps expanding. That is the promise of pre-training scale, the stage where a model learns from enormous piles of text before it ever chats with a person. But the story changes when the model gets very large, because size starts to bring new tradeoffs instead of unlimited gains. If bigger models keep improving, why doesn’t everyone keep scaling them forever?
The first limit is that growth gets expensive in a way that is hard to ignore. A large language model is a system trained to predict and generate words, and its size is often measured by the number of parameters, which are the internal values it adjusts while learning. More parameters can mean more capability, but they also demand more data, more electricity, more hardware, and more time. At some point, each extra improvement costs far more than the last, like buying a bigger truck to carry one more box.
Then there is the problem of diminishing returns, which is a fancy way of saying that the next step forward often becomes smaller than the last. Early scaling can unlock obvious jumps in fluency, reasoning, and general knowledge, but later scaling may add polish rather than a whole new level of usefulness. A model can sound better, yet still miss what a user actually needs: a careful answer, a reliable instruction, or a response that stays grounded. So the question is no longer, “Can we make it larger?” but “Will larger still be the smartest path?”
Another limit shows up when we look at quality, not just quantity. Pre-training scale teaches patterns from the internet and other text sources, but the internet is messy, repetitive, biased, and sometimes wrong. A bigger model can absorb more of that mess along with the good material, which means sheer volume does not guarantee better judgment. In that sense, scaling up can feel like pouring more water into a bucket with a small hole: we gain more input, but we do not automatically get cleaner output.
This is also where alignment starts to matter. Alignment means shaping a model so its behavior matches human expectations, instructions, and safety boundaries. A larger model may be more capable, but capability alone does not make it more cooperative, more truthful, or more consistent. In fact, as models grow, we often discover that they can become more impressive at generating text while still being awkward at following intent, refusing unsafe requests, or admitting uncertainty.
There is another practical limit hiding behind the scenes: bigger models are often harder to use well. They can be slower to run, more difficult to deploy, and more costly to serve at scale, especially when many people want fast answers at once. For teams building products, that matters as much as raw benchmark scores. A model that is slightly smaller but faster, cheaper, and easier to control may outperform a giant model in the real world, even if the giant model wins on paper.
So the shift we are seeing is not a rejection of size; it is a recognition that size alone does not finish the job. Once pre-training scale reaches its limits, the next gains often come from better data, better training methods, better post-training, and better ways to guide the model after learning. In other words, the road forward is no longer a single straight climb upward. It becomes a broader path, and that is where the next set of improvements starts to open up.
Why Data Quality Matters More
When we step past the limits of size, the next question becomes much more practical: what if the model is learning from the wrong material? Data quality means the usefulness, accuracy, and consistency of the training text a model sees, and once pre-training scale stops delivering big jumps, this becomes the real lever. A model does not become wiser because it sees more words; it becomes wiser because it sees better words, in better proportions, with fewer mistakes. That is why the conversation shifts from “How much data can we add?” to “What kind of data are we feeding the model?”
Think of pre-training like teaching a child by placing books in front of them all day. If those books are clear, trustworthy, and varied, the child learns patterns that help in many situations. If the books are noisy, repetitive, and full of half-truths, the child still learns—but not always the lessons we wanted. Large language models work in a similar way, which is why training data quality often matters more than raw volume once the model is already large enough to absorb patterns effectively.
This is where the difference between quantity and quality starts to feel real. A huge pile of text can include duplicate pages, outdated claims, spam, boilerplate, and low-value chatter that teaches the model little besides repetition. Large language models are pattern learners, so they absorb whatever appears often enough, whether that pattern is helpful or not. If the training mix overweights weak sources, the model may sound fluent while still being shaky on facts, style, or reasoning.
So what does better data actually change? It changes the signal the model learns to follow. Clean, well-curated data gives the model clearer examples of how people ask questions, explain ideas, structure arguments, and answer carefully. It also reduces the chance that the model memorizes contradictions or picks up habits we do not want, such as overconfidence, messy formatting, or repetitive phrasing. In other words, data quality improves not only what the model knows, but how it learns to behave.
That is also why people working on model improvement spend so much time on curation, which means selecting and organizing training data with care. They may remove near-duplicates, filter out low-quality text, balance topics, and favor sources that are more accurate or more useful. This work can sound less dramatic than training a model on billions of new words, but it often produces a larger real-world gain. The reason is simple: better examples create better habits, and better habits matter every time the model responds.
Here is the part that many beginners find surprising: more data can sometimes make a model worse if the extra data is poor. That is the hidden cost of chasing scale alone. Once a model has enough breadth, the next improvement often comes from sharpening the training signal rather than widening it endlessly. If you are wondering, “Why does data quality matter more than pre-training scale?” the answer is that learning from fewer but better examples often beats learning from many sloppy ones.
We can see the same pattern outside AI, too. A coach who gives a player thousands of careless drills does not help as much as a coach who gives fewer drills with precise feedback. The repetition matters, but the feedback matters more. Training data quality works the same way for models: it shapes not just what they can recall, but how reliably they can use what they have learned. That is why the next gains increasingly come from more thoughtful data, not merely more data.
And once we start thinking this way, the path forward looks very different. Instead of asking how to make the pile larger, we ask how to make the pile cleaner, sharper, and more representative of the behavior we actually want. That shift opens the door to better training recipes, better filtering, and better post-training methods, which is where the story keeps moving next.
Post-Training Changes Everything
Once the model has learned the broad shape of language, post-training becomes the moment where we teach it how to behave like a useful assistant. This is the part of the journey that turns a fluent text generator into something that can follow instructions, stay on task, and sound less like a clever autocomplete engine. What changes when a model already knows language, but still needs to learn how to be helpful? That is where post-training starts to matter more than raw scale, because it shapes how the model uses what it already knows.
The first step is usually supervised fine-tuning (SFT), which means training the model on examples of good answers written by people or carefully prepared by trainers. You can think of it like showing a talented student a stack of model essays before asking them to write their own. The student already understands the subject, but now they can see the format, the tone, and the kind of answer humans actually want. OpenAI’s InstructGPT work and Meta’s Llama 2 paper both describe this kind of post-training as a core part of turning a base model into a chat model.
From there, the story gets more interesting because humans do not only want answers; they want better answers. That is why many post-training pipelines add reinforcement learning from human feedback (RLHF), a method where people compare model outputs and the model learns from those preferences. In plain language, the model is not only shown one good answer; it is also told which of two answers people prefer, and that preference becomes a training signal. OpenAI’s InstructGPT paper says this approach helped produce models that people preferred over a much larger GPT-3 model, even with far fewer parameters.
This is the point where alignment starts to feel real rather than abstract. Alignment means shaping the model so its behavior matches human intent, helpfulness, and safety boundaries. Post-training helps because a model can be broad and knowledgeable yet still miss the social side of the job: answering carefully, refusing harmful requests, or admitting uncertainty. Anthropic’s Constitutional AI work follows the same basic logic, using supervised and reinforcement-learning phases to train a harmless assistant through feedback and revision.
Another reason post-training changes everything is that it can unlock behavior the base model already had, but could not reliably show on its own. OpenAI notes that this stage uses much less compute and data than pretraining, yet it can make the model much easier to steer in practice. That matters because product teams do not live on benchmark scores alone; they need models that are predictable, fast enough, and useful on real prompts from real people. A slightly smaller model with strong post-training can beat a larger model that sounds impressive but does not cooperate when it counts.
So when we ask why pre-training scale is no longer the only key to better large language models, the answer is that the final shape of the model is now being decided after pretraining, not just before it. Post-training gives us a way to refine behavior, improve helpfulness, and tighten safety without endlessly chasing bigger training runs. It is the difference between owning a grand piano and learning how to play a song people actually want to hear. That shift is why the next gains increasingly come from better post-training recipes, not only from bigger pretraining runs.
Reasoning at Inference Time
Have you ever stared at an answer that feels too quick to trust? That is where reasoning at inference time enters the story. Inference time is the moment a trained model is already in use, answering your prompt, and test-time compute is the extra work it does before speaking. Instead of blurting out the first likely response, the model can pause, explore, and check itself. OpenAI and Google DeepMind both describe this shift as letting models think longer before responding, and that extra thinking can improve performance on hard tasks.
What does that extra thinking look like? One common version is chain-of-thought reasoning, which means the model works through intermediate steps before it gives the final answer. In newer reasoning models, that process happens internally, so you do not need to coach the model with a “think step by step” prompt every time. OpenAI’s docs and releases describe these models as designed to reason internally and spend more effort on complex tasks, which is why they often handle planning, math, coding, and messy instructions better than a fast one-shot response.
Sometimes the best way to understand reasoning at inference time is to picture a hiker at a fork in the trail. A rushed hiker picks one path and hopes for the best; a careful hiker checks a few routes before committing. That is the idea behind self-consistency, a decoding method that samples multiple reasoning paths and then selects the answer that shows up most consistently across them. The original paper reported sizable gains on reasoning benchmarks, and DeepMind’s later work on Universal Self-Consistency showed the same basic pattern: multiple sampled paths can outperform a single greedy guess.
When the problem is more like a maze than a fork, models can go a step further. Tree of Thoughts is a framework where the model explores several branches, evaluates them, and backtracks if needed, instead of following one straight line. DeepMind’s SELF-DISCOVER work pushes a similar idea by letting models assemble task-specific reasoning structures from smaller modules such as step-by-step thinking and critical thinking. In plain language, the model is not only answering; it is searching for a better way to answer. That is why reasoning at inference time often helps on tasks that need planning, search, or careful comparison.
This is also where the tradeoff becomes real. More inference-time reasoning usually means more latency, more tokens, and more compute, so the answer may arrive a little later. But the payoff can be worth it: OpenAI reports that more inference-time compute can improve robustness, and that performance on its o-series models keeps climbing when the models are allowed to think longer. So the question is not only “Can the model answer?” but “How much thinking should we let it do before it answers?”
That shift matters because it changes what we expect from a large language model. Pre-training gives the model knowledge and fluency, but reasoning at inference time helps it apply that knowledge with care, especially when the prompt is ambiguous, the stakes are high, or the path to the answer is not obvious. In other words, the model is no longer winning by memory alone; it is winning by using its attention, search, and self-checks well in the moment. And once we see that, we start to understand why better models are now defined as much by how they think at answer time as by how much they learned ahead of time.
Retrieval and Tool Use
Once a model can speak fluently, the next problem is not grammar but access. Retrieval and tool use give a large language model a way to reach beyond what it memorized during pre-training, so it can look up fresh information, check private documents, or call a helper service when memory alone is not enough. In practice, this is the idea behind retrieval-augmented generation, or RAG, which injects outside context into the prompt at runtime instead of asking the model to rely only on its baked-in knowledge. OpenAI’s docs describe the same pattern for file search and web search: the model can pull in relevant files or current web results before it answers.
The key shift is that retrieval turns knowledge into something the model can visit instead of something it must permanently remember. How does retrieval and tool use help a model if the model already knows so much? The answer is that many useful questions live outside the training set, including company policies, product updates, and recent events. With file search, OpenAI describes a workflow where files are uploaded to a vector store, split into chunks, converted into embeddings, and then searched by semantic meaning and keywords at answer time. That means the model can stay general while the knowledge base keeps growing in a controlled, searchable way.
This matters because retrieval changes the quality of the answer, not just the quantity of text behind it. The original RAG paper showed that retrieval-augmented models can outperform purely parametric systems on knowledge-intensive question answering, which is a formal way of saying that the right passage from outside the model can beat a larger memory footprint. OpenAI’s help center makes the same point in plain language: RAG is especially useful when the answer depends on content that is not part of the model’s training data. In other words, retrieval gives the model a flashlight, not a bigger backpack.
Tool use goes one step further, because sometimes the model needs to do more than look things up. Function calling, also called tool calling, lets the model ask your application to run an external action, such as querying a database, calculating a value, or checking a calendar. OpenAI describes this as a multi-step conversation: the model requests a tool, your app executes it, and the result comes back into the next model turn. Toolformer research points in the same direction, showing that a model can learn when and how to call APIs, which helps it use external tools without losing its general language ability.
That is why tool use feels so different from pre-training alone. Pre-training gives the model broad pattern recognition, but tools let it behave more like a careful assistant that can check its work before speaking. The ReAct paper formalizes this pattern by interleaving reasoning and acting, so the model can plan, retrieve, update its plan, and handle exceptions in the same loop. OpenAI’s WebGPT work followed a similar path with browser-assisted question answering, showing that using a web browser plus human feedback can improve factual accuracy on open-ended questions.
The practical payoff is that retrieval and tool use make models more grounded, more current, and more useful in real workflows. OpenAI’s web search docs note that web search can return sourced citations, and that agentic search with reasoning can keep searching when the task is complex, though that extra effort usually takes longer. That tradeoff is the heart of the shift: we accept a little more orchestration so the model can produce answers that are tied to evidence instead of floating free. Seen that way, the model is no longer only a writer; it becomes a coordinator that knows when to look, when to call, and when to answer.
Measure Real-World Performance
After we add better data, smarter post-training, reasoning at inference time, and retrieval or tool use, we still face the question that matters most: does the model help real people do real work? Benchmarks can tell us a lot, but real-world performance is the moment the model leaves the lab and starts answering messy, incomplete, emotional, or high-stakes prompts. That is where large language models stop being a research object and start being a product. If a model looks stronger on paper, why can it still feel disappointing in practice?
The answer is that benchmark scores and lived experience are not the same kind of evidence. A benchmark is a fixed test, like a practice exam with known rules and cleanly worded questions. Real usage is more like a busy kitchen during dinner service, where the order comes in half-finished, the customer changes their mind, and the clock keeps ticking. A model can perform beautifully on a narrow test set and still stumble when the prompt is vague, the context is long, or the user expects it to remember the conversation from five turns ago.
That is why measuring real-world performance usually starts with task-based evaluation instead of abstract accuracy alone. We ask whether the model can complete the job people actually want: write the email, summarize the document, answer the support question, or help debug the code. In this setting, usefulness becomes a composite of several things at once, including correctness, instruction following, tone, and consistency. A model that gets the facts right but ignores the user’s intent is still failing the task, even if a benchmark gives it credit.
Human judgment becomes especially important here, because many of the qualities we care about are hard to compress into a single number. People can notice whether an answer feels grounded, whether it admits uncertainty, and whether it stays on topic when the prompt gets tricky. That is one reason model teams often use paired comparisons, where reviewers choose which of two answers is better, rather than asking them to assign an absolute score. Those comparisons can reveal subtle differences that automatic metrics miss, especially for open-ended large language models.
Production metrics add another layer, because a model does not live in isolation once it reaches users. We also need to watch latency, which is the time it takes to produce an answer, along with cost, refusal rate, and the number of times a user has to ask again. A model that answers brilliantly but slowly can still feel worse than a slightly less elegant model that responds quickly and reliably. In real-world performance, speed and stability are part of usefulness, not side issues.
This is where online testing, often called an A/B test, becomes valuable. In an A/B test, we show different model versions to different groups of users and compare how they behave in the real product. That gives us evidence from actual traffic, not just from controlled evaluation data, which makes the results feel more honest and less polished. If the newer model leads to fewer follow-up questions, happier users, or more successful task completion, we learn something that no isolated benchmark could fully reveal.
The most useful measurement systems also look for failure modes, because real-world performance is not only about average quality. A model may be excellent most of the time and still fail in predictable ways, such as when the prompt is ambiguous, the request is safety-sensitive, or the answer depends on current information. Those edge cases matter because users often remember the one time the model sounded confident and wrong. In practice, we are not only measuring how well the model performs when everything goes right; we are measuring how gracefully it handles the moments that go wrong.
That shift changes how we think about progress. Better large language models are not defined only by bigger training runs or higher benchmark scores; they are defined by how well they serve people in the situations that matter. Real-world performance keeps us honest, because it asks whether the model is actually useful, not merely impressive. And once we start measuring that directly, the conversation moves from raw capability to dependable behavior, which is where the next improvements really begin.



