Why Precision Loss Matters
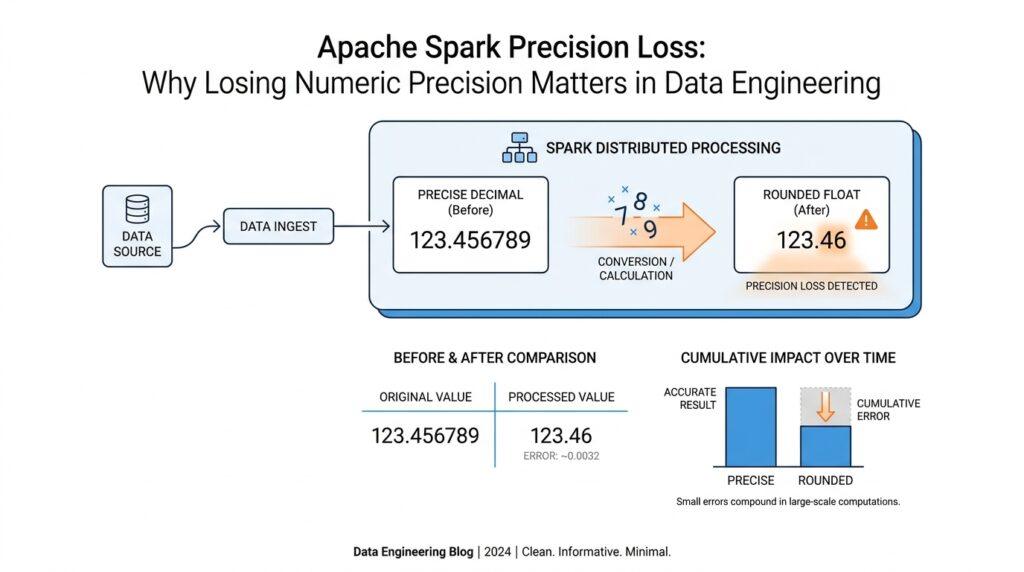
When you first run into Apache Spark precision loss, it can feel like the numbers are almost right, which is often the most dangerous kind of wrong. You may see a total that is off by a few cents, a ratio that shifts a little after a cast, or a threshold that behaves differently than you expected. In Spark, decimals are stored with a fixed precision (the total number of digits) and scale (the digits to the right of the decimal point), and Spark limits decimal precision to 38 digits. That means every time a value is squeezed into a smaller shape, we need to think about what gets kept and what gets trimmed away.
Why does losing a few decimal places matter in Spark? Because those small digits are often the difference between a number that is merely close and a number that is trustworthy. Think of precision like the number of seats in a theater and scale like how those seats are arranged on each row: if the theater is too small, some people do not fit, and if the rows are rearranged, the view changes. Spark’s decimal functions also make this visible, since round uses HALF_UP rounding, which means values are deliberately nudged to the nearest allowed place. That is fine when you expect it, but a silent round-off can become a real problem when you do not.
The impact shows up fastest when numbers drive business rules. A payroll total, a tax calculation, a shipping fee, or a financial balance can look harmless after one tiny adjustment, but repeated across many rows the error can grow into something you actually notice. In data engineering, that is the heart of precision loss in Spark: tiny distortions accumulate, and aggregation turns a small mismatch into a bigger one. What started as a harmless-looking cast can end up changing averages, totals, or rankings in a way that is hard to trace later.
Precision loss also matters because data pipelines do not treat every number as a loose suggestion. When a value exceeds the allowed decimal range, Spark can fail or reshape the value depending on the operation and configuration, and that difference changes how your pipeline behaves in production. Current Spark SQL docs say ANSI mode is enabled by default, and in that mode invalid casts and out-of-range numeric writes raise errors instead of quietly slipping through. When ANSI mode is off, decimal results can become null, which is even trickier because the pipeline may keep moving while the damage spreads.
That is why precision loss is not a cosmetic issue; it is a trust issue. Once a number has been rounded, truncated, or widened at the wrong moment, you may no longer be able to explain why two runs disagree or why one report no longer matches another. We are not just preserving digits here; we are preserving meaning, and meaning is what makes downstream decisions dependable. As we move forward, that is the lens to keep in mind: every cast, every rounding step, and every decimal choice can either protect your data or quietly erode it.
Spark Decimal Types Explained
When you first meet Spark decimal types, they can feel a little like moving from a sketch to graph paper. A decimal type is Spark’s way of storing exact base-10 numbers, which makes it useful for money, measurements, and other values where tiny binary wobble would be a problem. In Spark, this appears as DecimalType(precision, scale), where precision means the total number of digits and scale means how many of those digits live after the decimal point. That small pair of numbers carries a lot of weight, because it tells Spark how much room a value has before it needs to be rounded or rejected.
So what are we really choosing when we pick a decimal instead of a double or float? We are choosing exactness over speed and convenience. A double is a floating-point number, which is great for scientific work but can store values in a way that introduces tiny binary approximations; a decimal type stores the number as a precise base-10 value. If you have ever wondered, “Why does Spark decimal precision matter if the number looks fine on screen?”, this is the reason: what looks fine to your eyes may already be carrying hidden approximation behind the scenes, and decimal types are designed to reduce that risk.
The shape of a decimal value matters just as much as the value itself. Think of precision and scale like a wallet and the bills inside it: precision tells us how much total space we have, while scale tells us how many bills must be reserved for the cents. A value like 123.45 fits comfortably into DecimalType(5, 2) because it uses five digits total and two digits after the decimal point. But if we try to place 12345.67 into the same shape, Spark has to make a decision, and that is where Spark precision loss can begin to appear through rounding, truncation, or failure depending on the operation.
Spark also changes the type of decimal values as they move through calculations, and that is where the story becomes interesting. When you add, subtract, multiply, or divide decimals, Spark does not keep the exact same shape forever; it computes a new precision and scale based on the operation. That means a value can start as a neatly labeled DecimalType(10, 2) and end up with a wider or narrower result after a few steps. Decimal types in Spark are not just containers; they are active participants, and they influence how every downstream number is formed.
This is why choosing the right decimal type is part math, part planning. If you know a column will hold cents, you might use a small scale that keeps two digits after the decimal point. If you know a calculation will grow during multiplication or division, you may need extra precision so Spark does not squeeze the result too early. In practice, that means we are not only asking, “What is the number now?” We are also asking, “What will happen to this number after three joins, two casts, and one aggregation?”
The safest way to think about Spark decimal types is to treat them as a contract. You are telling Spark, “This number must stay exact within these limits,” and Spark will try to honor that contract as long as the value fits. Once you understand that contract, Spark precision loss becomes much easier to reason about, because you can see where the number is being protected and where it is being compressed. That understanding gives us a steadier foundation for the next question: what happens when Spark has to compare, cast, or combine these decimals in real pipelines?
Common Precision Loss Points
Most Spark precision loss shows up at the seams, where one number format hands off to another. If you have ever watched a value look perfect in a source table and then drift after a cast or a write, you have already met the usual suspects. Where does Spark precision loss usually sneak in? Most of the time, it hides at the points where Spark must choose between keeping an exact value and making that value fit a new shape, a new scale, or a new storage rule. In the current Spark docs, ANSI mode is on by default, so invalid casts and numeric overflows raise runtime errors instead of slipping through quietly, and storeAssignmentPolicy also defaults to ANSI for table inserts.
The first checkpoint is casting, the moment Spark reshapes a number to fit a new column. A CAST from one numeric type to another can run into overflow if the target type is too small, and under ANSI rules Spark treats those cases as errors instead of silent edits. That is why a value can look fine in a calculation and then fail the moment we try to place it into a narrower home. If you are asking, “Why did my number change after a cast?”, this is usually the place to look first.
The next hotspot is rounding itself. Spark’s round(expr, d) uses HALF_UP rounding, which means half-way values move to the nearest allowed digit rather than sitting on the fence. That sounds polite, but it can still erase the tiny detail you needed for a later threshold, comparison, or total. In practice, Spark precision loss often begins not with a broken value, but with a well-behaved rounding rule applied a little earlier than you expected.
A third choke point appears when Spark has to reconcile mixed numeric types. The ANSI type-precedence list runs from narrower types toward wider ones, and it ends at Double; Decimal sits before Float and Double, and Spark even skips Float when finding a least common type to avoid loss of precision. That means an expression that starts as exact decimal math can drift toward floating-point approximation if we mix it with double-typed values. Think of it like counting coins and then measuring them with a ruler: the answer may be close, but it is no longer the same kind of truth.
The last common pressure point is the handoff into tables and other stored outputs. Under ANSI store-assignment rules, Spark checks whether a value can safely fit the target column, and it raises an error when the value would overflow or require an unsafe conversion. That is why a number can survive a temporary expression but fail on insert: the pipeline has moved from “working with a value” to “promising the value will fit later.” If we want to avoid surprise failures, we have to pay close attention to the moment the data leaves the calculation and becomes committed storage.
So when we look for Spark precision loss, we are really looking for these narrow doorways: casts, rounding, mixed-type expressions, and writes. Those are the places where Spark asks a number to shrink, stretch, or change language, and that is where meaning can start to blur. The good news is that once you know these pressure points, the next step becomes much clearer: we can learn how to spot them before they reach production.
Casts, Joins, Aggregations
Once we move from a single column into casts, joins, and aggregations, Spark precision loss stops looking like a small formatting issue and starts acting like a chain reaction. You might cast a value so it fits one table, join it to a second table, and only notice the drift when the grouped total comes back a little off. Why does a join on decimal keys or a group sum suddenly feel less trustworthy than the row-level data you started with? Because Spark resolves numeric conflicts with a type-precedence ladder, and join conditions must still evaluate to boolean, so the number may be compared in a different shape than the one you began with.
Casts are the first doorway where Spark asks a number to change clothes. Spark exposes cast(expr AS type) as a conversion function, and under ANSI rules an illegal explicit cast raises a runtime exception instead of quietly returning a guess. That is why a value can look perfectly harmless in the source data and still fail the moment you try to squeeze it into a narrower decimal or integer slot. In practice, Spark precision loss often starts here, not because the number is wrong, but because the target box is too small.
Joins are more subtle, because they make two datasets agree on the meaning of the same key. If one side uses Decimal and the other side uses Float or Double, Spark applies its ANSI precedence rules to find a least common type, and the docs say the least common type between Decimal and Float is Double. That means the comparison may be promoted away from exact decimal math before the rows ever meet, which is a classic place for Spark precision loss to hide. The safest mental model is to treat join keys like passports: both sides need the same identity before they enter the same checkpoint.
Aggregations are where tiny differences gather a crowd. Spark’s built-in function list includes sum and avg, and it also includes try_sum and try_avg, which return NULL instead of throwing when overflow happens. That detail matters because an average or total does not live on one row anymore; it inherits every cast, every promotion, and every rounding choice that happened upstream. When Spark precision loss reaches an aggregation, the mistake no longer feels local, because one widened or rounded value can tilt the answer for an entire group.
So the practical move is to line up your types before the big handoff. Spark’s DecimalType supports fixed precision and scale, with precision up to 38 and scale no larger than precision, so you want enough headroom for the full path, not only the current column. If a join key or measure will be aggregated later, keep it in an exact decimal shape as long as the business rule depends on it, and delay any move toward wider approximate types until the end. That habit does not eliminate Spark precision loss, but it keeps the loss where you can see it.
When you read a pipeline this way, casts, joins, and aggregations stop feeling like separate features and start feeling like three doors in the same hallway. The question is no longer, ‘Can Spark store this number?’ but, ‘Where does Spark have to reinterpret it, and do we still trust the result after that reinterpretation?’ If we keep that question in front of us, we are much more likely to catch the silent shifts before they become the report we explain to someone else.
Safe Numeric Data Patterns
Now that we have seen where numbers can drift, the safer path starts looking less like a trick and more like a habit. In Spark, the most reliable pattern is to keep values in a fixed decimal shape for as long as the business rule still depends on exactness, because DecimalType stores a value as fixed precision and scale, with precision up to 38 and scale no greater than precision. That is the heartbeat of Spark decimal types: you give Spark a box that matches the meaning of the number, instead of asking it to guess later. If you have ever wondered, “How do I avoid Apache Spark precision loss before it starts?”, this is the first answer: choose the exact numeric type early and keep it stable.
The next safe pattern is to control the moment a number changes shape. Spark’s current ANSI behavior is important here: when spark.sql.ansi.enabled is true, invalid casts and numeric conflicts are handled through explicit rules, and spark.sql.storeAssignmentPolicy defaults to ANSI for table insertions, which means Spark prefers errors over quiet corruption. That sounds strict, but it protects you from the worst kind of Spark precision loss: the kind that looks successful until a report comes out wrong. So instead of letting the engine reshape values implicitly, we move casts to the edges of the pipeline, test them on purpose, and make sure every narrowing step is one we can explain.
Rounding deserves its own careful lane, because it can feel harmless while still changing the story a number tells. Spark’s round(expr, d) uses HALF_UP rounding, which means half-way values are pushed to the nearest allowed digit rather than preserved as-is. That is useful when you truly want a displayed amount or a billing value to settle on a clean boundary, but it is risky when a later comparison, threshold, or join still needs the original detail. The safe pattern is to delay rounding until the last possible step, so the calculation stays exact while the number is still doing real work.
Another pattern is to keep mixed numeric types from arguing with one another. Under ANSI type coercion, Spark chooses a least common type from a precedence list, and the docs note that Decimal and Float can be pushed to Double to avoid loss of digits; the least common type is also used for arithmetic operations and comparisons. That means a clean decimal column can drift toward approximation if we mix it with floating-point values in joins or expressions. The practical move is to normalize both sides first, so the comparison happens in the same exact language instead of one side quietly translating for the other.
Aggregations need one more layer of protection, because they collect tiny errors the way a river collects rain. Spark’s aggregate functions work across rows, and try_sum and try_avg return NULL on overflow instead of failing hard, which makes them useful as warning lights when a group is getting too large for the chosen type. A safer pattern is to widen the decimal type before the group operation if you expect growth, then check the result for unexpected nulls or boundary values after the fact. That gives you a clear signal instead of a mysterious mismatch in the final total.
So the practical rhythm is steady: keep exact decimals early, cast with intention, round late, align types before comparisons, and watch aggregations for overflow. Those habits do not remove Apache Spark precision loss entirely, but they do move it into places where you can see, test, and explain it. Once you start treating Spark decimal types as a contract rather than a convenience, the pipeline feels calmer, and the numbers keep telling the same story from one stage to the next.
Test for Precision Drift
The safest way to test for precision drift is to stop trusting the numbers that merely look right and start feeding Spark the awkward ones that sit on the edge. A DecimalType gives you exact base-10 storage with fixed precision and scale, and Spark allows precision up to 38 with scale no greater than precision, so the boundary is where a value either holds its shape or starts to bend. How do you test for precision drift in Spark before it slips into production? You build a tiny control set with boundary values, then watch what changes after each transformation, especially around rounding, because Spark’s round uses HALF_UP behavior.
The next step is to freeze your expectations before the pipeline has a chance to rewrite them. Write down the schema you want, then compare it with the schema you get, because Spark’s ANSI type-precedence rules can promote mixed numeric expressions toward wider types like Float or Double, which is exactly where exact decimal math can start to blur. A schema check is not paperwork here; it is a tripwire that tells you when a decimal quietly changed its shape.
In PySpark, assertSchemaEqual gives you a direct way to verify that the output still carries the structure you intended, and assertDataFrameEqual lets you compare rows with rtol and atol tolerances when you need to separate true drift from acceptable noise. For money, counts, and other exact values, keep those tolerances tight and make the expected schema explicit. If a cast widens a decimal, or a join key comes back as a floating-point value, the test should fail loudly instead of letting the difference wander downstream.
from pyspark.testing import assertDataFrameEqual, assertSchemaEqual
expected = spark.createDataFrame(
[(1, '12.34'), (2, '99.99')],
'id INT, amount DECIMAL(10,2)'
)
actual = run_pipeline(input_df)
assertSchemaEqual(actual.schema, expected.schema)
assertDataFrameEqual(actual, expected, rtol=0.0, atol=0.0)
That little pattern tells a clear story: the schema guards the contract, and the row comparison checks whether the contract survived the journey. It is especially useful when you are testing a cast, a join, or a write path that could push exact values into a different numeric family. Spark’s testing helpers are designed for this kind of validation, and they make it much easier to catch precision drift while the failure still has a name.
It also helps to run the same test with ANSI behavior enabled, because Spark then throws runtime exceptions for invalid operations instead of quietly returning null, and ANSI store-assignment rules reject unsafe inserts into table columns. That makes the test suite feel like an honest gatekeeper: if a value cannot survive the move into its target type, you learn that in the test, not after a report is already published. The newer Spark docs also show that storeAssignmentPolicy defaults to ANSI, which is why these checks matter so much during writes.
For aggregations, add one more checkpoint around overflow by testing try_sum and try_avg, which return NULL on overflow. When one of those helpers suddenly comes back null on a fixture that used to pass, you have learned that the group no longer fits the numeric shape you chose. That is a valuable signal, because precision drift is much easier to fix when your test shows the exact stage where the number stopped being the same number.