Understanding CQRS and Event Sourcing
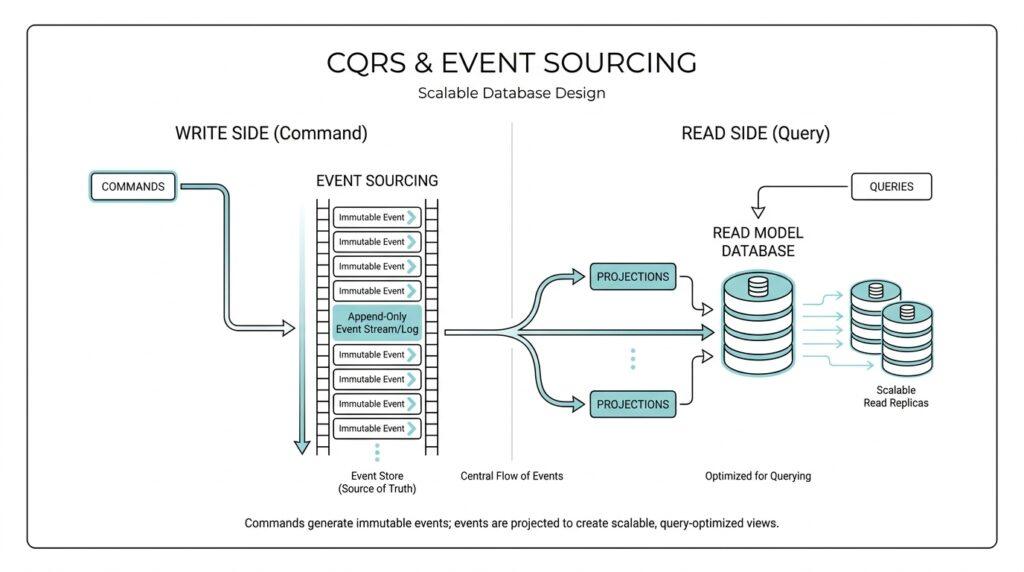
Imagine you are building an app where one screen needs a lightning-fast list of recent orders, while another screen needs to validate a brand-new purchase with strict business rules. That is the moment CQRS, short for Command Query Responsibility Segregation, starts to make sense: it splits the work of commands (actions that change data) from queries (requests that read data). In practice, the write model handles updates, validation, and business rules, while the read model shapes data for display and fast lookup. Instead of forcing one model to wear both hats, CQRS lets each side do one job well.
Why bother splitting them at all? Because read and write traffic usually do not behave like twins. A traditional CRUD system—create, read, update, delete—often uses one data model for everything, which is fine until the application grows and the same structure has to serve dashboards, forms, filters, and transactions at once. Microsoft’s guidance notes that this overlap can lead to performance problems, lock contention, and overly complicated models, especially when reads and writes need different scaling strategies. CQRS gives you room to tune those paths separately, and in its basic form it can even do that while still sharing a data store.
Now event sourcing enters the story, and it changes how we think about storage. Instead of saving only the latest state, an event-sourced system records the full sequence of meaningful changes as an append-only stream, which means new events are added but old ones are not rewritten. An event is a fact about something that happened, such as OrderPlaced or PaymentCaptured, and the event stream becomes the source of truth. To reconstruct the current state, the system replays those events in order, much like reading a diary page by page instead of only looking at the last entry. That history is valuable because it preserves intent, not just outcome.
This is where CQRS and event sourcing often travel together. The event store feeds the read side by producing projections, which are precomputed views of the data tailored for queries, often called materialized views when they are stored for fast reuse. The write side keeps the business history intact, while the read side can be denormalized, meaning it is arranged for quick retrieval rather than for perfect storage symmetry. If a product team later needs a new report or a different screen, we can often rebuild that projection from the same stored events instead of changing the write path. That flexibility is one of the biggest reasons people pair CQRS with event sourcing.
Of course, this extra power comes with a trade-off: the read model may lag behind the write model for a short time. That delay is called eventual consistency, which means the system will converge, but not necessarily instantly, and users may briefly see stale data after a change. This is not a flaw so much as a design choice, like sending a letter and waiting for the reply instead of holding both conversations in the same breath. The upside is that the architecture can scale and adapt more cleanly; the cost is that we must think carefully about duplicates, retries, and the moment when a command has been accepted but the projection has not caught up yet.
So what is CQRS and event sourcing in simple terms? CQRS separates the act of changing data from the act of reading it, and event sourcing keeps a permanent journal of every important change. Together, they help us model complex systems in a way that feels closer to how real business events unfold: one event at a time, in order, with a clear record of what happened. That makes the architecture especially useful when the domain is busy, the rules are rich, and the read experience needs to stay fast without sacrificing history.
Separate Commands From Queries
Now that we’ve seen CQRS and event sourcing working together, the next move is to make the split feel concrete: commands and queries travel on different paths. A command is a request to change something, such as placing an order or reserving a seat, while a query asks for information without changing state. Microsoft’s CQRS guidance frames this as separate read and write models, and Martin Fowler describes CQRS as separating the structures used for reading from those used for writing.
If you’ve ever wondered, “Why not use one model for everything?”, this is where the story gets interesting. As systems grow, the same data shape starts to feel like a desk that must also be a toolbox, a filing cabinet, and a checkout counter at once. Microsoft points out that read and write paths often have different performance needs, can create lock contention when they compete for the same data, and may even raise security concerns when the same entity serves both jobs. CQRS gives each side its own lane so the application does not have to compromise as much.
On the command side, we focus on intent and rules. This is the part of CQRS that decides whether a change is allowed, which means the write model carries validation, domain logic, and consistency checks before anything is persisted. You can think of it as the kitchen at a busy restaurant: it does not try to present the menu board, it concentrates on checking the order, preparing the meal, and making sure the right ingredients are used. In event-sourced systems, this side often produces events that record what happened, rather than overwriting the past, which is why the command path feels so deliberate.
On the query side, we switch to a different concern entirely: making information easy to fetch and easy to show. The read model can be shaped into DTOs, or data transfer objects—plain objects built for moving data to the UI—so it stays simple and fast. Microsoft notes that read models are often projections or materialized views, meaning precomputed views of the data that are optimized for querying rather than for preserving every rule of the domain. If event sourcing is in the picture, those projections are often rebuilt from the event stream, which gives us a flexible way to create new screens or reports without disturbing the write model.
That split does introduce a small wrinkle: the read side may lag behind the write side for a short time. This is called eventual consistency, which means the system will converge, but not instantly, so a user might briefly see old data right after a command succeeds. Microsoft warns that this delay creates stale-read scenarios, especially when reads and writes live in separate stores, so CQRS asks us to think carefully about retries, idempotent processing, and how the UI should behave while projections catch up. The trade-off is worth it when we want CQRS and event sourcing to scale cleanly without forcing one model to do two incompatible jobs.
So the practical habit is surprisingly simple: let commands carry change, and let queries carry answers. Once you start treating them as different conversations, the design becomes easier to reason about, and the architecture stops fighting itself. That separation is the bridge between the business story you want to tell and the data shape your users need to read, which is exactly why CQRS feels so useful when a system starts to grow.
Design the Event Store
Once we decide to keep history instead of overwriting it, the event store becomes the heart of the system. In a CQRS and event sourcing setup, this is not a side table or a log file we glance at later; it is the place where business facts live in order, one after another. The easiest way to picture it is as a ledger with no eraser. Every important change gets written as a new event, and the event store preserves that sequence so we can rebuild state, audit decisions, and understand how the system arrived where it is.
That means the first design choice is also the most important: store events as immutable records. Immutable means unchangeable after write, so once an event is accepted, we do not edit or delete it to “fix” history. Instead, we add a new event if something new happens, which keeps the record honest and traceable. What should be in each record? We usually want the event type, the event data, a timestamp, and identifiers that tell us which business object it belongs to, because the event store needs to answer not only what happened, but also when, where, and in what order.
From there, we need a shape that helps the system stay understandable. A common pattern is to store events in streams, which are ordered sequences of events for one business entity or aggregate, meaning a cluster of data that must stay consistent together. This helps us avoid mixing unrelated stories in the same place, the way we would not keep every family’s letters in one envelope. If you have ever asked, “How do you design an event store so it scales without becoming a mess?”, this stream-by-stream structure is a big part of the answer, because it keeps ordering clear and replay predictable.
Next comes the practical work of making the event store useful to other parts of the application. We often add metadata, which is extra information about the event, such as a correlation ID and a causation ID; a correlation ID links events that belong to the same business operation, while a causation ID shows which event triggered another one. That small layer of detail becomes incredibly helpful when something goes wrong and we need to trace the story across commands, projections, and retries. We also need a version number for each event schema, which is the structure of the data, because event sourcing works best when old events still make sense after the model evolves.
Versioning deserves special care because the event store must outlive the code that writes to it. If we rename a field or split one event into two, we cannot pretend the old data never existed; we need a plan for reading old events and interpreting them correctly. That is why teams often treat events as a public contract, meaning a promise about meaning and shape, rather than as a temporary implementation detail. The safest habit is to keep events focused on business facts, not UI details, so the event store remains stable even when screens, services, and workflows change around it.
We also have to think about concurrency, which is what happens when two writers reach for the same stream at the same time. A good event store protects the order of events by checking the expected version of a stream before accepting a new write, so we do not accidentally overwrite a newer change with an older one. Under the hood, the storage engine may still partition data for performance, but the business rule stays simple: one history, one order, no silent collisions. That is what keeps CQRS and event sourcing trustworthy when many users, services, or processes are writing at once.
So when we design the event store, we are really designing for truth, replay, and growth all at once. We want a structure that can keep every meaningful change, protect the order of those changes, and survive future model updates without losing the story. Once that foundation is solid, the read side can evolve freely, because the event store gives us a durable source of truth to build from. And that is the quiet power of CQRS and event sourcing: the system stays flexible because its memory stays precise.
Build Read Models and Projections
Once the commands have written events, the query side gets to do its own quiet work. This is where a read model steps in: it takes the raw history of the system and reshapes it for the way people actually look at data, whether that is a dashboard, a search screen, or a support tool. How do we make the query side feel fast without asking the write side to do extra work? We build a separate view of the world that is optimized for reading, not for enforcing business rules.
A read model is easiest to picture as a well-organized storefront window. Behind the curtain, the system may store rich, complicated business events, but in front, the query model only shows the pieces a user needs right now. Microsoft describes read models as data shaped for queries, often returned as DTOs, or data transfer objects, and sometimes as projections or materialized views that avoid expensive joins and heavy mapping. In plain language, we are trading perfect symmetry for speed and clarity, because the question on the screen is usually much simpler than the history that produced it.
That is why projections matter so much. A projection is a handler that listens to events and updates the read side one event at a time, turning an event stream into a query-friendly shape. In an event-sourced system, those projections can be rebuilt from the stored history, which means we can create a new view later without changing the write path or losing the story of what happened. That flexibility is one of the quiet strengths of CQRS and event sourcing: the past becomes reusable material, not just archived data.
The next thing to notice is that projections do not have to update instantly. Because the read store usually follows the event store asynchronously, there is often a small delay before the newest change appears in a query result, and that delay is called eventual consistency. In practice, this means a user might place an order and see the confirmation before the order appears in a list view, which can feel odd at first but is normal in this design. The important part is that we set expectations clearly and make the UI and retry logic resilient to briefly stale data.
As we start building projections, it helps to think in use cases instead of in tables. One projection might power a customer’s order history, another might feed an admin report, and a third might summarize activity for a live dashboard. Microsoft notes that the read store can even use a different schema or storage technology from the write side, which is useful when one view wants document-style access and another benefits from a relational shape. That is the real advantage here: each projection can be tuned to the question it answers best.
There is also a practical maintenance habit that keeps projections healthy over time. Because long event streams can become expensive to replay, Microsoft recommends snapshots at regular intervals for situations where rebuilding a view from the beginning would take too long. A snapshot is a saved checkpoint of state at a point in the history, which gives the projection a head start when it catches up again. We are not replacing the event stream; we are giving the read side a shortcut so it can stay responsive as the history grows.
When this part is designed well, the whole system starts to feel less like one giant database and more like a set of specialized windows onto the same story. The write side keeps the truth, the event stream preserves the timeline, and the read models turn that timeline into something people can browse quickly and confidently. From here, the next challenge is making those projections reliable enough to survive real traffic, retries, and change without losing their shape.
Manage Eventual Consistency
Picture the moment right after a user clicks Place order and gets a success message, but the order history screen still looks unchanged. That tiny gap is where eventual consistency shows up in CQRS and event sourcing: the write side has accepted the change, but the read model is still catching up. Microsoft’s guidance is explicit that separate read and write stores can drift for a short time, and that this delay can produce stale data while projections refresh. The goal is not to hide that gap; it is to design for it so the system stays fast without pretending every view updates in the same instant.
So how do we keep CQRS and event sourcing honest when the read side lags? We start by treating the command response and the query result as two different promises. The command says, “your change has been accepted,” while the query says, “here is the latest view I have available.” Microsoft recommends preparing customers for this behavior because projections are updated after the event is stored, published, and processed. In practice, that means using clear confirmation messages, gentle loading states, and refresh behavior that does not make users feel like the system forgot what they just did.
Once that expectation is set, the next safeguard is making event handling resilient. Event-driven systems commonly deliver messages at least once, which means a projection may see the same event more than once, especially during retries or consumer restarts. That is why Microsoft recommends idempotent event handlers, meaning handlers that produce the same result even if they process a duplicate event. If an order-confirmation event arrives twice, the read model should not count it twice. This is one of the quiet but important habits that keeps CQRS and event sourcing stable under real traffic.
The write side needs care too, because eventual consistency does not remove the possibility of conflict; it only moves where we manage it. In an event-sourced system, Microsoft describes using optimistic concurrency control, which checks whether the stream changed since it was read and rejects the append if it has. If that happens, the handler reloads the entity, re-evaluates the command, and retries. That pattern matters because it keeps the source of truth accurate even when many users act at once. In other words, the read model may be slightly behind, but the event stream itself still protects the real business history.
This also means we should be careful about where we trust the read model. A projection is perfect for fast browsing, filtering, and display, but it should not become the final authority for decisions that need the newest truth. If a command depends on a critical rule, we validate it on the write side against the aggregate or entity rehydrated from the event stream, not against a possibly stale screen. That is the practical shape of eventual consistency: the UI can lag a little, but the business decision still comes from the consistent side of the architecture.
The last habit is choosing where this trade-off belongs. Martin Fowler notes that CQRS should usually live inside specific bounded contexts rather than across an entire system, because separate models increase the work of keeping them aligned. Microsoft makes a similar point for event sourcing: use it when eventual consistency is acceptable, and avoid it when your domain truly needs immediate real-time views everywhere. That is the balancing act we are really learning here: CQRS and event sourcing give us scale and flexibility, while eventual consistency asks us to design clear boundaries, smart retries, and user experiences that can breathe for a moment before the full picture appears.
Scale With Partitioning and Sharding
Once CQRS and event sourcing are already separating reads from writes, the next pressure point is volume. Partitioning means splitting data into smaller slices; sharding means placing those slices on different machines or storage nodes. In practice, that lets us spread event streams, read models, and query traffic so one busy customer, tenant, or report does not slow everything else down. If the architecture is a library, partitioning is the way we sort the shelves, and sharding is the moment we open extra rooms when one shelf starts to overflow.
The first question is where to draw the lines. In an event-sourced system, we usually want each business stream, such as an order or account, to stay in one partition so its events remain in order. That protects the story we have been carefully preserving, because replay only makes sense when the events arrive in the same sequence they were written. For read models, the line can be different, because queries care more about convenience than about preserving a single timeline.
That difference matters more than it first appears. If you partition the write side by aggregate ID—the identifier for the business object that must stay consistent—you keep related events together and avoid cross-stream confusion. If you partition the read side by tenant, region, or customer group, you can answer the most common queries from a smaller, faster slice of data. So when we ask, “How do we scale CQRS and event sourcing without turning the database into a traffic jam?”, the answer starts with matching the partition key to the way the system actually works.
Sharding takes that same idea and stretches it across multiple servers. A shard is a separate chunk of data that lives on its own storage node, so one machine does not have to carry the entire load. This is especially useful when the event store grows so large that replay, indexing, or retention tasks begin to crowd each other out. The shape of the shard key matters here, because a poor choice can create a hot shard, which is a shard that gets far more traffic than the others and becomes the new bottleneck.
That is why the key should reflect the rhythm of the workload, not just the shape of the data. Hash partitioning uses a calculated value to spread records evenly, which is helpful when we want balance and predictable distribution. Range partitioning groups records by a value such as time or tenant, which can make time-based cleanup or tenant-specific reporting easier. Each approach trades one kind of convenience for another, and the right choice depends on whether you care more about even load, fast lookups, or easy maintenance.
The read side often benefits the most from this flexibility. Projections and materialized views can be split apart so different screens or reports live on different shards, each tuned for its own query pattern. A dashboard that refreshes every few seconds does not need to share storage with a monthly billing report, and a customer-facing search page should not wait behind an internal audit export. By letting the read model scale separately, CQRS and event sourcing keep the query layer fast without forcing the event store to carry every workload in one place.
The write side needs more care, because ordering still matters. If commands for the same aggregate land on different shards, we risk breaking the very consistency rules that event sourcing depends on. That is why many teams keep each aggregate or event stream pinned to one shard, while using the shard key to spread different aggregates across the cluster. The idea is a little like assigning each family to its own mailbox: the mail can travel anywhere, but the letters for one household still arrive in the right order.
There is also a human side to this design. Partitioning and sharding make the system larger, but they also make it more local, because each slice can be monitored, tuned, and recovered on its own. If one shard grows hot, we can rebalance it; if one partition needs a new index, we can rebuild it without pausing the whole application. That is the real promise here: CQRS and event sourcing stay readable at the business level, while partitioning and sharding do the hard physical work of keeping the system responsive as it grows.