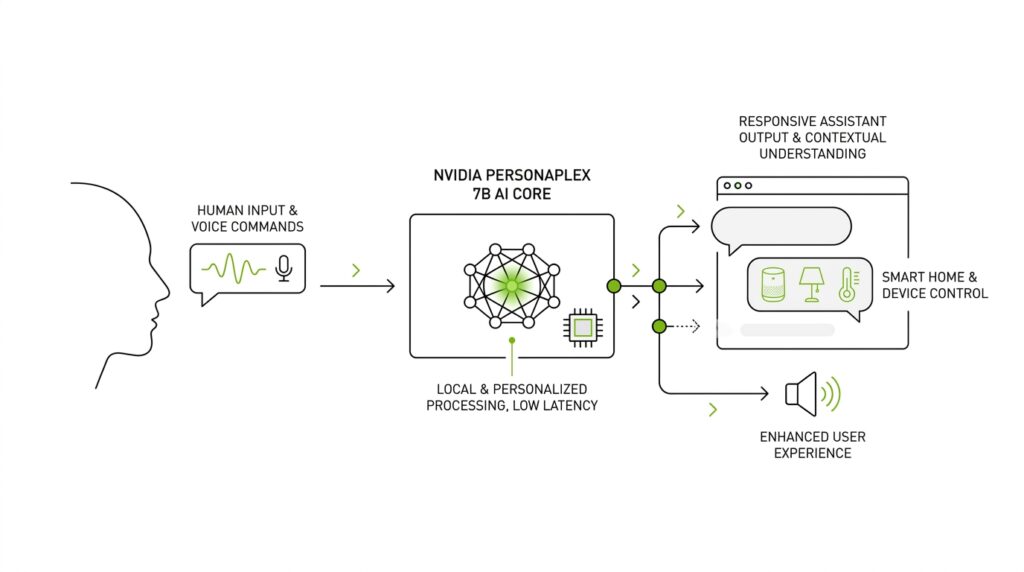
What PersonaPlex 7B Does
When you first meet PersonaPlex 7B, the most important thing to understand is that it is not trying to be a text chatbot that talks after thinking in silence. It is a full-duplex speech-to-speech model, which means it can listen and speak at the same time, the way two people do in a lively conversation. So what does PersonaPlex 7B actually do when you talk to it? It turns live speech into a natural back-and-forth exchange, with the goal of making a voice assistant feel less like a machine reading from a script and more like a responsive conversational partner.
That shift matters because older voice systems often work like a relay race: first they convert your speech into text, then a language model decides what to say, then a speech engine speaks the reply. PersonaPlex 7B takes a different path. It is designed to handle the speaking and listening together, which lets it react while you are still talking, pause at the right moments, and produce backchannels like “uh-huh” or “yeah” that signal attention without breaking the flow. In plain language, it is built for the messy rhythm of real conversation, not the neat stop-and-start rhythm of a form fill.
The second thing PersonaPlex 7B does is give you control over the persona, which means the character or role the model should play. NVIDIA describes this as role conditioning, a way of steering the model with text prompts so it can act like a helpful assistant, a customer service agent, or another defined role. It also supports voice cloning, which means it can use a speech sample to imitate a target voice instead of sounding like a single fixed speaker. That combination is the heart of PersonaPlex 7B: you are not choosing between a natural conversation and a specific voice or role, because the model is meant to support both at once.
To make that possible, PersonaPlex 7B uses what the paper calls a hybrid system prompt, which is a guided setup that mixes a text description of the role with an audio example of the voice. You can think of it like handing the model both a costume and a script before the scene begins. The model card says the inputs include user speech plus prompt text, and the outputs include both agent text and agent speech, all centered on a 24 kHz audio format. That tells us the system is meant to work as a speech-first voice assistant, not a text tool that happens to talk.
Under the hood, PersonaPlex 7B was trained on synthetic conversations built from prompts and user-agent dialogue, and NVIDIA evaluated it on benchmarks that test turn-taking, responsiveness, interruption handling, and naturalness. The paper reports strong results in role adherence, speaker similarity, latency, and dialog naturalness, which is the research way of saying it stays in character while still feeling quick and human. That is why PersonaPlex 7B matters for voice AI: it is not only trying to answer correctly, but to answer in the right voice, at the right time, with the right conversational timing.
So in practical terms, PersonaPlex 7B does three jobs at once. It listens like a live conversational partner, speaks like a voice you can shape, and behaves like a role you can define. That mix is what makes it different from a basic voice assistant, because the model is trying to preserve both personality and real-time flow in the same exchange. And that sets us up for the next question naturally: how does a system like this actually manage to sound so responsive without losing the identity you gave it?
Duplex Speech Architecture
If you have ever wondered how a voice assistant can sound like it is thinking and listening at the same time, this is where the machinery starts to matter. PersonaPlex 7B follows the Moshi architecture and takes in three streams at once: your audio, the agent’s text, and the agent’s audio. That setup is the backbone of its speech-first design, and the model works at a 24 kHz sample rate, which gives it a detailed stream of sound to shape into continuous conversation rather than stop-and-start clips.
What makes that architecture feel different is that it does not treat speech like a relay race with separate runners. Instead, listening and speaking happen together, so the model can keep pace with your words instead of waiting for one stage to finish before the next begins. NVIDIA describes this as a duplex model, and the paper explains that this is what lets PersonaPlex handle turn-taking, interruptions, and backchannel cues like brief acknowledgments without breaking the conversational flow. In practice, that means the system behaves more like a person in a real dialogue and less like a machine waiting for its turn.
The real organizing idea is the Hybrid System Prompt, which is the model’s way of receiving both a role and a voice before the conversation begins. The text prompt segment tells PersonaPlex what character to play, while the voice prompt segment gives it a short audio sample to follow, and the two are placed one after the other in time. Think of it like giving an actor a script and a voice coach in the same rehearsal, so the performance starts with both identity and delivery already aligned. That is how PersonaPlex supports role conditioning and zero-shot voice cloning at the same time.
A small technical detail makes that setup more stable than it first sounds. During the prompt phase, the user audio channel is replaced with a 440 Hz sine wave, which is just a steady tone used as a placeholder so the model does not confuse the setup with real user speech. NVIDIA also uses custom delimiters to mark the boundary between the prompt and the live dialogue, which acts like a curtain between rehearsal and performance. In other words, the architecture gives the model a clean signal for where guidance ends and conversation begins.
This design also helps explain why PersonaPlex can feel quick. Because the voice prompt can come first, the system can prefill part of its internal state during inference, which is the stage where the trained model generates a reply. That can reduce latency, meaning the delay between your speech and its response, especially when zero-shot voice cloning is not needed. The result is a voice assistant architecture that is not only trying to sound human, but trying to start speaking at the right moment with as little friction as possible.
Under the hood, the architecture is only useful if it learns the right habits, so NVIDIA trained it on synthetic two-speaker conversations and evaluated it on benchmarks that probe turn-taking, responsiveness, interruption handling, and backchannels. The paper reports strong results in role adherence, voice similarity, and dialog naturalness, and it argues that PersonaPlex extends duplex speech beyond generic assistants into more structured real-world settings. So when we talk about the architecture, we are really talking about a system that tries to preserve timing, identity, and conversation structure all at once.
Set Voice and Role
Once the conversation can flow in real time, the next question is identity. PersonaPlex 7B handles that by separating what it should sound like from what it should do, using role conditioning, which is the model being guided by a text description of the role, and voice cloning, which is the model using a short audio sample to imitate a target voice. NVIDIA frames this as a way to break the old trade-off between natural dialogue and customization, so a voice assistant can feel alive without being locked into one fixed character.
The model packages those controls into a Hybrid System Prompt, which combines a text prompt segment and a voice prompt segment. Think of it like giving an actor both a script and a voice reference before the scene begins: the text side tells PersonaPlex whether it should act like a teacher, a bank agent, or a receptionist, while the audio side teaches the timbre, pace, and vocal style. The paper says PersonaPlex receives user audio, agent text, and agent audio as three streams, and the two prompt pieces are arranged together so the model can align role and voice before live dialogue starts.
What does that mean when you are building a voice assistant? It means you can ask the same system to behave like a wise helper in one setting and a customer service agent in another, without retraining the whole model from scratch. NVIDIA’s examples show prompts for a friendly teacher, banking support, and medical reception, which makes the idea feel less abstract and more practical: one engine, many personas. In that sense, PersonaPlex 7B feels less like a single app and more like a performer who can change costumes between scenes while still staying recognizably itself.
The setup also needs guardrails, because persona control only works if the prompt phase stays cleanly separated from the conversation itself. The paper says the user audio channel is replaced with a 440 Hz sine wave during prompting, and custom delimiters mark the boundary between setup and dialogue; it also notes that putting the voice prompt first can help prefilling during inference, which reduces latency when zero-shot voice cloning is not needed. That small design choice matters because it lets the assistant establish identity quickly and then move into live interaction without stumbling over the handoff.
NVIDIA reports that this design improves role adherence, voice similarity, dialog naturalness, and responsiveness on duplex benchmarks, which is exactly what you would want from a modern voice assistant. In plain terms, the model is trying to keep two promises at once: it should sound like the voice you chose, and it should behave like the character you asked for. That is the real payoff of setting voice and role in PersonaPlex 7B, and it is the piece that lets us move from raw speech generation to a conversation with a real sense of presence.
Enable Real-Time Turn Taking
Now that the model has a voice and a role, the real challenge is timing. Real-time turn taking is what keeps a voice assistant from sounding like it is reading from a queue, and PersonaPlex 7B is built to handle that live back-and-forth while you are still speaking. In the paper, NVIDIA describes it as a full-duplex speech model, which means it can listen and generate speech at the same time rather than waiting for a complete pause. That is the difference between a system that merely replies and one that can keep pace with a human conversation.
So how does real-time turn taking work in a voice assistant? The easiest way to picture it is to imagine two people at a kitchen counter, not two people waiting for a microphone to finish. PersonaPlex receives live user audio alongside its own text and audio streams, and that duplex setup lets it react to pauses, overlaps, and short acknowledgments without breaking the flow. NVIDIA’s evaluation focuses on exactly those moments — turn-taking, responsiveness, interruption handling, and backchannel handling — because those are the places where conversation usually feels most mechanical if the system is slow or unsure.
The important part is that turn taking is not only about speaking faster; it is about choosing the right moment to speak. PersonaPlex’s architecture follows Moshi and keeps the user audio stream live while the model generates its response, which is why it can produce tiny signals like brief acknowledgments instead of always waiting for a clean stop. The model card also shows that the system is designed for 24 kHz audio input, which supports a detailed, continuous speech signal rather than chopped-up segments. In practical terms, that lets the assistant behave more like a careful listener who nods at the right moment and less like a robot waiting for a green light.
The training and evaluation choices matter here, because real-time turn taking only works if the model has seen conversation that actually looks messy. NVIDIA says PersonaPlex was trained on synthetic dialogs and also on real conversational data in the released checkpoint, with the latter improving backchanneling, expressions, and emotional responses. On Full-Duplex-Bench, the released checkpoint shows strong smooth turn-taking and user-interruption results, which tells us the model is not only generating speech but handling conversational timing in a way the benchmark can measure. That is a meaningful sign for anyone asking whether an AI voice agent can keep up when a user cuts in, pauses, or changes direction mid-thought.
A small design detail also helps the system feel steadier in motion. During prompt setup, PersonaPlex uses a clean boundary between the role-and-voice conditioning phase and the live dialogue phase, and NVIDIA notes that placing the voice prompt first can reduce latency when zero-shot voice cloning is not needed. Latency is the delay between the moment you speak and the moment the assistant responds, so lowering it makes real-time turn taking feel natural instead of delayed. The GitHub repo even recommends the same prompt for pause handling, backchannels, and smooth turn taking, which is a useful clue: the model’s conversational timing is not an accident, it is something the system is explicitly trained and tested to do.
Once you see it this way, the payoff becomes clear. PersonaPlex 7B is not trying to wait politely for its turn in a rigid script; it is trying to share the conversational rhythm with you, which is what makes a voice assistant feel present instead of procedural. That is the real promise of real-time turn taking in PersonaPlex 7B: the model can hold a persona, keep its voice, and still move with the natural stop-and-start flow of human speech.
Build Voice Assistant Flows
When you start building voice assistant flows, the biggest shift is realizing that you are not scripting a chatbot reply; you are choreographing a live conversation. PersonaPlex 7B helps because it is a full-duplex speech model, meaning it can listen and speak at the same time, so the flow does not need to wait for one step to finish before the next begins. NVIDIA says this design reduces the delay that comes from the older ASR-LLM-TTS chain, where speech is first transcribed, then processed, then spoken back out.
That is why the first design choice is not the answer itself, but the role the assistant should inhabit. PersonaPlex uses a Hybrid System Prompt, which combines a text prompt for role conditioning with an audio prompt for voice conditioning, so you can set both personality and sound before the conversation starts. The paper explains that these two prompt segments are placed one after the other, and that the user audio channel is replaced with a 440 Hz sine wave during prompting so the model has a clean boundary between setup and live dialogue.
Once that identity is in place, the flow becomes easier to think about in human terms. You begin with a greeting, then leave room for the user to talk over you, pause, or change direction, because PersonaPlex is trained and evaluated for exactly those moments: pause handling, backchanneling, smooth turn taking, and interruption response. In other words, these are not edge cases to patch later; they are part of the basic rhythm of a good voice assistant flow.
So how do you build voice assistant flows that feel natural instead of brittle? Start by matching the role prompt to the task, then choose a voice prompt that fits the setting, and then decide where the assistant should listen, clarify, confirm, or hand off. NVIDIA’s examples show this clearly in assistant, banking, and medical-office scenarios, where the same underlying model behaves differently because the prompt tells it what kind of conversation it is in.
The next layer is timing, and timing is where many assistants feel awkward. PersonaPlex is designed to generate both text and audio while user speech is still arriving, which lets it produce brief acknowledgments like natural backchannels without breaking the exchange. The repository also recommends using the same conversational prompt for pause handling, backchannel, and smooth turn-taking evaluations, which is a useful clue for builders: if your flow passes those moments well, it will feel far less robotic in everyday use.
As you sketch the flow, think in scenes rather than screens. One scene is the setup, where the assistant learns its voice and role; another is the active conversation, where it reacts in real time; and a third is the recovery moment, where it handles interruption, silence, or a sudden change in intent. That structure matters because PersonaPlex was trained on synthetic and real conversations, and the paper reports strong results in role adherence, speaker similarity, latency, and dialog naturalness, which is exactly what you want when a voice assistant has to stay helpful while sounding present.
In practice, the best voice assistant flows feel less like a command line and more like shared attention. You say something, the system picks up your pace, and the conversation keeps moving without either side needing to stop and reset. That is the real promise of PersonaPlex 7B for builders: it gives us a way to design voice assistant flows that preserve identity, responsiveness, and human timing in the same breath.
Measure Naturalness and Latency
When a voice assistant starts sounding alive, the first question is not whether it can answer, but whether it can answer at human speed. That is where naturalness and latency become the real test: naturalness tells us whether the conversation feels like a conversation, while latency tells us whether the system hesitates long enough to break the spell. In PersonaPlex 7B, NVIDIA measures both by evaluating how well the model handles turn-taking, interruptions, pauses, and backchannels across Full-Duplex-Bench and an extended benchmark called Service-Duplex-Bench, which adds 350 customer service questions to the original 400.
What does a voice assistant’s naturalness actually mean? It is not about sounding polished in a vacuum; it is about behaving like a conversational partner when the dialogue gets messy. The PersonaPlex paper treats pause handling, interruption response, backchanneling, and smooth turn-taking as the core signals of conversational realism, and it reports that the model achieves strong results in dialog naturalness, voice similarity, and role adherence on those tests. That matters because a voice can sound pleasant and still feel wrong if it talks over you, misses your cue, or answers with robotic timing.
Latency deserves its own lens because a fast reply is not the same thing as a responsive reply. In the paper’s benchmark tables, latency is tracked separately for smooth turn-taking and user interruption, which is a useful reminder that there are different kinds of waiting in conversation: the pause before the assistant speaks, and the pause after you cut in mid-thought. PersonaPlex’s released checkpoint also benefits from additional real conversational data from the Fisher English corpus, which the authors say improves natural backchanneling, expressions, and emotional responses. That combination is what helps the model feel quick without sounding abrupt.
If you are wondering how to measure these qualities in practice, think like a listener rather than a tester reading off a spreadsheet. You would try short questions, overlapping speech, awkward silences, and mid-sentence interruptions, then watch for whether the assistant responds too early, too late, or with the wrong conversational rhythm. PersonaPlex’s evaluation design points in exactly that direction: Full-Duplex-Bench looks at conversational dynamics and response quality, while Service-Duplex-Bench checks whether the model still follows the role it was given in more structured scenarios. In other words, the benchmark is trying to capture the feeling of being in a real exchange, not just the correctness of a generated answer.
That is the deeper lesson hidden inside the numbers: naturalness and latency have to be read together, because a model can be quick and still feel off, or warm and still feel slow. PersonaPlex is interesting because NVIDIA does not treat those as separate goals; the paper says the model maintains responsiveness and turn-taking while improving speaker similarity and dialog naturalness, and the official project page says it is meant to preserve authentic conversational rhythm while keeping the chosen persona intact. Once you start thinking about measurement this way, the scorecard stops looking like a lab report and starts looking like a transcript of real human attention.



