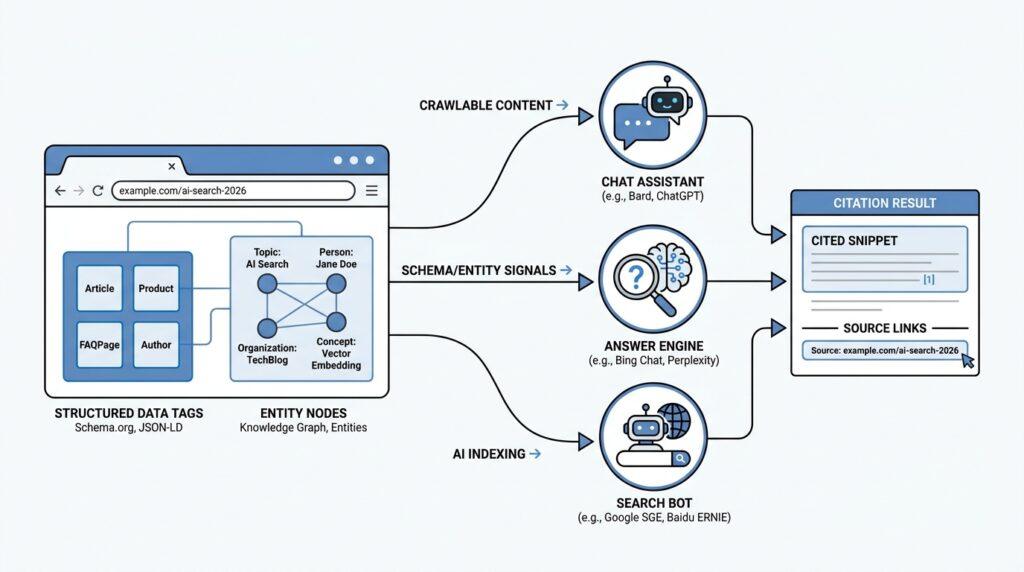
Audit AI Search Visibility
When you first look at AI search visibility, it can feel a little like standing outside a store and wondering whether anyone inside can even see your sign. You may have published the page, shared it, and waited, but the real question is different: how do we know whether ChatGPT, Perplexity, and other AI search engines can find, understand, and cite us? That is where an audit helps. ChatGPT can search the web when a question would benefit from current information, and its search responses include inline citations. Perplexity also searches the web, identifies sources, and returns cited answers, which means the page that gets seen is not always the page that gets quoted.
A good audit starts by separating “being online” from “being usable.” In search terms, crawlability means a system can fetch your page, and indexability means it can store and use that page in search results. Google’s Search Console URL Inspection tool is useful here because it shows crawl, index, and serving information, plus the canonical URL, and Google also notes that requesting a recrawl does not guarantee instant inclusion. If a page cannot be crawled or indexed cleanly, AI search visibility usually begins from a weak position, because there is nothing reliable for the system to pull from.
Next, we look at the page itself as if we were reading it for the first time. Structured data is standardized page markup that acts like a label on a box, telling search systems what they are looking at; Google says it uses structured data to understand page content and can show richer search features, but it also says that correct markup does not guarantee display. That matters for AI search optimization because clear labels, accurate page titles, and visible content make it easier for systems to interpret your page without guessing. Helpful, people-first content also matters, because Google’s guidance says its ranking systems are designed to prioritize useful information made for people, not content that exists mainly to manipulate rankings.
Now comes the part that feels most like actual fieldwork. We want to test the same kinds of questions real people ask, then watch which URLs appear, which facts get repeated, and which sources are cited. ChatGPT search may rewrite a question into specific search queries before answering, while Perplexity lets users choose sources and returns answers with numbered citations, so the exact wording of a query can change what gets surfaced. That is why an audit should include natural-language prompts such as “What is the best way to compare X and Y?” or “Which source explains this feature most clearly?” rather than only short keyword phrases.
As we test, we are not only checking whether our brand appears. We are also checking whether the right page appears, whether the cited passage matches the page’s main point, and whether an older or weaker URL keeps getting chosen instead. This is where AI search visibility becomes more than a ranking question; it becomes a source-quality question. Perplexity’s documentation emphasizes cited answers and trusted sources, and OpenAI’s help pages show that ChatGPT search is built around web sources and visible citations, so the audit should record source overlap, source freshness, and whether the same page wins across multiple prompts.
If the results look uneven, that is usually a clue, not a failure. A page that is indexed but rarely cited may need clearer introductions, tighter section headings, stronger definitions, or more explicit answers near the top, because AI systems tend to work from the text that is easiest to interpret and verify. A page that is missing entirely may need technical cleanup first, such as fixing crawl access, confirming the canonical URL, or submitting updated URLs through Search Console. The goal of this audit is not perfection; it is to build a clean baseline so we can see what AI search engines already trust, what they ignore, and where the next improvements will have the biggest payoff.
Fix Crawlability and Indexing
If the audit showed that a page is missing, weak, or oddly represented, the next move is usually unglamorous but powerful: we make the page easy to reach. Why does a page that looks fine in your browser still fail to show up in AI search? Because the crawler may never get a clean path to it, and AI search visibility starts with crawlability and indexing, not with clever wording. ChatGPT Search can surface web sources with inline citations, and OpenAI says a site must allow OAI-Searchbot to crawl it; Perplexity says its crawler, PerplexityBot, also needs permission and will not index content blocked by robots.txt.
The first place we check is robots.txt and the page’s robots meta tag, because they play very different roles. robots.txt tells crawlers where they may or may not go, while a noindex directive tells search engines not to store the page in the index; Google also notes that if a page is blocked by robots.txt, it may be hard or impossible to index properly, and the URL can still surface without a snippet in some cases. In plain language, crawl blocking keeps the door shut, while noindex lets the crawler peek inside but tells it not to file the page away. That distinction matters because crawlability and indexing are related, but they are not the same thing.
Once the crawler can enter, we need to help it choose the right version of the page. This is where the canonical URL, meaning the preferred version of a page when several URLs show nearly the same content, becomes important. Google recommends rel="canonical" for duplicate or very similar pages and specifically says not to use robots.txt for canonicalization; it also warns that noindex is not a good way to pick a canonical page because it removes the page from Search entirely. When we clean this up, we stop search engines from splitting trust across duplicate URLs and give them one version to cite.
A sitemap is the next quiet helper, and it works a little like handing a visitor a tidy map instead of asking them to wander the halls. A sitemap is a file that lists important URLs and related information so search engines can discover them more efficiently, but Google is clear that a sitemap does not guarantee every URL will be crawled or indexed. Keep the URLs absolute, keep the file at a sensible location, and submit it through Search Console so you can spot problems faster; if the site is large, a sitemap index file can group multiple sitemaps together. This is one of the simplest ways to improve crawlability and indexing without changing the content at all.
Then we look for content that exists in the browser but not in the crawl. Google Search does run JavaScript, but it has limits, and Google’s mobile-first indexing uses the mobile version of a page for indexing and ranking, so the content on mobile has to be complete and visible. If important text only appears after a click, swipe, or heavy script work, Google says it may not load that content the way a person would, and the same caution applies to other search systems that rely on rendered pages. In practice, that means the most important answer should live in the HTML or in content that appears reliably in the rendered page, not hidden behind a dramatic reveal.
The last step is to verify everything the way a search engine would. Google’s URL Inspection tool shows whether crawl is allowed, whether the page is indexable, and what canonical version Google has selected, so it is the fastest way to confirm that our fixes actually worked. This is where we loop back to the AI search prompt and ask the same real question again, because if the page is reachable, indexed, and readable, AI systems have a stable source to cite; if it is not, even excellent content can stay invisible. That is the heart of crawlability and indexing: not perfection, but making sure the right page can be found, understood, and trusted first.
Add Structured Data Markup
Once the page can be reached, the next question is whether a machine can read it without squinting. That is where structured data markup comes in: it is the page’s machine-readable label, a small layer of code that says, “this is an article,” “this is a product,” or “this is the organization behind the site.” Google says it uses structured data to understand page content, and both OpenAI and Perplexity document crawlers that look for sites they are allowed to access in search features, so clear labels help these systems make better sense of what they find.
The easiest way to think about it is this: the visible page tells a story for people, while structured data markup whispers the same story to search systems in a format they can parse reliably. Google recommends JSON-LD, which stands for JavaScript Object Notation for Linked Data, and it treats that format as the preferred option among the supported structured data types. The important part is that the markup must match the actual page content; Google’s guidelines warn that even syntactically correct markup can lose eligibility if it is misleading or low quality.
If we are working on a blog post, Article markup is usually the first piece to add. Google’s Article documentation says to use Article, NewsArticle, or BlogPosting, and to include as many recommended properties as fit the page, such as author, author URL or sameAs, and dateModified. That sounds technical, but the idea is friendly: we are helping the crawler connect the words on the page to a real writer, a real publication date, and a real subject, which makes the page easier to understand and easier to trust.
Then we widen the lens and label the page’s home base, not just the article itself. Organization markup tells Google about your company name, logo, address, contact details, and identifiers, and Google says that can help disambiguate your organization in search results. BreadcrumbList markup does something similar for navigation by showing where the page sits in the site hierarchy, while Product markup is the right fit for product pages because it can describe price, availability, and review ratings. In other words, we do not spray schema everywhere; we choose the type that honestly matches the page in front of us.
Picture a comparison page as a tidy desk instead of a pile of loose papers. Without structure, the crawler sees a wall of text and has to guess which line matters most; with structured data markup, we hand it labeled folders: one for the article, one for the author, one for the organization, and one for the page’s place on the site. That is especially helpful when the page includes several moving parts, because Google says structured data can influence richer search features and, for organization data, help it understand how entities relate to one another.
After the markup is in place, we test it the same way a cautious gardener checks the soil before planting again. Google’s Rich Results Test supports JSON-LD, RDFa, and Microdata, and it shows which rich result types it finds along with any errors or suggestions. Google also recommends using the URL Inspection tool and reminds us that rich appearance is not guaranteed, so passing validation does not mean a page will always surface as a citation or rich result; it only means we have removed a major layer of guesswork.
The last thing to protect is consistency, because structured data works best when the markup, the page copy, and the page purpose all tell the same story. If the visible text says one thing and the markup says another, we make the machine do extra detective work, and that usually helps nobody. So as we refine AI search optimization, structured data markup becomes one of our quiet advantages: it does not replace clear writing, but it gives ChatGPT, Perplexity, and other search systems a cleaner map to follow when they decide what to cite.
Write Citation-Ready Answers
When someone asks ChatGPT or Perplexity a question, the answer is no longer a block of text floating in space. ChatGPT search can look up current information and show inline citations, and Perplexity is built around cited answers and source-backed results, so the page that gets quoted has to be readable in one clean piece. That is why citation-ready answers matter in AI search optimization: we are not writing for the whole internet at once, but for the exact paragraph an AI system may lift, verify, and cite.
The easiest way to help that process is to answer the question first, then explain. If a visitor lands on the page and wonders, “What does this mean?” the first sentence should give them the answer in plain language, not make them hunt for it. Google’s FAQPage and QAPage guidance both ask for the full question and the full answer text, and its featured snippet documentation notes that the search result can reverse the usual format and show the descriptive answer first; in practice, that means the strongest passage is the one that stands alone without extra setup.
From there, we make the passage easy to trust. A citation-ready answer names the thing being discussed, gives the key detail, and adds the smallest amount of context needed to make the claim complete: the date, the number, the product name, the policy name, or the specific condition. Google’s structured data guidance says markup must reflect what is visibly on the page, and it warns that hidden, misleading, or incomplete content can make even correct markup ineligible, so the answer in the body copy should match the facts we want AI search engines to quote. In other words, if the page says one thing and the answer says another, we have made the crawler do detective work, and that usually weakens citation chances.
This is also where wording starts to matter more than we expect. ChatGPT search may rewrite a prompt into specific web queries before answering, and Perplexity lets users search across web sources and other connected sources, which means the exact phrasing of our answer can influence whether the right passage matches the right question. So we write with the same vocabulary a reader would use: if the question is about “crawlability,” we define crawlability in the sentence where we use it; if the question is about “canonical URLs,” we name the preferred page and say why it is the preferred one. That way, the answer is not only accurate, but also easier for an AI system to map back to the prompt it is trying to solve.
A useful test is to read one paragraph as if it were the only thing the model could quote. Does it still make sense on its own? If the answer is yes, we are close to citation-ready writing; if not, we probably need to add the missing noun, trim the side story, or move the core fact closer to the front. We want the reader to feel a smooth path from question to answer, because that same smoothness makes AI search visibility stronger: the page becomes easier to summarize, easier to verify, and easier to cite. That is the quiet craft behind citation-ready answers, and it is one of the most practical ways to help ChatGPT, Perplexity, and other AI search engines choose your page with confidence.
Build Topical Authority
If the first sections helped us make the site visible, this next step is about making it feel dependable. In AI search optimization, topical authority is the quiet signal that says, “this site has done the work, and it keeps doing the work.” When ChatGPT, Perplexity, and other AI search engines decide what to cite, they are not looking for a single lucky page; they are looking for a source that consistently explains a subject well, from the ground up. So the real question becomes: how do we build topical authority without sounding repetitive or forced?
We start by thinking like a reader who has just discovered us for the first time. If someone asks about one narrow problem, do we answer only that problem, or do we also help them understand the surrounding ideas that give it meaning? A strong site does both. It offers one clear answer, then surrounds it with related pages that cover the same topic from neighboring angles, like turning a flashlight on a room and then slowly revealing the rest of the furniture. That shape helps AI search engines see a pattern instead of a one-off page.
This is where content depth matters more than content volume. Topical authority does not mean publishing endlessly; it means covering a subject so thoroughly that the reader can move from beginner questions to practical decisions without leaving the site. One page might define a term, another might compare approaches, and a third might solve a common mistake. Together, those pages tell AI search engines that your site is not guessing. It has a point of view, and it has enough surrounding context to support that point of view.
The next piece is consistency, because authority grows when the same theme shows up again and again in a coherent way. If one article talks about AI search optimization in plain language, another uses the same core vocabulary, and a third expands the same ideas with fresh examples, the site starts to look organized rather than scattered. That consistency matters for topical authority because search systems can more easily connect the dots between pages, authors, and subjects. In other words, we are not chasing isolated wins; we are building a body of work that reinforces itself.
It also helps to write from the edge of real user questions. What are people asking before they are ready to buy, compare, or implement something? What do they need to understand before the main idea finally clicks? When we answer those questions with care, we create supporting pages that feel useful on their own and also strengthen the larger topic cluster. That is one reason AI search engines tend to trust sites that explain terms, resolve confusion, and walk through decisions instead of jumping straight to persuasion.
Internal linking is the bridge that makes the whole structure visible. An internal link is a link from one page on your site to another page on the same site, and it helps readers move naturally from one idea to the next. For topical authority, those links should feel like conversation, not decoration: the definition page points to the how-to guide, the how-to guide points to the comparison, and the comparison points back to the core explainer. That loop shows both people and AI search engines that the topic has a home.
Freshness matters too, but not in a frantic “post something every day” way. A page earns more trust when it stays accurate, reflects new terms or examples, and shows that someone is still tending the garden. That might mean revisiting old articles, merging thin pages, or expanding sections that have become too shallow. In AI search optimization, a strong site often looks less like a pile of disconnected posts and more like a living library, where each new piece makes the older pieces easier to understand.
Over time, this is what turns visibility into citation potential. A site with topical authority gives AI search engines more than one useful page; it gives them a reliable map of the subject, written in the same voice and organized around the same ideas. That is why building topical authority is not separate from the rest of the process we have been following. It is the part where good pages stop standing alone and start working together, which is exactly what makes a site feel worth citing.
Track AI Citations
Once the page is live and readable, the work changes from building to listening. This is the moment where AI search visibility starts to feel real, because we stop asking, “Did we publish it?” and begin asking, “Was it actually cited?” ChatGPT search returns answers with inline citations and a sources panel, while Perplexity presents itself as an answer engine that searches the web, identifies sources, and includes citations in its responses. That means tracking AI citations is partly about watching the answer, but it is also about watching the source path that led there.
The easiest way to begin is with a small, repeatable prompt log. We pick the questions real people would ask, run them the same way each week, and write down which URL was cited, what sentence was quoted or paraphrased, and whether the answer used our page or a competitor’s. This matters because both ChatGPT and Perplexity can rewrite a user’s wording into search queries, so a tiny change in phrasing can change the cited source. In practice, we are not chasing one perfect screenshot; we are looking for a pattern we can trust.
As we do that, we should track more than presence alone. A citation can be a win, but the bigger question is whether the cited passage actually supports the main point we wanted to own. If the AI keeps citing an older page, a broader guide, or a competitor’s explainer, that is a clue that our content is either too vague, too thin, or not the clearest match for the prompt. This is where AI search visibility becomes a source-quality game: we want the right page, the right section, and the right answer all showing up together.
Search Console gives us the other half of the story. Its Performance reports show impressions, clicks, click-through rate, and average position, which helps us see whether branded and topic-related searches are growing after AI citations start appearing. The URL Inspection tool then tells us what Google knows about a specific page, whether it is indexable, and which canonical URL Google has selected, which is useful when a citation disappears and we need to check whether the page is still being seen as the main version. If the page is not stable in search, it is rarely stable in AI citations either.
We also want to watch the crawler side of the story, because a citation cannot happen if the system cannot reach the page in the first place. OpenAI says ChatGPT search may browse the web and show sources when search is enabled, and Perplexity documents that PerplexityBot should be allowed in robots.txt if you want the site to appear in Perplexity search results. So when citations drop, we do not assume the answer engine changed its mind; sometimes the page simply became harder to fetch, index, or prefer.
A useful tracking habit is to separate short-term noise from durable signal. If a page gets cited once after a fresh update, that is encouraging, but if it keeps getting cited across multiple prompts, multiple weeks, and multiple answer engines, then we are seeing something stronger than luck. We can also compare which query styles produce citations, because question-based prompts often reveal different results than keyword-heavy ones. That comparison tells us where our AI search optimization is actually working and where the page still needs clearer definitions, stronger opening answers, or tighter structure.
The final habit is to turn these notes into a simple before-and-after story. When we update a page, we re-run the same prompts, check the same citations, and compare the same metrics in Search Console so we can see whether the change affected visibility, clicks, or source selection. That gives us a practical feedback loop: if a page earns more citations, we keep the shape that worked; if it vanishes, we look first at crawl access, canonical choice, and answer clarity before we rewrite the whole thing. In other words, tracking AI citations is how we make AI search visibility measurable instead of mysterious.