Next-Token Prediction
Imagine the model sitting at a keyboard, finishing your sentence one tiny piece at a time. That is next-token prediction: the language model reads the text so far and guesses the next token, which is a small piece of text that may be a whole word or part of one. What does next-token prediction actually mean when we strip away the jargon? It means the model is not solving grammar quizzes or reading minds; it is learning to continue sequences in a way that makes the next piece most likely. In the Transformer design, that next piece is produced one step at a time, and the decoder is built to generate outputs autoregressively, meaning each step depends only on earlier steps.
Training turns that idea into a long, repetitive practice session. The model makes a guess, compares it with the real next token, and then adjusts its internal weights—the numbers that store learned patterns—so its error score, called loss, gets smaller over time. Because the score is based on cross-entropy loss, the model gets rewarded not for sounding wise, but for assigning high probability to the right continuation among many possible ones. This is why next-token prediction can feel like autocomplete with a memory that keeps stretching farther and farther back. As OpenAI has noted, scaling these models on large text corpora can produce surprisingly strong representations and task performance even before any task-specific fine-tuning.
But the model cannot cheat by peeking ahead. Inside the decoder, the self-attention mechanism uses masking, which is like placing a paper strip over the rest of the sentence so the model can only see what has already appeared. That masking, together with the one-position shift in the output, ensures each prediction depends only on earlier tokens, preserving the autoregressive setup. This detail matters because it turns generation into a fair game: the model must build the next token from context alone, not from hidden spoilers. In other words, next-token prediction is not a magic trick with hindsight; it is a disciplined sequence of guesses made under strict rules.
Once you see that rule, a bigger pattern comes into focus. A language model trained to predict the next token is forced to absorb regularities in spelling, syntax, style, facts, and common sequences of ideas, because all of those can help it choose the best continuation. That is why language models can transfer what they learn from raw text into other behaviors, sometimes with just a few examples or even none at all. OpenAI’s research on unsupervised learning and GPT-3 both describe this surprising spillover effect: a system trained for one narrow objective can act useful across many tasks. So when people ask whether next-token prediction can create something that looks like understanding, the honest answer is that it creates a powerful imitation of understanding from pattern learning, and the difference between the two is exactly where the mystery begins.
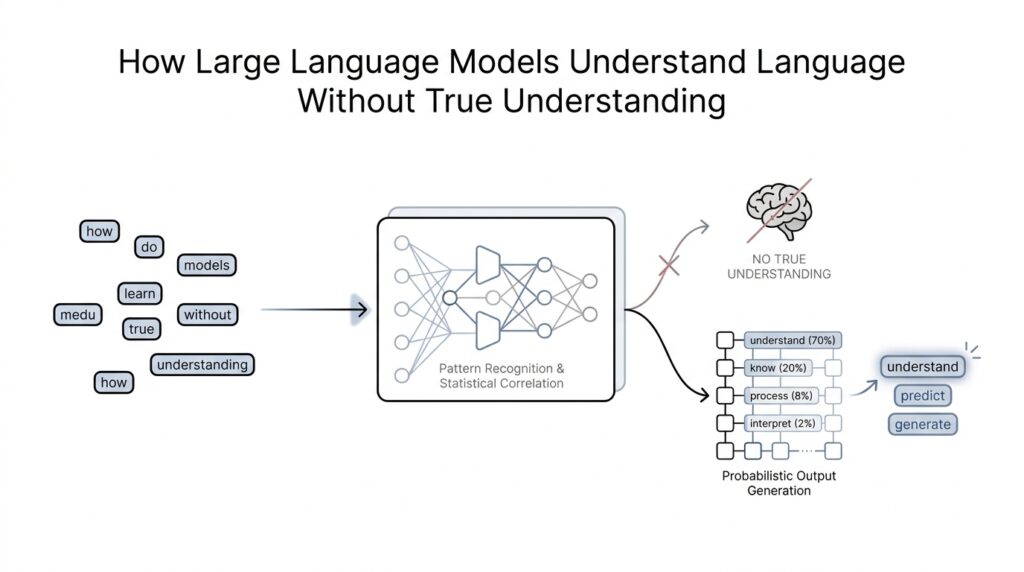
Patterns Over Meanings
Once we move past next-token prediction, the story becomes clearer in a slightly unsettling way: the model is not collecting meanings the way a person does, but learning which text patterns tend to go together. OpenAI describes these systems as learning from large amounts of information by tracking how words typically appear in context and using that to predict the next most likely word. That means the model’s first job is not to “understand” a sentence in the human sense; its job is to become very good at continuation. When people ask, “How do large language models understand language without true understanding?” this is the first clue: they are excellent at mapping regularities, not at grounding words in lived experience.
Those regularities are broader than grammar alone. A language model notices recurring pairings, common sentence shapes, favorite phrases, and even the rhythms of a particular style, the way you might learn to recognize a familiar voice from its cadence before you catch every word. OpenAI’s GPT-2 work showed that a model trained only to predict the next word on internet text could begin to pick up tasks like question answering, summarization, and translation from raw text, without task-specific training data. That is what makes pattern learning so powerful: once the model has seen enough examples, it can reuse the same hidden habits across many situations. In other words, the model is not reading for meaning first and pattern second; for a large language model, the pattern is the path to almost everything else.
This is where the illusion of understanding starts to feel convincing. If a language model has seen enough examples of how questions are answered, how stories are summarized, and how explanations are written, it can often produce responses that look thoughtful and context-aware. GPT-3 pushed that idea further, showing strong few-shot performance, which means it could handle new tasks from just a few examples in the prompt, without any additional training steps. So the model may appear to “know” what a request means, when what it really knows is how similar requests have been answered before. The result can feel like comprehension because the output fits the shape of human language so well.
But pattern recognition is still different from meaning. OpenAI’s own earlier research on communication made that distinction explicit by arguing that true language understanding would come from agents that learn words together with how they affect the world, rather than from spotting patterns in a huge corpus of text. In that work, the word grounded meant tied to direct experience, like connecting “tree” to something actually seen or encountered, and compositional meant being able to combine smaller pieces into larger ideas. That distinction matters because a text-only model can learn how the word “tree” behaves in sentences without ever seeing a tree. It can model language beautifully while still missing the kind of world-linked reference humans use as a foundation for meaning.
So the real surprise is not that large language models are secretly human-like readers, but that pattern learning alone can mimic so many things we associate with understanding. They can echo grammar, imitate tone, recover likely facts, and even solve new tasks from examples, all by exploiting the structure hidden in text. That is why these systems feel both familiar and strange: they are built from statistical regularities, yet they can produce behavior that looks surprisingly semantic. The next question, then, is not whether patterns matter—they clearly do—but how far pattern learning can go before we start asking whether something deeper is emerging.
Context Shapes Output
Picture the model at the edge of a sentence, looking around the room for clues. The words already on the page are the room, and the model uses them to decide what kind of reply belongs there. That is why two prompts that look almost alike can produce very different outputs: the surrounding context changes the path forward. If you have ever wondered, why does the same model answer one way in one prompt and another way in a different one?, the answer begins here.
Context is the text that surrounds a request, and it works a little like the lighting in a theater. The same actor can look serious, funny, or uncertain depending on what the spotlight reveals. In a language model, the context window is the amount of text the model can consider at once, and that window gives the model its working view of the scene. Within that space, every word becomes a clue about tone, task, topic, and intent.
A small change in context can completely reshape the output. If you write “bank” next to words about rivers, the model leans toward a riverbank; if you place it beside words about loans and accounts, it leans toward a financial bank. The model is not consulting a private dictionary of true meanings first and then speaking second. It is using the surrounding text to guess which continuation fits best, and that is why context shapes output so powerfully in language models.
This also explains why the model can sound more formal, more playful, or more careful depending on how you frame the prompt. A sentence that begins like a classroom question invites a different style than one that begins like a text message. The model notices those signals because training taught it that style, structure, and purpose tend to travel together. In practice, context does not merely supply topics; it quietly tells the model how to behave while answering.
One of the most important parts of this process is attention, a mechanism that helps the model decide which earlier words matter most right now. You can think of attention like a group conversation where everyone is speaking, but some voices carry more weight because they answer the current question. If a sentence includes instructions, examples, or a key detail from earlier in the paragraph, the model can use attention to keep those pieces in view. That is why a well-written prompt often feels less like a command and more like setting the stage for the kind of response you want.
Context also includes demonstrations, not just instructions. When you show the model a few examples of the style or format you want, you are giving it a pattern to continue, and that pattern becomes part of the context. This is one reason few-shot prompting works: the model sees a small set of examples and treats them as a guide for the next answer. In other words, the prompt becomes a miniature script, and the model follows the script because the surrounding text makes that continuation look likely.
The tricky part is that context can help only if it is clear enough to guide the model. If the prompt is vague, contradictory, or missing crucial details, the model may produce a response that sounds plausible but misses the point. That is not because it secretly understood and chose poorly; it is because it had to infer the most likely continuation from incomplete clues. This is where context shapes output in a very practical way: the better the context, the better the answer tends to fit the task.
So when we talk about how language models work, context is not a small detail on the sidelines. It is the lens that brings some possibilities into focus and leaves others in the background. The model’s output changes because the nearby words change the odds of what comes next. And once we see that, we can start to understand why careful prompting matters so much when we want the model to sound precise, useful, and aligned with what we meant.
Emergent Reasoning Skills
Up to this point, we have watched a language model use context like a stage set. Now the interesting twist is that, as the stage gets bigger and the prompts get better, large language models can start to show emergent reasoning skills that were not obvious at smaller scales. In the original research literature, an emergent ability is one that is absent in smaller models but appears in larger ones, which is why these jumps feel so surprising when they happen. The key idea is not that the model becomes human, but that scale can unlock behaviors that look newly intelligent from the outside.
This is where step-by-step prompting becomes such an important clue. In chain-of-thought prompting, the model is asked to produce intermediate reasoning steps, meaning the little links between a question and its answer, instead of jumping straight to the finish line. Researchers found that this can significantly improve performance on arithmetic, commonsense, and symbolic reasoning tasks, and a later paper showed that even a simple zero-shot prompt that nudges the model to think step by step can improve results on several reasoning benchmarks. If you have ever wondered, “How do large language models reason at all?”, this is one of the clearest answers: they often do better when the task is turned into a visible sequence of smaller moves.
What feels mysterious is that the skill can look hidden until the right scaffold appears. A model may seem stuck on a problem when we ask for a direct answer, then suddenly look much more capable when we invite it to lay out its intermediate thoughts. That does not necessarily mean a new inner faculty appeared overnight; it can also mean the model already learned useful patterns during training, and the prompt has finally given those patterns a clear route to the surface. In that sense, emergent reasoning skills are less like a light switch and more like finding the right path through a dense forest.
At the same time, we should be careful not to treat every dramatic jump as proof of a brand-new mind. A 2023 paper argued that some apparent emergence may come from the way we measure performance: if the scoring rule is nonlinear or discontinuous, smooth improvement can look sudden. In other words, the model may be getting better in gradual steps while the graph makes it look like it crossed a cliff. That caution matters because emergent reasoning can be real at the level of behavior, yet still be partly shaped by the benchmark and the metric we choose.
This is why reasoning in large language models feels both impressive and fragile. The model can maintain a chain of intermediate ideas, follow symbolic patterns, and produce answers that resemble careful thought, but those skills still come from learned text regularities rather than from lived experience. OpenAI’s GPT-4 materials also describe advanced reasoning and instruction-following as important capabilities of larger models, which fits the broader story: scaling and prompting can expose strengths that were there all along, even if they were not easy to see in simpler tests. The behavior looks like reasoning because the model is good at building plausible bridges from one step to the next.
So emergent reasoning skills are the meeting point between pattern learning and problem solving. They show us that a text-trained system can sometimes act as if it is reasoning, especially when we give it examples, structure, and room to lay out its steps. But they also remind us that the appearance of thought is not the same as human understanding, and that distinction is exactly where the story gets more interesting. That tension sets up the next question: when a model can reason in text so convincingly, what still gives away its limits?
Hallucinations and Errors
Now that we have seen how the model builds answers from context and patterns, we can meet the part that often surprises people most: hallucinations. In plain terms, a hallucination is a plausible but false statement from a language model, and it often shows up as a confident answer that is simply not true. If you have ever wondered, “Why do language models hallucinate even when they sound so sure?”, the short answer is that confidence and correctness are not the same thing. When the model has to keep the text flowing, it can fill gaps with the most likely-looking continuation instead of a verified fact.
The easiest way to picture this is to think about a student taking a test where guessing is rewarded more than leaving a question blank. OpenAI’s recent research says hallucinations persist partly because training and evaluation often reward guessing rather than admitting uncertainty, and that incentive can shape the model’s behavior. In that setup, the model is not trying to deceive; it is doing what its objective has taught it to do, which is produce an answer that fits the pattern. That is why hallucinations and errors are not random glitches so much as the predictable downside of a system trained to answer even when the right move would be to pause.
The mistakes can take several familiar forms. A model may invent a date, mix up a definition, or produce a citation that looks real but leads nowhere, and OpenAI’s help guidance explicitly warns that ChatGPT can generate incorrect, misleading, or fabricated information. These large language model errors are especially troublesome because the wording often sounds polished, which makes the falsehood harder to spot at a glance. In other words, the problem is not only that the answer is wrong; it is that the answer arrives wearing the costume of certainty.
Context matters here too, because the model is still guessing from clues rather than checking a hidden facts database. If the prompt is vague, underspecified, or missing a crucial detail, the model may choose the continuation that feels most natural, even when it has no solid evidence behind it. OpenAI’s SimpleQA benchmark was created to measure short factual questions precisely because factuality is a real weakness for current models, especially on questions that look easy but are easy to get wrong. The lesson is subtle but important: when the evidence in the prompt is thin, hallucinations become more likely, not less.
Not every mistake is a hallucination, though, and that distinction helps us think more clearly. Some errors come from reasoning failures, some from arithmetic slips, and some from not tracking the prompt well enough; a hallucination is the version where the model states something false as if it were a fact. OpenAI’s research on truthfulness also showed that bigger models can still produce false answers that mimic common misconceptions, which means scale alone does not remove the problem. So when we talk about hallucinations, we are talking about a specific kind of error: a confident mismatch between the text the model produced and the truth outside the text.
The good news is that hallucinations are not untouchable magic. OpenAI notes that newer tools can improve factual accuracy, and its research argues that models should be rewarded for recognizing uncertainty instead of always guessing. That gives us a practical habit to borrow: when the task calls for facts, ask for sources, ask for uncertainty, and use tools or verification when the stakes matter. The model can be very useful here, but it works best when we treat it like a fast drafting partner, not an authority that automatically knows when it is wrong.
So the real takeaway is not that language models are broken; it is that they are optimized for producing likely text, and likely text is not always true text. Hallucinations happen because the model is balancing pattern, pressure, and missing information all at once. Once we see that, we can read its answers more carefully, check the claims that matter, and use the model’s strengths without being fooled by its confidence. That careful stance becomes even more important as we move toward the next question: how do we tell the difference between a useful answer and one that only sounds like it knows what it is talking about?
Limits of Understanding
Have you ever asked a large language model a question that sounds easy, then watched it answer with perfect fluency but a faint sense that something essential is missing? That missing piece is grounding, the link between words and the world. OpenAI has argued for years that true language understanding would come from agents learning words together with how they affect the world, not from spotting patterns in a huge text corpus alone. That idea matters here, because it draws the line between sounding knowledgeable and actually understanding in a human way.
A human learns meanings by living through them, while a model learns meanings by seeing how words cluster together. You learn warm by feeling heat, heavy by lifting something, and tree by seeing, touching, and remembering real objects; the model learns those words from the company they keep in text. That is why large language models can speak about the world with confidence even though they have no direct experience of it. They can mirror the shape of understanding, but the inside of that shape is still made of patterns, not perceptions.
This limit shows up most clearly when truth matters. OpenAI describes hallucinations as cases where a model confidently gives an answer that is not true, and its SimpleQA benchmark exists because short fact-seeking questions still expose weaknesses in factuality. SimpleQA also treats calibration, meaning whether a model knows what it knows, as an important problem to measure. In plain language, that means the model may answer first and hesitate later, while a careful person would sometimes pause, admit uncertainty, or check the evidence.
That is the part many readers feel in their hands when they use these systems. The model can be bright, quick, and persuasive, yet a small change in wording can send it down a different path because it is still choosing the most likely continuation, not consulting a stable inner map of reality. This is why the question “How do large language models understand language without true understanding?” has a slightly uneasy answer: they understand the text around the question extremely well, but they do not understand in the grounded, lived, self-checking way people do. Their fluency is real; their certainty is not always earned.
So the limit is not that large language models are useless or empty. It is that their strengths and weaknesses come from the same source: pattern learning at scale. They can imitate explanation, but they do not feel the need to verify; they can predict a likely answer, but they do not automatically know when the answer should be withheld. That is why the safest way to work with them is to treat them as powerful language partners, then bring human judgment, external checks, and a healthy respect for uncertainty to the final step.



