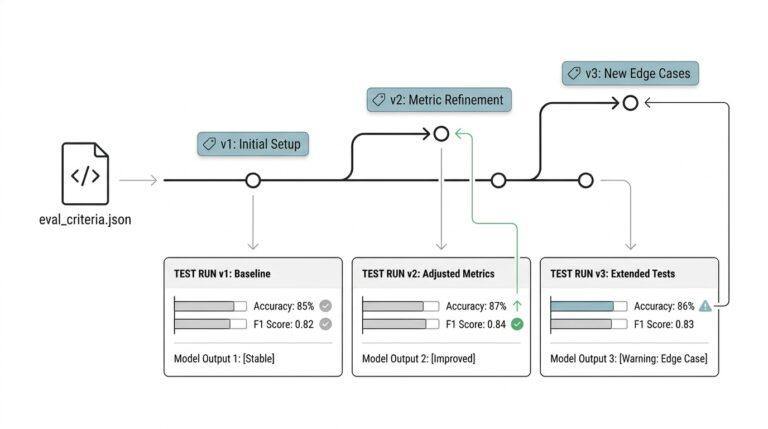
Audit dataset for quality issues
Poor training data and unnoticed data quality issues are the most common silent killers of model performance. When your model underperforms in production despite strong offline metrics, the root cause is often noisy labels, hidden duplicates, or distribution shifts in the training data. How do you detect those problems before they damage your deployment pipeline? Start with a repeatable, instrumented inspection process that flags schema drift, label inconsistency, missingness patterns, and distributional surprises early in the lifecycle.
Building on this foundation, design a checklist-driven data validation pipeline that runs automatically on every ingested batch. The first checks should be deterministic: verify schema (types, ranges, cardinalities), count nulls with df.isnull().sum(), and confirm unique key constraints to catch duplication or aggregation errors. Follow with statistical sanity checks: compute feature-wise means, variances, and percentiles and compare them to a reference snapshot using simple thresholds or normalized differences. This layered approach separates syntactic problems (broken CSV parsing, encoding mismatches) from semantic problems (label drift, cohort imbalance), so you can triage fixes quickly.
Label quality deserves its own focused audit because noisy labels bias loss functions and mask true model capacity. Begin by sampling borderline predictions where your current model has low confidence and perform targeted human review; measure inter-annotator agreement (Cohen’s kappa or Krippendorff’s alpha) on a representative subset to quantify label noise. Use confusion matrices and class-wise precision/recall to find systematic mislabels—if a specific class shows low precision across annotators, that signals ambiguous labeling instructions rather than model failure. When disagreement exceeds a pre-defined threshold, rework the label schema or add adjudication rules rather than re-training blindly.
Detecting leakage and temporal problems prevents over-optimistic evaluation. Run feature-target correlation scans and permutation importance tests: if a feature’s importance collapses after shuffling the target, it likely contained leakage. For time-series or session-based data, enforce strict chronological splits and simulate production windows to reveal temporal leakage where future-derived features accidentally appear in training. For example, patient readmission prediction often leaks when discharge summaries written after readmission slip into the training set; catching that requires explicit timestamp gating during data extraction.
Distributional issues and outliers are often subtle but consequential. Complement automatic metrics with visual inspections: overlay reference and current histograms, use quantile-quantile plots, and compute KS or population-stability indices for critical features. Don’t rely solely on global statistics—stratify by label, user cohort, and geographic region to expose masked drift. For outliers, apply robust statistics (median absolute deviation) and flag cases where extreme values are legitimate business signals versus ingestion errors; handle the former with model-aware capping and the latter by correcting the pipeline upstream.
Finally, operationalize the audit into your MLOps workflow so data quality gates become part of CI. Persist validation artifacts (summary statistics, failing record samples, label disagreement reports) alongside model artifacts and enforce automated gating rules that block deployments when critical thresholds fail. Instrument feedback loops: log post-deployment prediction distributions and trigger re-audits when drift accumulates. By treating training data validation as code—testable, versioned, and reviewable—you reduce surprise failures and keep model performance aligned with real-world behavior.
Next we’ll apply these audit outputs to prioritize remediation steps: whether to relabel, augment, remove, or enrich problematic partitions so you can turn detected data defects into measurable model improvements.
Set proper train-validation-test splits
Building on this foundation, a careless split can erase the value of rigorous data auditing: your model will look great offline and fail spectacularly in production if training, validation, and test partitions misrepresent how data appears in the wild. The purpose of a proper split is simple but critical — estimate generalization reliably, tune without leaking future information, and measure real-world performance on an untouched holdout. If your validation set is contaminated or your test set mirrors training too closely, your remediation work (relabeling, enrichment, augmentation) will chase noise instead of signal.
Start with clear objectives for each partition. The training set is for learning model parameters; the validation set is for model selection, early stopping, and hyperparameter tuning; the test set is an unbiased estimator of production performance that must remain untouched until final evaluation. Define these roles explicitly in your pipeline and enforce them: we lock the test set behind a policy and treat the validation set as ephemeral but reproducible. This separation prevents overfitting to validation and ensures that when we act on audit findings—relabeling or removing partitions—we know which numbers to trust.
For IID classification problems, use stratified splits to preserve label distribution and common cohort proportions. A conventional starting point is 70/15/15 or 80/10/10, but ratios should reflect dataset size and class balance: when classes are rare, allocate more examples to validation and test to get reliable metrics. Use cross-validation or repeated stratified k-fold when the dataset is modest; that gives robust performance estimates and reduces variance in hyperparameter searches. In scikit-learn terms, prefer StratifiedKFold for classification and provide the same random seed across experiments to keep splits reproducible.
When data contains natural groups—users, sessions, hospitals—standard random splits create leakage between partitions. Group-aware strategies (GroupKFold, leave-one-group-out) ensure all records from a single entity live in only one partition. For example, if a user’s historical behavior appears in both train and validation, your model will exploit user-specific signals that won’t exist for new users. We test for this by counting unique group IDs per partition and failing the pipeline if the same group appears twice.
Temporal and production-like constraints demand chronological splits rather than random sampling. For time-series or streaming sources, hold out an out-of-time test window that mirrors production latency and seasonality, and use rolling-window or expanding-window validation for model selection. How do you decide the right validation window? Match the window to the frequency of model retraining and the expected production drift interval: if you retrain monthly, use month-long validation windows spaced to cover seasonal cycles. This prevents overly optimistic validation metrics caused by peeking at future data.
Beyond the mechanics, validate your split quality with metrics and sanity checks. Compare feature and label distributions between training and validation via KS tests, population stability index, or simple mean/variance checks; compute duplicate key intersections and a small lookup to detect cross-partition leakage. Track these split-quality artifacts alongside other data validation outputs so gating logic can automatically block a run when PSI or duplicate rates exceed thresholds. These checks close the loop with the dataset audits we described earlier.
Design test sets strategically: maintain a primary “hard” test that never changes, and an auxiliary “soft” test for iterative experiments when you need faster feedback. For high-stakes models, include an out-of-time test and a geographically or cohort-held-out test to expose distributional brittleness. Finally, automate split creation as versioned code: store split indices, seed values, and group/timestamp criteria in your artifact store so experiments are traceable and reproducible.
Taking this concept further, we use split-aware remediation: prioritize relabeling and augmentation in partitions where validation shows consistent errors, and run post-remediation audits using the same locked test set so improvements are measurable. By treating train-validation-test splits as an explicit, versioned part of your data contract, you reduce surprise failures and make remediation efforts accountable and effective.
Detect and prevent data leakage
When your offline metrics look unrealistically high, the likely culprit is data leakage—signals that make the model cheat by seeing information it won’t have in production. Building on this foundation of dataset audits and split hygiene, we treat leakage as a distinct failure mode that systematically inflates validation numbers and then erodes production trust. You should front-load leakage checks into ingestion and split creation so problems are caught before expensive experiments run. Detecting and preventing these leaks preserves the value of the other validation steps we’ve already put in place.
Start by naming the kinds of leakage you care about: feature leakage, temporal leakage, and label leakage. Feature leakage occurs when an input feature contains information derived from the target (for example, a post-event flag computed after outcome occurrence). Temporal leakage is when future information sneaks into training due to poor timestamp gating or windowing. Label leakage (labels appearing in inputs via joins or logging artifacts) often hides inside rich telemetry and requires provenance checks to find. Making these definitions explicit lets you craft targeted tests rather than relying on vague intuition.
How do you catch leakage early in a reproducible way? Run targeted experiments that verify whether a feature’s predictive power survives realistic production constraints. Start with a feature-target correlation matrix and follow up with permutation importance: if permuting a feature collapses performance dramatically, that’s a red flag. Use a target-shuffle baseline—train the same pipeline on randomly permuted labels and expect near-chance performance; any sizable gap suggests leakage or label signal contamination. Instrument these tests to run in CI so they block when a newly added feature shows suspicious behavior.
A short, pragmatic check you can add to pipelines is a train-versus-shuffled-target comparison. For example, in scikit-learn style pseudocode:
# fit on real labels
clf.fit(X_train, y_train)
real_score = clf.score(X_val, y_val)
# fit on shuffled labels
y_shuf = np.random.permutation(y_train)
clf.fit(X_train, y_shuf)
shuf_score = clf.score(X_val, y_val)
if real_score - shuf_score > threshold:
warn('possible leakage or strong label signal')
This pattern isolates whether seemingly-good features learn spurious relationships tied to labels or to future events. Combine it with per-feature permutation tests and per-cohort analyses (by user, device, or geography) so you don’t miss cohort-specific leakage.
Prevention is primarily about data governance and feature provenance. Enforce strict timestamp gating when extracting features from event streams: compute features only from events strictly older than the prediction cutoff and persist generation-time metadata with each feature (source table, transform code, and generation timestamp). Use group-aware splits and store split indices as versioned artifacts so entity-level leakage cannot reappear during retraining. Treat feature engineering code as part of your deployment package and run the same validation suite locally, in staging, and in CI to keep feature leakage from being introduced ad hoc.
In practice, a common remediation loop is detection, quarantine, and redesign. When you find leakage in a cohort—say session-level identifiers leaking into churn models—quarantine the offending partition, add a blocking test to your CI, and redesign the feature to remove post-outcome computation or to aggregate at a safe horizon. We prioritize fixes that are easiest to automate (timestamp gating, join filters) and escalate ambiguous cases for human review and label-provenance audits. These actions turn detection artifacts into durable pipeline improvements.
Taking this approach keeps your validation metrics honest and actionable, and it bridges the audit work we discussed earlier with split-aware remediation strategies. As we move to prioritizing fixes—whether relabel, remove, or redesign features—we’ll rely on these leakage signals and the versioned artifacts they generate to measure real improvement in the locked test set.
Improve label quality and consistency
Building on this foundation, improving label quality and label consistency is the single highest-leverage activity after you’ve instrumented dataset audits and split hygiene. Poor labels inject bias into loss functions, amplify noisy labels, and hide true model capacity even when features and splits are correct. How do you decide which label issues to fix first and which to accept as unavoidable noise? We start by turning labeling from an ad-hoc task into a measurable engineering workflow: a clear schema, rigorous examples, reproducible adjudication, and telemetry that ties label changes to model impact.
Start by designing an explicit label schema that removes ambiguity before annotators ever open an interface. Define positive and negative classes with boundary rules, include five canonical examples and five counterexamples for each label, and codify decision trees for frequent edge cases. For instance, in fraud detection specify whether disputed transactions count as fraud when chargebacks are pending versus finalized; in medical imaging define whether poor-quality scans are labeled as “unreadable” or mapped to the nearest diagnostic class. These rules make label consistency testable and reduce downstream relabeling overhead.
Train annotators as you would onboard SREs or backend engineers: run workshops, use gold-standard calibration tasks, and measure inter-annotator agreement continuously. Double-annotating a rolling 5–10% sample and computing Cohen’s kappa or Krippendorff’s alpha gives an operational signal of label noise; set pragmatic thresholds (for example, kappa < 0.6 triggers guideline revision). When disagreements cluster on specific examples, use blind adjudication by a small expert panel and record the adjudicated rationale as metadata so future annotators learn the intent rather than the corrected label alone.
Prioritize relabeling with a targeted, model-driven strategy rather than blanket re-annotation. Combine model uncertainty sampling (low-confidence predictions), disagreement sampling (annotator conflicts), and business-impact weighting (high-value cohorts or rare classes) into a single score and relabel the top X% by cost-benefit. For example, compute score = alpha * uncertainty + beta * annotator_disagreement + gamma * cohort_weight and surface those examples to annotators; this focuses effort where improving label quality yields the largest lift in real-world metrics.
Represent label uncertainty in training instead of hiding it. Where annotators disagree, persist probabilistic labels or consensus distributions rather than forcing a hard class. Use label smoothing or soft targets to reduce overfitting to noisy labels, and consider robust loss functions (for example, focal loss for class imbalance or symmetric cross-entropy for label noise). For stubborn noisy labels, co-teaching or sample reweighting based on small-loss heuristics can help models ignore corrupted examples during early epochs, while you run parallel relabeling to fix the root cause.
Treat labeling as versioned artifacts with lineage and automated monitoring so label drift becomes detectable and actionable. Store label provenance (annotator IDs, guideline version, adjudication notes, and timestamp) alongside training indices and compute per-class agreement and confusion heatmaps each time you retrain. When agreement drops or a cohort’s precision/recall shifts, trigger a targeted relabeling job rather than a full dataset sweep. By integrating these practices with the remediation loop we discussed earlier, we convert noisy labels into a managed engineering problem and make improvements measurable on your locked test set.
Handle class imbalance and sampling
Class imbalance and sampling decisions are among the fastest ways to silently bias training and skew real-world performance, so we should treat them as first-class data engineering problems. How do you decide when to oversample rare labels, when to reweight losses, or when to collect more data for underrepresented cohorts? In practice the right choice depends on label rarity, signal quality, and downstream cost asymmetry, and you should front-load these dimensions in your audit and split decisions so sampling changes are measurable against the locked test set.
Building on the dataset audit and split hygiene we discussed earlier, the central problem is that loss functions and batch composition implicitly optimize for the majority class unless you intervene. When class imbalance is severe, your model will minimize overall error by predicting the dominant label, producing deceptively high accuracy while precision and recall on minority classes collapse. Therefore we must combine data-level strategies (sampling) with algorithm-level strategies (loss weighting, robust losses) and evaluation-level changes (AUC-PR, per-class F1) so improvements reflect real production gains rather than metric artifacts. Treat sampling as an experiment axis you version and track like any hyperparameter.
Start with safe, deterministic sampling controls: use stratified splits for validation and test so class proportions remain stable for fair comparisons, and avoid any temporary oversampling in the held-out test set. For training, consider three common sampling patterns: random oversampling of minority classes, random undersampling of majority classes, and informed synthetic sampling like SMOTE that interpolates minority examples. Here is a compact scikit-learn example showing stratified splitting and a pipeline-friendly oversampler:
from sklearn.model_selection import StratifiedKFold
from imblearn.over_sampling import RandomOverSampler
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
ros = RandomOverSampler(random_state=42)
X_res, y_res = ros.fit_resample(X_train, y_train)
Random oversampling is low-cost and preserves feature distributions, but it can overfit if rare examples are duplicates. SMOTE and its variants help when minority class feature space is dense enough to interpolate safely, but they can create unrealistic synthetic cases around label boundaries. Undersampling reduces training cost but risks discarding useful majority-class signal; hybrid approaches—undersample then oversample to a target ratio—often strike a practical balance.
When sampling alone won’t solve the problem, use algorithmic approaches that respect class imbalance without changing data distribution. Set class weights in your loss function so the optimizer emphasizes rare classes, or switch to losses designed for imbalance like focal loss which down-weights easy negatives and focuses gradient on hard, minority-class examples. For scikit-learn classifiers you can pass class_weight=’balanced’ or compute explicit weights via inverse prevalence; for deep learning, implement focal loss or per-example weighting at the batch level. Also tune decision thresholds post-training using validation cohorts: optimizing for F1 or business-specific cost yields better operating points than default 0.5 thresholds.
Evaluation matters as much as intervention: accuracy lies in the presence of imbalance, so choose metrics that surface minority-class performance. Prefer precision-recall curves and AUC-PR for rare positive classes, report class-wise precision/recall and confusion matrices by cohort, and compute calibration curves to ensure predicted probabilities map to real-world event rates. Importantly, keep validation and test sets representative of production prevalence—do not evaluate on an artificially balanced test set unless you explicitly report results under both balanced and production distributions.
Operationalize your approach by making sampling choices auditable, reversible, and monitored. Log sampling ratios, seed values, and any synthetic-sample provenance alongside training artifacts so you can reproduce experiments and trace regressions. Use cohort-based monitoring in production to detect when the minority class drifts or becomes more prevalent, triggering data-collection campaigns or recalibration. Taking this concept further, prioritize interventions based on cost-benefit: when relabeling or targeted data collection yields higher expected utility than aggressive oversampling, invest there and treat sampling as a temporary bridge rather than a permanent fix.
Monitor concept drift and retrain
Concept drift is the slow rot that turns a production model from an asset into a liability, and watching for it is a continuous engineering responsibility — not a quarterly checkbox. You need automated drift detection and a clear retrain policy that links statistical signals to business impact, because noisy alerts alone will either waste your team’s time or let degradation go unnoticed. Building on our earlier dataset audits and split hygiene, we front-load monitoring of both input distributions and prediction behavior so you can detect shifts before users notice. This early focus on concept drift and when to retrain saves downstream relabeling and rollback costs and keeps model risk manageable.
Start with what to measure: combine feature-level distribution tests with model-centric metrics. At the feature level compute population stability index (PSI), Kolmogorov–Smirnov (KS) statistics, and KL divergence on numeric and categorical features, and track embedding or histogram cosine similarity for high-dimensional inputs. At the model level, monitor AUC, precision/recall by cohort, calibration error, and the rate of low-confidence predictions; rising calibration error or a steady drop in AUC together with PSI signals is often a reliable indicator of concept drift. For practical signal quality, surface the five most-drifted features alongside sample records so engineers can triage whether drift stems from upstream ingestion, schema changes, or genuine production shifts.
Design monitoring as a multi-timescale pipeline that supports batch checks and near-real-time alerts. Run fast, rolling-window tests (hourly or a few times per day) for high-throughput systems and more sensitive, weekly statistical tests for slower domains; use multiple window sizes to catch both abrupt and gradual drift. Apply multiple-hypothesis correction when you monitor hundreds of features to reduce false positives, and maintain cohort-based monitors (by user segment, geography, device) because global statistics often mask localized failure modes. Persist metrics and raw samples in an artifact store so every alert is reproducible: we should be able to re-run the same PSI calculation against archived input snapshots when investigating an incident.
How do you decide when to retrain? Tie retrain triggers to a blend of statistical thresholds and business-impact tests rather than an arbitrary schedule. For example, require (a) a sustained AUC drop of X points for Y consecutive evaluation windows, (b) PSI > 0.2 on one or more critical features, or (c) an increase in false negatives above a business-cost threshold; only when at least two conditions hold do we initiate a retrain pipeline. Also check sample size and label freshness: if you don’t have enough recent labeled data to produce a reliable validation curve, prefer targeted data collection or soft-labeling strategies over blind retraining. This decision logic prevents expensive model churn and focuses effort where it moves the business needle.
When you do retrain, choose a strategy that matches the drift type: full retrain for broad distributional shifts, incremental or warm-start training for gradual concept changes, and calibration-only adjustments when probabilities drift but ranking remains stable. Implement a reproducible pipeline that locks the test set and uses an out-of-time validation window to avoid leakage; run backtests that simulate production latency and seasonality, and validate on the same cohorts that showed drift. Use shadow deployments and canary rollouts: score live traffic with both old and new models, compare business metrics in a no-impact shadow channel, and promote only when the retrained model demonstrably improves both statistical and business KPIs.
Finally, operationalize the loop: automate gating in CI/CD so retrains require passing feature-provenance, leakage, and fairness checks before rollout, and instrument post-deploy monitors that compare pre- and post-deploy distributions. Keep rollback playbooks and data-versioned artifacts so you can revert and explain changes, and schedule periodic retrospective reviews to refine thresholds and sampling rules based on actual incidents. Taking this approach converts drift detection and retraining from an ad hoc scramble into a reproducible part of your MLOps lifecycle, allowing us to maintain model performance as the world — and your data — evolves.