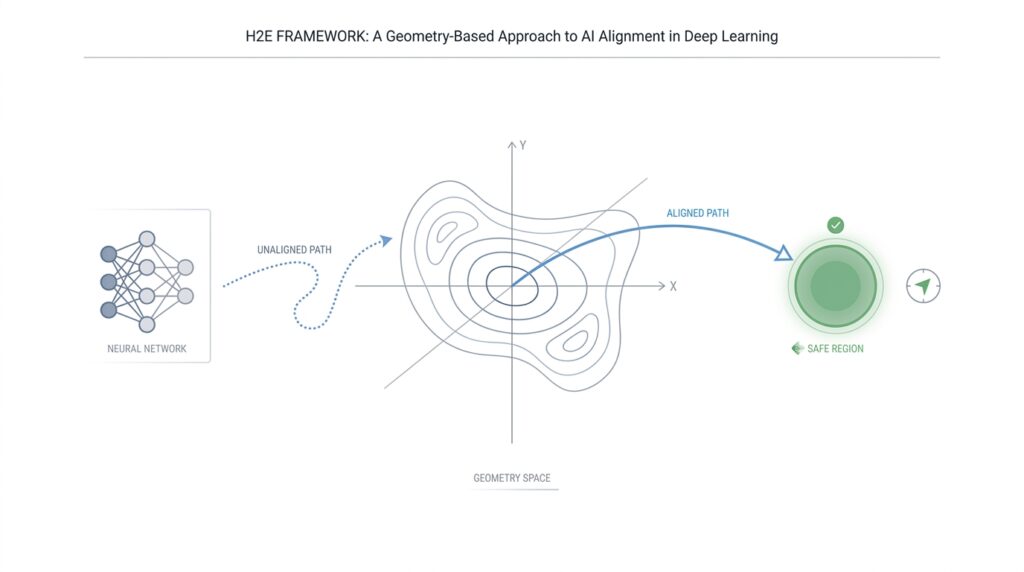
H2E Framework Overview
Imagine you have a model that can answer quickly, but you still do not fully trust where its answer came from. The H2E framework steps into that gap by presenting itself as a Human-to-Expert approach: a way to turn probabilistic, black-box AI into deterministic, verifiable, expert-aligned behavior. In the published materials, H2E is described as reproducible, accountable, and designed to keep decisions tied to human intent rather than random model drift.
That is where the geometry-based idea starts to matter. In deep learning, the feature space is the internal landscape where a model organizes what it has learned, and research on feature-space geometry shows that this landscape can be studied in terms of manifolds, curvature, and robustness rather than only raw predictions. H2E borrows that intuition: instead of thinking about AI alignment as a vague moral label, we can think about it as keeping the model inside a shaped region of possibilities, where expert knowledge defines the safe path.
If you are wondering, “What does a geometry-based AI alignment framework actually do?” the answer is that it tries to make the model’s route visible. The H2E materials describe a fusion of symbolic directives with a physical or causal world model, so the system can compare what an expert wants with what the model believes is feasible. That idea lines up with JEPA, a Joint-Embedding Predictive Architecture, which learns by predicting latent representations instead of raw outputs, and with broader neurosymbolic alignment work that combines neural learning with symbolic rules for clearer guidance and explanation.
Seen that way, H2E is less like a single model and more like a guided corridor. The framework’s own description says expert intent acts as a guardrail, while feasibility checks and conflict resolution keep the system from drifting into unsafe or physically impossible responses. That is a powerful mental image for beginners: alignment is not a magical after-the-fact patch, but a constraint system that keeps the model’s motion inside a meaningful shape, much like train tracks keep a train on course.
The practical promise is easy to feel even before the technical details settle in. If the model can show where expert intent enters, where the world model objects, and where the final decision is formed, then the whole process becomes easier to inspect, debug, and trust. The H2E materials emphasize determinism, auditability, and expert accountability, so the framework reads as an attempt to make AI alignment legible in the same way a map makes a route legible.
That is why the H2E framework matters as an overview concept: it gives us a shared language for talking about deep learning, geometry, and alignment in one picture. We are not just asking whether a model is smart enough; we are asking whether its internal geometry can be shaped so that expert knowledge, causal feasibility, and final action all point in the same direction.
Geometry Behind Alignment
When we turn from the broad H2E idea to the geometry behind it, the picture gets more concrete. Instead of treating alignment as a vague promise, we can imagine the model’s feature space—the internal coordinate system where it organizes what it learns—as a landscape with shapes, bends, and pathways. Reviews of feature-space geometry in deep learning discuss manifolds, curvature, critical points, and adversarial robustness, which gives us a language for describing where a model moves well and where it becomes unstable.
That matters because the geometry of alignment is really about keeping related things close and unrelated things apart. In manifold learning, the common assumption is that data sampled in a high-dimensional space often lies on a lower-dimensional submanifold, and studies of object manifolds in deep networks show that training can improve separability while reducing dimensions, radii, and correlations. If that sounds abstract, think of folding a messy map into a route the model can actually follow.
This is where the H2E-style idea starts to feel practical. A Joint-Embedding Predictive Architecture, or JEPA, learns by predicting target representations in latent space rather than reconstructing raw pixels, and the CVPR I-JEPA paper describes that setup as predicting representations of target blocks from a context block. In plain language, the model is asked to understand the scene before it is asked to paint every detail, which makes latent geometry a better place to place alignment constraints.
Once we think in latent space, the role of expert intent becomes easier to picture. A neurosymbolic approach combines neural learning with symbolic logic, and the alignment paper on neurosymbolic AI argues that this fusion can guide learning and provide clearer explanations. For H2E, that means expert rules can act like geometric pins: they do not replace learning, but they give the learned representation a shape to settle into.
The next layer is feasibility. If expert intent says, “move here,” but the world model says that move breaks a physical or causal rule, then geometry gives us a place to detect the conflict instead of hiding it inside a black box. That is an inference from the combination of manifold-aware deep learning, latent prediction, and neurosymbolic reasoning: alignment becomes a matter of comparing paths through representation space, not merely scoring final answers.
This is why geometry-based AI alignment is more than a metaphor. It lets us ask whether the model’s internal route stays inside the region defined by expert knowledge, whether its latent moves remain smooth enough to inspect, and whether any jump away from the route can be traced back to a specific conflict. That gives H2E a useful promise: when the shape is visible, alignment is easier to debug, easier to audit, and easier to improve one constraint at a time.
Build the Latent Space
When we start building the latent space, we are really giving the H2E framework a place to think. A latent space is the model’s internal map of meaning: instead of storing words, images, or sensor readings in their raw form, deep learning compresses them into coordinates that capture what matters most. That sounds technical, but the picture is familiar. It is like turning a crowded city of details into a subway map, where the lines matter more than every building above ground. In geometry-based AI alignment, that map becomes the stage where expert intent, model belief, and world constraints can finally meet.
The first job is to choose what should count as “nearby.” In a good latent space, things that belong together should sit close together, and things that should not be confused should stay apart. That is why representation learning matters here: the model is not only memorizing examples, it is learning a coordinate system for meaning. If you are asking, “How do we build a latent space that supports alignment?” the answer begins with structure. We shape the representation so that similar situations produce similar vectors, while unsafe or impossible situations drift into clearly different regions.
From there, we give expert intent a form the model can recognize. A human expert rarely thinks in raw numbers, so the H2E framework has to translate intent into the same representational language as the model. Think of it as teaching two people to point at the same place on a map. The expert’s rules, preferences, and goals become signals in latent space, not as rigid labels pasted on top afterward, but as geometry that nudges the model toward the right neighborhood. That is what makes the H2E framework feel less like a filter and more like a shaped environment.
The next step is to make the space responsive to reality. A world model, which is a learned internal model of how the environment behaves, acts like a reality check inside the map. If expert intent says one thing and the world model says another, the latent space should expose that disagreement instead of hiding it. This is where geometry-based AI alignment becomes useful: the conflict can show up as distance, distortion, or an impossible jump in the representation. The model is not being asked to guess in the dark; it is being asked to move through a space that has rules.
To build that space well, we also care about smoothness. A smooth latent space lets small changes in input lead to small, understandable changes in representation, which makes the system easier to inspect and less likely to lurch into strange behavior. Deep learning can create very tangled internal maps, so the H2E approach tries to keep the terrain navigable. You can imagine walking across a hill rather than crossing a field of hidden holes. If the landscape is continuous, then alignment checks become easier because we can trace how the model moved, not only where it ended up.
This is also where training becomes more than simple optimization. We are not only teaching the model to predict; we are teaching it where to place those predictions in relation to expert guidance and causal feasibility. The latent space becomes a negotiation between attraction and restraint, between what the expert wants and what the world can support. That is a subtle but important shift in deep learning: the representation itself becomes part of the alignment mechanism. In other words, we are not bolting safety on later. We are building the geometry so that safer paths are the natural ones.
Once that internal map is in place, everything downstream becomes easier to reason about. We can inspect which regions encode trusted behavior, which ones signal conflict, and where the model needs more supervision. That is the real promise of building the latent space in the H2E framework: it gives us a shared surface where intent, evidence, and action can be compared before the model commits to a decision. And once that surface exists, the next question is no longer whether the model can move, but how we guide its movement with precision.
Add Alignment Constraints
Now that the latent space has a shape, we can begin placing alignment constraints on it. This is where geometry-based AI alignment becomes concrete: we are no longer hoping the model will stay on the right path, we are drawing the path itself. If you have ever wondered, how do we add alignment constraints without making the model brittle? the answer starts with treating the model’s internal space like a map with boundaries, lanes, and checkpoints rather than an open field.
An alignment constraint is a rule that limits where the model is allowed to move. In plain language, it is a guardrail inside the representation space. Some constraints protect expert intent, some protect feasibility, and some protect consistency between them. We do not add them to punish the model; we add them to help it stay coherent. That makes the H2E framework feel less like a correction mechanism and more like a well-marked trail, where the safest direction is also the most legible one.
The first kind of constraint comes from expert intent. Here, we translate what a human expert wants into a geometric signal the model can feel. Instead of attaching the rule after the fact, we anchor it in the latent space so the model learns to move toward regions that match the intended behavior. Think of it like placing a magnet on the map: the model does not lose freedom, but it now has a preferred direction. In geometry-based AI alignment, that preferred direction matters because it turns vague guidance into a shape the system can actually follow.
The next kind of constraint comes from feasibility. Expert intent can be wise, but it can still ask for something the world cannot support. A world model, which is the model’s internal sense of how reality behaves, helps catch that mismatch early. This is where alignment constraints become especially useful, because they let us compare the expert’s desired path with the path that physics, causality, or task structure will tolerate. We are not asking the model to choose between two opinions; we are asking it to stay inside a space where both intent and reality can coexist.
To make those constraints work during training, we usually need more than one signal. A model may receive a penalty when it drifts away from expert-aligned regions, a reward when it stays close to them, and a stronger penalty when it crosses into infeasible territory. Those signals act like invisible fences, but fences that still leave room for movement and learning. In practice, this is what makes alignment constraints different from hard-coded rules: they guide the model continuously, instead of freezing it at a single answer.
This layered setup matters because alignment is rarely one-dimensional. The model may be correct in a technical sense but still violate expert preference, or it may echo the expert beautifully while ignoring what the world makes possible. By separating these checks, we can see exactly where the disagreement begins. That is one of the quiet strengths of the H2E framework: alignment constraints do not hide conflict, they reveal it in a form we can inspect, compare, and refine.
As the constraints settle into the latent space, the model’s behavior becomes easier to read. You can trace why one decision felt stable, why another drifted, and where a rule tightened the path. That gives us a practical advantage in geometry-based AI alignment: the model’s movement is no longer a mystery wrapped inside a score. It becomes a structured journey, and once we can see the structure, we can shape it with much greater care.
Train With Geometric Losses
When the latent space is already shaped and the guardrails are in place, training becomes the part where the model learns the path by walking it over and over. That is where geometric losses come in: they are loss functions, meaning the numeric penalties a model tries to minimize during training, but they measure distance, direction, and separation inside the model’s internal map. If you have been asking, how do geometric losses help with geometry-based AI alignment?, the short answer is that they teach the model not only what to predict, but how to arrange its understanding.
The idea is easier to feel if we imagine the model as a traveler on a map. A normal training signal might say, “That answer was wrong,” but a geometric loss says, “You moved too far from the expert-aligned region,” or “You drifted toward a point that should stay separate.” In other words, geometric losses turn alignment into a spatial problem. Instead of treating every mistake as the same kind of mistake, we can measure whether the model is too close, too far, or pointing in the wrong direction.
That matters because H2E-style training wants expert intent to become part of the model’s structure, not a thin layer pasted on top. So we use the geometry of the latent space to create attractive and repulsive forces. Aligned examples are pulled together, conflicting examples are pushed apart, and borderline cases are kept at a safe margin so the model does not blur them into the same neighborhood. This is where geometric losses feel different from ordinary penalties: they shape the landscape itself, which makes geometry-based AI alignment more stable and easier to inspect.
The most useful part is that these losses can speak several geometric languages at once. Distance tells us how far one representation sits from another. Angle tells us whether two directions agree or conflict. Margin tells us how much breathing room the model should preserve between safe and unsafe regions. When we combine those signals, the model receives a richer training story: not just “be correct,” but “stay close to the right kind of correctness.”
Training then becomes a careful dialogue between representation and supervision. The model produces an embedding, which is a compressed internal vector that captures meaning, and the geometric loss compares that embedding with expert anchors or feasibility targets. Backpropagation, the process that sends error information backward through the network so the weights can adjust, carries that geometric message into the model’s parameters. This is the moment when abstract alignment becomes concrete learning, because the model changes its internal structure to reduce the spatial mismatch we have pointed out.
The nice part is that geometric losses can also reveal when the alignment story is getting messy. If expert intent and world feasibility keep pulling in different directions, the loss surface may become crowded, and the model may hesitate near the boundary instead of committing to a clean region. That is not a failure of the method; it is useful feedback. It tells us where the geometry-based AI alignment problem is still unresolved, which gives us a place to refine the constraints, rebalance the weights, or add better examples.
At the same time, we do not want the training to become so strict that the model loses flexibility. If every region is over-policed, the model can collapse into a space that is tidy but not useful, the way a map with too many fences stops being a map and starts feeling like a cage. Good geometric losses keep the space organized without freezing it. They leave enough room for the model to generalize, while still making expert-aligned regions the most natural places to land.
So training with geometric losses is really about teaching the model a habit of movement. We are guiding its internal geometry so that aligned states become easier to reach, unsafe states become harder to justify, and conflicts show up early enough to correct. Once that habit is learned, the next question is less about whether the model can find the right answer and more about how confidently we can trace the route it took to get there.
Evaluate Alignment Drift
When we reach this stage, the comforting part is over and the real question begins: how do we know the model is still staying on course as conditions change? That is what alignment drift is really about—the slow slide between expert intent and the model’s internal behavior, even when the outputs still look polished on the surface. How do we know whether alignment drift is starting before the model says something obviously wrong? We look for the first signs in the model’s internal map, not only in its final answer.
The easiest place to start is the hidden layers, because those are the layers where the model’s meaning starts to settle into shape. Research on deep representations shows that semantically rich states often emerge in intermediate layers, and that their structure can be studied through intrinsic dimension—the number of coordinates needed to describe the data—and neighborhood overlap, which measures whether nearby examples stay near each other across layers. In plain language, if the model’s internal neighborhood suddenly rearranges, that is a clue that alignment drift may be underway even before the surface behavior becomes dramatic.
From there, we compare versions of the model over time, almost like laying two maps on top of each other and seeing where the roads no longer line up. In a geometry-based AI alignment setup, that means tracking whether embeddings—compact internal representations of meaning—stay close to expert anchors, or whether they begin to wander into new regions. JEPA-style models are especially useful here because they work in an abstract representation space and predict continuous embeddings rather than raw tokens, which gives us a cleaner place to watch for movement and evaluate whether the model is still thinking in the intended shape.
The next check is whether expert intent and world feasibility are still agreeing with each other. A neurosymbolic approach combines neural learning with symbolic, knowledge-guided rules, and that combination is useful because it supports clearer explanations and safety-constrained decision-making. So when we evaluate alignment drift, we do not only ask, “Did the answer match the expert?” We also ask, “Did the path to that answer stay compatible with the world model and the rules we trusted in the first place?” If those two layers begin to separate, we are watching the geometry of alignment loosen.
This is why drift evaluation should feel more like monitoring a compass than grading a quiz. A single wrong output can be noise, but a consistent shift in latent distance, neighborhood structure, or expert-world agreement tells us the model is changing its orientation. In practice, we are looking for three things at once: whether the representation is still compact enough to be readable, whether related cases still cluster together, and whether the expert-aligned regions are still the places the model naturally returns to. That combination gives geometry-based AI alignment its practical value, because it turns a vague worry into a visible pattern.
Once we can see that pattern, the response becomes much easier to reason about. Small drift may mean the constraints need tightening, the expert examples need refreshing, or the world model needs a better signal about feasibility. Bigger drift may mean the model has learned a shortcut that looks successful on the outside but has started to bend its internal geometry away from the intended route. That is the real payoff of evaluating alignment drift: we catch the wobble while it is still a wobble, not after it has become a new habit.
So, as we keep moving through the H2E workflow, the point is not to trust the model less—it is to watch it more carefully, with enough geometric detail to notice when the map starts changing under our feet. Once that becomes visible, we can decide whether the model needs correction, more structure, or a safer lane to follow next.