What Is an ML Pipeline? (scikit-learn.org)
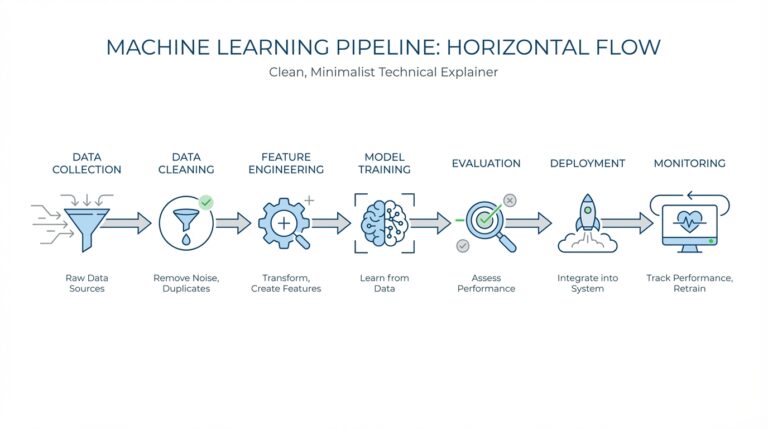
Building on this foundation, a machine learning pipeline is the path your data follows from raw input to final prediction. Think of it like a kitchen line: one station cleans and chops, another seasons, and the last one cooks. In scikit-learn, this idea appears as a Pipeline, which is a sequence of data transformers with an optional final predictor. That structure matters because it turns a scattered set of steps into one clear workflow you can repeat, inspect, and trust.
How do you keep preprocessing, model training, and prediction from turning into a tangled mess? A pipeline answers that by chaining estimators in a fixed order. In scikit-learn, every step except the last must be a transformer, meaning it has a transform method that changes the data in some way, like scaling numbers or selecting features. The last step can be a transformer, classifier, regressor, or another estimator, and when you call fit, the pipeline fits each step in turn and passes the transformed output forward. That makes the pipeline feel less like a pile of separate tools and more like one coordinated machine learning pipeline.
This is where the pipeline earns its keep. Instead of calling preprocessing code, model code, and prediction code separately every time, you fit and predict once on the whole chain. scikit-learn also lets you search across parameters from multiple steps together, which is helpful when you want to tune preprocessing and the model at the same time. Just as important, pipelines help prevent data leakage, which happens when information from your test data sneaks into training-time preprocessing and makes your results look better than they really are. In other words, the pipeline protects the story your data is telling.
Now imagine your dataset is a small neighborhood with very different houses: one column holds text, another holds categories, and a third holds numbers. A single preprocessing step rarely fits all of those at once. That is why scikit-learn pairs pipelines with ColumnTransformer, a tool that applies different transformations to different columns inside the same workflow. One column might be one-hot encoded, which turns categories into numeric indicator columns, while another column might be scaled so large values do not overpower small ones. The point is not only convenience; it is also a way to keep mixed-type data organized without losing the logic of the overall pipeline.
So when should you think in pipeline form? Use an ML pipeline whenever your steps need to happen in a repeatable sequence and you want the whole process to behave like one reusable object. That could be a simple path from cleaning to classification, or a richer setup with different transformations for different kinds of features. The real win is mental clarity: once you see the workflow as a chain, it becomes easier to test, tune, and explain. And from here, the next ideas we explore will feel familiar, because they are all variations on the same theme of guiding data through carefully ordered stages.
Core Types of Machine Learning (ibm.com)
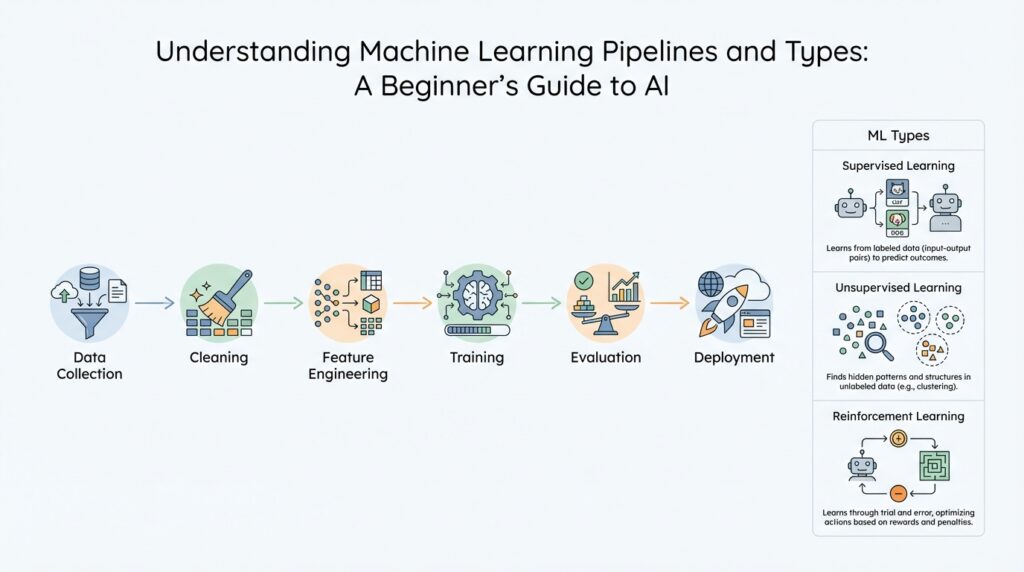
Building on this foundation, the next question is how the model learns in the first place. In machine learning, that learning path usually begins with supervised learning, unsupervised learning, semi-supervised learning, or reinforcement learning, with self-supervised learning also appearing in some modern frameworks. If you have ever wondered, “How do you know which machine learning type fits your problem?”, that is the right place to start, because the answer depends on whether your data comes with labels, patterns, or feedback. Think of it like choosing the right kind of guide for a trip: sometimes you already know the destination, sometimes you only know the landscape, and sometimes you learn by trying and adjusting.
Supervised learning is the most familiar starting point because the model studies examples with the answers already attached. The label is the correct outcome, such as “spam” or “not spam,” and the model learns to map inputs to those known outcomes. That makes supervised learning a natural fit for classification and prediction tasks, where you want the machine learning model to make a decision based on past examples. It is a bit like practicing with flashcards that already show both the question and the answer, so the pattern becomes clearer each time you review it.
Unsupervised learning feels different because the data arrives without labels, so the model has to look for structure on its own. Instead of being told what each row means, it searches for clusters, relationships, and hidden groupings, which is why people often use it for customer segmentation or recommendation-style pattern discovery. This is where the story becomes interesting: you are no longer teaching the model a fixed answer, but asking it to notice what the data seems to be doing naturally. In everyday terms, it is like walking into a room full of mixed puzzle pieces and asking the model to sort them by shape before anyone tells it what the final picture should be.
Semi-supervised learning sits between those two worlds, and that middle ground is often more practical than it first sounds. Here, you give the model a small set of labeled examples and a larger pile of unlabeled data, letting the labeled pieces act like clues for the rest. This approach matters when labeling is expensive, slow, or requires expert judgment, because it lets you stretch a small amount of guidance across a much larger dataset. Once that clicks, the idea feels like learning a new recipe with a few fully written steps and a much bigger pile of ingredients waiting to be understood.
Reinforcement learning adds a different kind of learning altogether, because the model learns from consequences rather than labels. An agent takes actions in an environment, receives rewards or penalties, and gradually discovers which choices lead to the best results. That makes reinforcement learning useful when the problem is less about static prediction and more about decision-making over time, such as robotics, games, or control systems. If supervised learning is like studying with an answer key, reinforcement learning is more like practicing a sport, where each move teaches you something about what works and what does not.
Taken together, these machine learning types give us a practical way to think about the pipeline we discussed earlier. Before we move on, it helps to remember that the learning type shapes everything downstream: what data you need, how you prepare it, and how you judge success. That is why a model is never only a model; it is the product of the learning style behind it, and that choice quietly guides the rest of the machine learning workflow.
Data Cleaning and Feature Preparation (scikit-learn.org)
Building on this foundation, the first real work in a machine learning pipeline is often data cleaning and feature preparation. This is the moment when raw data stops looking like a messy drawer full of receipts and starts becoming something a model can actually use. You may have missing values, text labels, mixed data types, or numbers on wildly different scales, and all of that can quietly distort the learning process if we leave it alone. How do you prepare data so the model sees the right patterns instead of the noise? We start by making the inputs consistent, readable, and fair for the algorithm.
Data cleaning usually begins with the missing pieces. In scikit-learn, that often means imputation, which is the process of filling in missing values with a sensible replacement, such as the average for numbers or the most common category for text-like fields. Think of it like patching holes in a road before cars drive over it; if we ignore the gaps, the model may stumble or make guesses based on incomplete information. This step matters because many estimators cannot handle missing values directly, and even when they can, the pattern of missingness may still mislead the training process.
Once the data is complete enough to work with, we usually turn to feature preparation, which means shaping each column so it speaks the model’s language. A feature is simply one input variable, like age, income, or product category, and each one may need a different kind of transformation. Numbers often benefit from scaling, which resizes values so one feature does not overpower the others just because it uses a bigger range. That is especially helpful when you are using distance-based methods or gradient-based training, because a feature measured in thousands can drown out one measured in fractions.
Categorical data needs a different kind of care. If a column contains labels such as city names, membership tiers, or color names, we usually convert it with one-hot encoding, which turns each category into its own yes-or-no column. This keeps the data numeric without pretending that one category is larger or smaller than another in a way that would confuse the model. In practice, feature preparation is a lot like translating a conversation into a format the listener understands, while keeping the original meaning intact.
This is where scikit-learn becomes especially helpful, because it lets us combine these steps in a clean and repeatable way. A ColumnTransformer can apply one set of transformations to numeric columns and another to categorical columns, all inside the same machine learning pipeline. That means we do not have to manually preprocess each column by hand every time we train or test a model. More importantly, the same transformations are applied consistently during fitting and prediction, which helps prevent data leakage and keeps our results honest.
As we discussed earlier, the learning type also shapes how we prepare data, and that connection becomes clearer here. Supervised learning often needs well-labeled, carefully transformed features so the model can map inputs to known outputs. Unsupervised learning still benefits from cleaning and scaling, but now the goal is to reveal structure rather than predict a label. In both cases, data cleaning and feature preparation act like the workshop before the performance: they may not be glamorous, but they decide whether the model steps on stage ready or unprepared.
Training, Validation, and Test Splits (scikit-learn.org)
Building on this foundation, training, validation, and test splits are the moment where we stop treating the whole dataset like one big pile and start giving each part a different job. The training split is the study room, the validation split is the rehearsal room, and the test split is the final exam that we save for the end. In scikit-learn’s own workflow, this separation is what helps you measure whether a model can handle unseen data instead of merely repeating what it has already seen. The library’s face-recognition example even shows a simple holdout split before model fitting, keeping part of the data aside for later evaluation.
Here is the heart of it: the training set teaches the model, while the validation set helps us choose between competing settings, which are called hyperparameters, meaning the knobs we set before training, such as regularization strength. If we use the same data to both train the model and decide whether it is good, we invite overfitting, which means the model starts to memorize patterns that do not generalize. scikit-learn’s documentation explicitly warns that testing on the same data used for learning is a methodological mistake, and it explains that a validation set exists so we can tune first and reserve the test set for the final check.
Now that we understand the roles, the next question is: do we always need a separate validation split? Not necessarily. scikit-learn points out that carving the data into three fixed pieces can reduce the amount available for learning and make results depend heavily on one random split, which is why cross-validation is often preferred. In k-fold cross-validation, the training data is divided into k folds, the model trains on k – 1 folds, and the remaining fold acts as the validation fold; then this rotates until every fold has had a turn. That means you can tune your model with far more stability, while still keeping a true test set untouched for the end.
In practice, the way you split matters as much as the fact that you split at all. The train_test_split helper lets you choose the size of the holdout and supports stratified splitting, which preserves class proportions so a rare category does not disappear by accident from one side of the split. That is especially helpful in classification problems, where a class imbalance can make a split look better or worse than it really is. But if your data has structure, plain random splitting may be the wrong move: scikit-learn notes that train_test_split is a wrapper around ShuffleSplit and cannot account for groups, while time-ordered data should use a time-series-aware splitter such as TimeSeriesSplit, which trains on earlier data and tests on later data rather than mixing the timeline.
So when should you reach for each split? Use the training split for fitting, use the validation split for model selection and parameter tuning, and guard the test split like a sealed envelope until you are ready for the final score. If your dataset is small, cross-validation can stand in for a single validation split and give you a steadier view of performance; if your data is grouped or time-based, reach for a split strategy that respects that structure instead of forcing everything into a random shuffle. Once that idea clicks, the rest of the workflow becomes easier to trust, because you are no longer asking one dataset to play three different roles at once.
Model Evaluation and Hyperparameter Tuning (scikit-learn.org)
Building on this foundation, model evaluation is the point where a machine learning pipeline stops being a promising recipe and starts showing evidence. How do you know whether a model is genuinely learning or just getting lucky on one split? In scikit-learn, we usually answer that with cross-validation, which runs the model through several train-and-check cycles, and a scoring rule, which tells the library what performance means for your task. That pairing matters because it lets us compare models on the same yardstick instead of trusting a single snapshot.
At this stage, the word metric simply means the number we use to judge success, such as accuracy for classification or mean squared error for regression. Scikit-learn lets cross-validation tools and search tools accept a scoring parameter, and the library follows a helpful convention: scorers are written so that higher numbers are better, even when the underlying metric is a loss that normally goes down. That is why some losses appear with a negated name, like neg_mean_squared_error; it feels odd at first, but it keeps the evaluation machinery consistent. When your problem has class imbalance or different business costs, you can choose another scorer that better matches the real goal.
Now that we can measure performance, hyperparameter tuning becomes a search for the best settings around the model. A hyperparameter is a knob you set before training, like the regularization strength in logistic regression or the number of trees in a forest, and GridSearchCV tries every combination in a parameter grid while evaluating each one with cross-validation. This is where the pipeline from earlier really earns its place, because scikit-learn lets you address step parameters with the stepname__parameter pattern, so you can tune preprocessing and the final estimator in one sweep. Instead of hand-testing a dozen isolated changes, you let the search object do the bookkeeping while the pipeline keeps every transformation inside the evaluation loop.
When you tune inside cross-validation, it is tempting to treat the best score as the final answer, but that number still belongs to the search process. The safer habit is to use the search to pick a candidate, then keep one untouched test set for the last check, which is exactly why we separated evaluation roles earlier. In scikit-learn, GridSearchCV stores the best parameter combination after the search, but the important lesson is that the tuning loop and the final judgment are different jobs. That separation is what keeps hyperparameter tuning from turning into wishful thinking.
Sometimes one score is not enough. A model can look strong on accuracy and still miss the cases you care about, so scikit-learn also supports evaluating multiple metrics at once in tools like GridSearchCV and cross_validate. That makes model evaluation feel more like checking a map from several angles: one view tells you overall performance, another tells you where the model fails, and together they show whether a tuning choice is actually worth keeping. If you are comparing pipeline variants, this is a practical way to balance speed, precision, recall, or any other measure that matches the problem in front of you.
Taken together, evaluation and tuning turn a pipeline from a working draft into something you can defend. First we define how success should be measured, then we test that definition across folds, and only then do we let the hyperparameters change the shape of the model. That order keeps the process honest and helps the same pipeline scale from a small experiment to a repeatable workflow. With that in place, we are ready to talk about how the model behaves once it leaves the lab and meets new data.
Pipeline Automation and Reusable Steps (scikit-learn.org)
Building on this foundation, the real magic of a machine learning pipeline appears when the same careful steps stop living in scattered notebooks and start behaving like reusable building blocks. You no longer have to remember which script scaled the data, which one encoded categories, and which one fit the model in the right order. Instead, the pipeline stores that sequence for you, so the whole process feels like one dependable routine rather than a stack of fragile instructions. How do you keep that routine from falling apart when you test new ideas? You package the steps once, then reuse them everywhere you need the same logic.
That is where reusable steps become so valuable. Each step in a scikit-learn pipeline has a clear job, and because those jobs follow a shared interface, you can swap one step for another without redesigning the whole workflow. Think of it like swapping a single ingredient in a recipe while keeping the rest of the meal intact. A scaler, an encoder, or a classifier can all live inside the same machine learning pipeline, which means your experimentation becomes cleaner and much easier to compare.
This structure also makes automation feel natural. Once the pipeline is assembled, fit trains every step in order, and the later steps automatically receive the output of the earlier ones. That matters because you do not need to manually repeat preprocessing each time you run a new experiment. The same pipeline can be fitted on training data, used to transform new data, and then applied again during evaluation, which keeps the workflow consistent from start to finish. In other words, the pipeline becomes the automatic path your data follows every time.
One of the most helpful details in scikit-learn is that pipeline steps are named, and those names give you control without clutter. When a step has a name, you can reach into the pipeline and adjust its settings using the stepname__parameter pattern, which means you can tune a preprocessing step and a model together. That is a small detail with a big payoff, because it lets you reuse the same pipeline structure while exploring different combinations of settings. So when you ask, “How do I reuse the same preprocessing but test a different model?”, this naming system is the answer.
The same idea also helps when you want to automate model selection. A pipeline can hold the full sequence of transformations, and search tools can explore different values for the steps inside it without breaking the chain. That means your reusable steps do more than save typing; they become part of a repeatable experiment. Instead of building separate scripts for each variation, you keep one machine learning pipeline and let the parameters change around it. The result is less duplication, fewer mistakes, and a much easier path to comparing results honestly.
Reusable steps also protect you from a subtle problem: accidental inconsistency. If you preprocess training data one way and prediction data another way, the model can start behaving like it learned two different languages. A pipeline removes that risk because the same fitted steps are applied in the same order every time. This is especially useful when your workflow includes multiple transformations, since each one depends on the previous one having been done correctly. The pipeline does the remembering for you, which is exactly what automation should do.
Once you start thinking this way, a pipeline feels less like a code convenience and more like a pattern for disciplined reuse. You build the steps once, give them names, and let scikit-learn carry them through training, testing, and prediction without drifting out of sync. That same structure makes your experiments easier to repeat, easier to tune, and easier to trust. And with that foundation in place, we can move forward knowing the workflow is already organized enough to support the next layer of model-building decisions.