What Machine Learning Is
Imagine you have a notebook full of examples, and your job is to spot the pattern before anyone tells you the rule. That is the heart of machine learning: instead of programming every instruction by hand, we give a computer data and let it learn patterns from that data. If you have ever wondered, what is machine learning in plain English?, the short answer is that it is a way for computers to improve at a task by studying examples.
To make that feel less abstract, think about teaching a child to recognize animals. We do not hand over a formal definition first; we show pictures, name them, and let the child compare one example with another until the differences start to make sense. Machine learning works in a similar way. The computer looks at many examples, finds regularities, and uses those patterns to make a guess about something new it has never seen before.
That guessing step is important, because machine learning is not about memorizing facts like a dictionary. It is about learning a relationship between inputs and outputs. An input is the information we give the system, such as a photo, a sentence, or a list of numbers. An output is the result we want, such as identifying a cat, predicting the next word, or estimating a house price. In other words, machine learning turns examples into a useful model, which is the learned pattern the computer uses to make predictions.
Here is where the story gets interesting: the computer does not learn in a magical leap. It learns through training, which means repeatedly adjusting itself based on examples until its answers get better. During training, the system compares its guesses with the correct answers and nudges itself toward more accurate patterns. That is a bit like practicing piano with a tutor, where each mistake helps guide the next attempt.
Not all machine learning looks the same, though. Sometimes the computer learns with labeled data, meaning each example comes with the correct answer already attached, like photos tagged “dog” or “cat.” Other times it works with unlabeled data, meaning no answers are provided and the system has to discover structure on its own. Both approaches belong to machine learning, but they solve different kinds of problems and feel a little like different kinds of treasure hunts.
A helpful way to keep this grounded is to notice what machine learning can do well and where it can struggle. It can sort spam from email, recommend a movie, or estimate whether a transaction looks unusual. But it depends on the quality of the data it sees, because a model trained on shaky examples will often produce shaky predictions. That is why data matters so much: the system learns from the world we show it, not from a perfect version of the world.
Machine learning also explains why computers can seem surprisingly adaptable. A traditional program follows fixed rules written by a person, while a machine learning system builds some of its own rules from examples. That difference matters because many real-world problems are too messy for hand-written instructions alone. Language, images, and human behavior rarely fit neatly into if-this-then-that logic, so machine learning gives us a way to work with complexity instead of pretending it is simple.
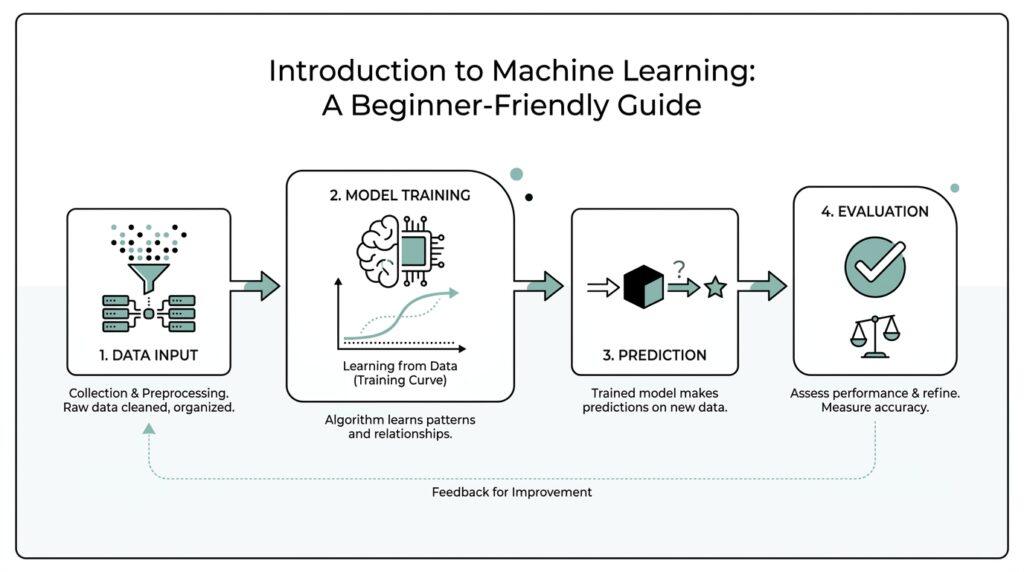
So when we say a computer is learning, we are not imagining it daydreaming at a desk. We mean it is finding patterns, refining a model, and using those patterns to make predictions on new data. That idea will keep showing up as we move forward, because once we understand how machine learning learns, the next steps start to feel much less mysterious.
Core ML Concepts
Now that we know machine learning learns from examples, the next question is the one most beginners ask: what are the core ML concepts that hold the whole thing together? The easiest place to start is with a dataset, which is just a collection of examples, and with the two roles inside it: features and labels. A feature is an input clue, like an age, a word, or a pixel pattern, and a label is the answer we want the model to learn to predict. In a table, each row usually acts like one example, while each column can become a feature or a label.
From there, we meet the model, which is the thing doing the learning. In supervised machine learning, a model is a collection of numbers that describes the relationship between input patterns and output values, and training is the process of refining those numbers with labeled examples. During training, the model makes a prediction, compares it with the correct answer, and updates itself based on the difference, which is called the loss. That loss is the model’s feedback signal, like a practice score that tells us whether it is getting warmer or colder.
This is also where the two big learning styles come into view. In supervised learning, we give the model labeled data, meaning the correct answer is already attached, so it can learn from examples that have a clear target. In unsupervised learning, we give it unlabeled data, and the goal shifts from “predict this answer” to “discover patterns,” such as grouping similar items together. What are the core ML concepts you keep hearing about? These two styles are often the first split because they shape everything that comes next.
Once the model starts learning, we need a fair way to check its progress, and that is where training, validation, and test sets enter the story. The training set is the data the model learns from, the validation set helps us make decisions while we are still tuning the model, and the test set gives us a final check on unseen data. Keeping those sets separate matters because a model can look impressive on the examples it has already seen and still stumble on new ones. Think of it like rehearsing for a play: practice, dress rehearsal, and opening night are not the same thing.
Behind the scenes, data quality can make or break the whole effort. Google’s machine learning guidance emphasizes that model performance depends heavily on both the quality and quantity of the dataset, and that raw data often needs to be transformed into floating-point numbers before training can happen. That transformation step is part of feature engineering, which means shaping raw information into inputs a model can actually use. It is a little like sorting ingredients before cooking: the meal depends not only on the recipe, but on how cleanly we prepare what goes into the pan.
The last piece to hold onto is generalization, which means a model does well on new data, not only on the data it practiced on. When a model performs strongly on training data but weakly on fresh examples, it has overfit, or in plain language, it has memorized the homework instead of learning the lesson. One common way to reduce that risk is to keep model complexity under control, because simpler models often generalize better than overly complicated ones. That idea will keep coming back as we move deeper into machine learning, because learning the pattern is useful only if the pattern still works when the world changes.
Types of Machine Learning
Now that we’ve seen machine learning learn from examples, the next question feels natural: what are the types of machine learning, and how do they behave differently in real life? The simplest way to picture them is to ask how much help we give the model. Sometimes we hand it the answers, sometimes we leave it to find patterns on its own, sometimes we give it a mix of both, and sometimes we let it learn through trial and error. That is the basic map most beginners use: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
Supervised learning is the most familiar place to start because the data comes with a guidebook attached. In supervised machine learning, labeled data means each example already includes the correct answer, so the model learns the link between the features and the label. That makes it a strong fit for tasks like classifying emails as spam or predicting a house price from details like size and location. If you’ve ever wondered, “What are the types of machine learning when I want the computer to predict something?”, supervised learning is often the first answer.
Unsupervised learning feels different because there is no answer key waiting in the data. Instead of predicting a known target, the model looks for structure, such as clusters of similar items or hidden relationships between examples. It is a bit like walking into a library with no labels on the shelves and trying to notice which books naturally belong together. This is why unsupervised learning is often used for grouping customers, finding patterns in behavior, or spotting unusual data points that stand out from the rest.
Semi-supervised learning sits in the middle, which makes it especially useful when labeling data is expensive or slow. Here, the model learns from a small set of labeled examples and a much larger set of unlabeled examples at the same time. You can think of it like learning a new language with a few annotated flashcards and then using a whole library of unlabeled books to build fluency. This approach keeps the structure of supervised learning while borrowing some of the scale and flexibility of unsupervised learning.
Reinforcement learning follows a completely different rhythm. Instead of studying labeled examples, an agent learns by interacting with an environment and receiving rewards or penalties for what it does. That makes it feel less like reading a workbook and more like practicing a game, where each move teaches the next one. Google describes this style as learning optimal behavior through trial and error, which is why people often use it for robots, game-playing systems, and other decision-making problems.
The useful part of learning these types is not memorizing the labels; it is noticing how each one solves a different kind of problem. Supervised learning works best when we already know the right answers. Unsupervised learning helps when we want the model to discover hidden structure. Semi-supervised learning bridges the gap, and reinforcement learning helps when the model must learn by making choices over time. Once you see that pattern, machine learning starts to feel less like one mysterious skill and more like a small set of learning styles we can choose from depending on the problem.
How Models Learn
When a machine learning model learns, it is not collecting facts the way we do before a test. It is more like tuning a radio until the static fades and the right station comes through clearly. The model starts with rough guesses, compares those guesses with the correct answers, and then shifts itself a little at a time. If you have ever asked, how does a machine learning model learn from data?, the answer begins with that careful cycle of guessing, checking, and adjusting.
The first thing to picture is that most models contain many internal numbers called parameters, which are values the model can change during training. A simple way to think about them is as dials on a control board. At the start, those dials are set almost randomly, so the model does not know much yet. As it sees more examples, it turns those dials toward settings that produce better predictions, and that is where learning begins to take shape.
This adjustment depends on the model’s mistake, which we already called loss. Loss is a number that tells us how far the prediction is from the correct answer, almost like a score that says, “close,” or “not close at all.” During training, the model tries to make that score smaller over and over again. In machine learning, learning is not one big leap of insight; it is a long series of tiny corrections that slowly add up.
So how does the model know which direction to move? That is where optimization comes in, which means finding a better setting for those internal numbers. A common method is called gradient descent, a phrase that sounds intimidating but behaves like following the slope downhill. If the loss is a hill, gradient descent keeps nudging the model toward the lowest point, where errors are smaller. The model does not see the whole mountain at once; it only takes the next small step that looks better than the last one.
You can imagine this process as a child learning to throw a ball into a basket. The first throw is probably far off, but the child notices whether it went left, right, short, or long. On the next attempt, the child makes a small adjustment based on that feedback. A machine learning model learns in a similar way, except the feedback comes from math instead of a coach’s voice, and the adjustments happen across thousands or millions of examples.
At this point, the model is not memorizing each example like a notebook full of answers. It is looking for a pattern that works across many examples, and that is a very important difference. A model learns best when it can generalize, which means it performs well on new data it has not seen before. That is why machine learning model training is so closely tied to data quality: if the examples are messy, biased, or too narrow, the model may learn the wrong lesson.
The data also helps shape what the model can notice in the first place. In a simple image model, the training process may gradually teach it to pay attention to edges, shapes, and combinations of pixels that matter for the task. In a language model, the same basic idea helps it notice which words tend to appear together and how sentence patterns work. The details change from one model to another, but the learning story stays the same: examples in, errors measured, parameters updated, pattern strengthened.
This is also why machine learning feels so different from traditional programming. In a normal program, a person writes the rules ahead of time. In machine learning, we give the model examples and let it discover the rules through training. That difference is the heart of why models can adapt to tasks that are too messy, too large, or too changeable for hand-written instructions alone. Once you see that, the phrase “the model learned” stops sounding mysterious and starts sounding like what it really is: a system getting better at prediction by practicing on data.
Avoiding Overfitting
After a model learns from training data, the next question is whether it learned the lesson or only memorized the page. That is where overfitting enters the story. Overfitting happens when a machine learning model fits the training examples so closely that it struggles with new data, like a student who remembers every practice question but freezes when the exam changes a little. In machine learning, that usually means the model has picked up noise, quirks, or one-off details instead of the deeper pattern we actually wanted.
The easiest way to picture overfitting is to imagine two students preparing for the same test. One studies the ideas and can answer new questions with confidence, while the other memorizes yesterday’s worksheet line by line. The second student may look brilliant during practice, but the real test reveals the gap. A model can behave the same way: it can score very well on the data it has already seen and still perform poorly on fresh examples, which is why good machine learning model training always asks, “Does this still work outside the practice set?”
This is why the validation set matters so much. A validation set is a separate slice of data used while we are tuning the model, so we can watch how it behaves on examples it has not trained on. If training accuracy keeps rising but validation performance starts slipping, that is a classic warning sign that overfitting is creeping in. The model is getting better at the homework it already knows, but not better at the wider world it will actually face.
So how do we reduce overfitting without throwing away the progress the model has made? One common answer is to make the model a little less eager to chase every tiny detail. Simpler models often generalize better because they have fewer chances to memorize noise, and that is part of why model complexity matters so much. Another useful tool is regularization, which means adding a constraint that discourages the model from relying too heavily on any single pattern. You can think of it as placing guardrails on the learning process so the model stays focused on what matters most.
We can also help by improving the data itself. More training examples often give the model a broader view of the problem, and cleaner data helps it learn the right lesson instead of a distorted one. Sometimes we also use early stopping, which means stopping training before the model starts to drift into memorization. That might feel strange at first, because we usually expect more practice to be better, but in machine learning too much practice on the same examples can make the model less useful, not more.
Another helpful habit is to keep an eye on the gap between training performance and validation performance. When both improve together, the model is likely learning the real pattern. When training keeps improving but validation stalls or falls, we should pause and rethink the setup. What causes overfitting in machine learning? Often it is a mix of too little data, a model that is too flexible, and training that goes on too long without enough checks along the way.
The good news is that overfitting is not a sign that we failed; it is a sign that the model is learning loudly enough for us to notice. That gives us a chance to adjust the lesson before we trust the result. Once we learn to watch for the warning signs and use tools like validation, regularization, and early stopping, we start building models that do more than memorize. They begin to generalize, and that is the point where machine learning becomes genuinely useful.
Evaluating Model Accuracy
When we reach model accuracy, we are standing at the moment where training turns into judgment. The model has already practiced on examples, and now we want to know whether it can make good predictions on data it has never seen before. That is why evaluating model accuracy matters so much in machine learning: it tells us whether the model is learning a real pattern or only looking convincing during practice. If you have ever asked, “How do we know if a machine learning model is good?”, this is the point where the answer begins.
The first step is to test the model on data it did not train on. We already met the training set, validation set, and test set, and those separate roles now become very important. The training set teaches, the validation set helps us tune, and the test set gives us a final check that feels closer to the real world. If we measure model accuracy on the training data alone, the result can be flattering but misleading, like grading a student using the same worksheet they already memorized.
Once we have fresh data, accuracy gives us a simple starting point. In plain language, accuracy is the percentage of predictions the model gets right. If a model makes 100 predictions and 92 are correct, its accuracy is 92 percent. That sounds clear, and in some cases it is a very helpful summary, but accuracy is only one lens, not the whole story. A machine learning model can have high model accuracy and still miss the kinds of mistakes that matter most.
That becomes easier to see when the classes are uneven. Imagine a spam filter where 99 emails are normal and only 1 email is spam. A lazy model could label every message as normal and still reach 99 percent accuracy, even though it fails at the very job we care about. This is why beginners often run into a surprising question: why can model accuracy look great while the model still performs badly? The answer is that accuracy can hide imbalances, so we need other ways to inspect the results.
One helpful tool is the confusion matrix, which is a table that shows where the model got things right and where it got things wrong. For classification, a confusion matrix helps us separate true positives, true negatives, false positives, and false negatives. Those terms sound technical at first, but they are really just labels for different kinds of correct and incorrect predictions. A false positive means the model predicted something was there when it was not, while a false negative means the model missed something that was actually present.
From there, we can ask more focused questions. Precision tells us how many of the model’s positive predictions were actually correct, while recall tells us how many of the real positives the model managed to find. Those two measures matter when mistakes do not have the same cost. For example, if we are evaluating model accuracy for spam detection, we may care about catching most spam messages, but we also do not want to mark important emails as junk by accident. In cases like that, precision and recall reveal the trade-offs much better than accuracy alone.
There is also the F1 score, which combines precision and recall into one number. It is useful when we want a single summary but do not want to ignore the balance between missed cases and false alarms. For regression models, where the goal is to predict a number instead of a category, we usually look at different measures such as mean absolute error or mean squared error instead of accuracy. That difference matters because evaluating model accuracy is not one universal formula; it changes depending on the kind of problem we are trying to solve.
The most useful habit is to compare several metrics together and ask what each one is telling us. Accuracy gives us a quick overview, but the confusion matrix and related scores help us see the details hiding underneath. When we read them side by side, we start to understand whether the model is reliable, biased toward one class, or simply too eager to look good on paper. That kind of careful reading is what turns model evaluation from a single score into a real conversation about quality.