DeepSeek’s Cost Advantage (cnbc.com)
If you have been wondering why DeepSeek’s cost advantage startled so many AI companies, the answer starts with a simple idea: do more with less. Instead of waking up the entire model for every token, DeepSeek built around a Mixture-of-Experts system, which is a setup that sends each request to only the most relevant “specialists,” like calling in the right mechanic instead of the whole garage. In its V3 technical report, DeepSeek says the model has 671 billion total parameters, but only 37 billion are active for each token, and it says that design helped it reach performance comparable to leading closed-source models with far less training spend.
That design choice matters because AI costs pile up in two places: training, which is the expensive process of teaching the model, and inference, which is the work it does after training when people actually use it. DeepSeek’s report leans on a bundle of efficiency tricks, including FP8 mixed-precision training, which uses lower-precision numbers to save memory and bandwidth, plus heavy overlap between computation and communication so the hardware is not sitting idle. The company also says it reduced the need for costly tensor parallelism, a method that normally splits one huge model across many chips and can create a traffic jam of data movement.
So how did DeepSeek keep the cost so low? The clearest answer is in its own numbers: the V3 report says pre-training, context extension, and post-training together came to 2.788 million H800 GPU hours, or about $5.576 million if those GPUs are rented at $2 an hour. It also says the main pre-training run finished in less than two months on a 2,048-GPU cluster, which is the kind of detail that makes the DeepSeek cost advantage feel less like magic and more like disciplined engineering.
But the story is not as neat as one headline price. Nature later reported that DeepSeek’s peer-reviewed R1 paper put the model’s training cost at about US$300,000, and it said the model did not depend on being trained on rivals’ outputs. At the same time, DeepSeek’s own V3 report says its quoted cost figures cover only the official training run and leave out earlier research, architecture tests, and ablation experiments, which are the trial runs researchers use to see what is actually working. That means the number is real, but it is not the same thing as the full lifetime cost of building the system from scratch.
That caution is why some experts stayed skeptical even as the market reacted. CNBC reported that not everyone was convinced by DeepSeek’s claims, and TechCrunch noted that analysts still had questions about the true cost of R1, the training data, and how easy the results would be to reproduce. In other words, the DeepSeek cost advantage changed the conversation, but it did not end the argument; it forced the industry to ask whether better architecture, better data, and better training discipline can outrun a bigger budget.
For readers trying to make sense of all this, the practical lesson is that cheap does not mean careless. It means DeepSeek found places where compute was being wasted and trimmed them away, the way we stop paying for rooms we are not using. That is why the next stage of AI competition may hinge less on who can buy the most chips and more on who can make each chip do the most useful work.
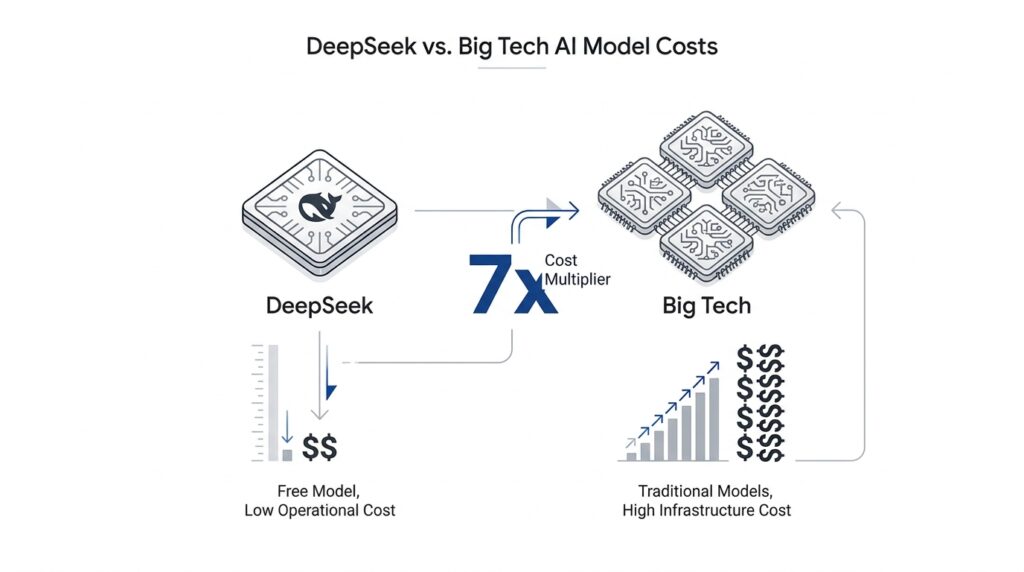
Why Big Tech Pays More (cnbc.com)
We already saw how DeepSeek squeezed a lot of performance out of a relatively lean training setup, but the Big Tech side of the story is different: it pays for AI infrastructure that has to stay online, answer requests instantly, and grow with demand. Why does Big Tech pay more to match the same model? Because it is not buying one training run; it is buying a living service. Microsoft said it plans to spend about $80 billion on AI-enabled datacenters in fiscal 2025, and Meta said it expected $60 billion to $65 billion in capital expenditures for 2025 to keep building out its AI stack.
That gap starts with the difference between training and inference. Training is the long classroom phase where a model learns; inference is the moment it meets real users and has to respond on the spot. NVIDIA’s guidance is blunt about that reality: deployed AI systems must handle real-time responses, spikes in traffic, multiple query types, and many deployment environments, all while keeping quality of service high. In plain language, the model may be finished, but the bill is only getting started.
This is where Big Tech pays more in a very practical way. A consumer app, a chatbot, or an enterprise assistant cannot afford to be slow, unavailable, or fragile, so the company has to provision extra servers, monitoring, networking, power, and cooling around the model itself. NVIDIA’s inference overview emphasizes that production systems need to deliver the highest service with the fewest servers, while still balancing latency, throughput, accuracy, and efficiency. That means the real challenge is not only building the model; it is serving it at scale without letting the user experience fall apart.
DeepSeek’s own numbers also help explain why the headline training cost can be misleading. Its V3 technical report says the model used 2.788 million H800 GPU hours for full training, but that figure covers the official run, not the earlier experiments, architecture work, and other research that came before it. SemiAnalysis argued that DeepSeek’s hardware spend was well above $500 million over the company’s history and that total server capital expenditure and operating costs were much larger than the simple training bill. So when Big Tech pays more to match a model, it is often paying for the full industrial footprint, not just the final experiment.
That is why the comparison is a little like comparing the cost of baking one loaf of bread with the cost of running a city bakery chain. DeepSeek’s efficiency shows that a smarter recipe can cut waste, but Big Tech still has to keep the ovens hot all day, in many locations, for many customers, with backup systems ready when demand surges. Microsoft describes its datacenter buildout as the foundation for training models and deploying cloud applications around the world, and Meta’s own spending plans point in the same direction: the money goes into the roads, power, and servers that let AI become a product instead of a demo.
So the real answer is not that Big Tech is careless with money. It is that Big Tech is paying for scale, reliability, and nonstop availability, while DeepSeek’s story is about trimming the model itself. That difference sets up the next question: once a model becomes a mass-market service, who can afford to run it at the lowest cost per user?
Efficiency Tricks Behind the Model (apnews.com)
When you look under the hood, the DeepSeek efficiency tricks are not one magic switch. They are a chain of small choices that keep the model from wasting work, memory, and time. The model still has 671 billion total parameters, but only 37 billion activate for each token, so the system behaves more like a carefully routed team than a giant engine that has to roar at full power every time. If you are wondering, “How can a model this large train so cheaply?”, the answer starts with that kind of discipline.
The first piece of the story is routing. DeepSeek pairs its mixture-of-experts design with Multi-head Latent Attention, or MLA, which is a way of keeping attention lighter so the model does not carry more information than it needs during inference. You can think of it like a busy hospital using triage: not every doctor sees every patient, and not every part of the model wakes up for every token. DeepSeek also adds an auxiliary-loss-free load-balancing strategy, which matters because a routed system can become lopsided if too many requests pile onto the same experts. In plain language, the model tries to keep its specialists busy without forcing them into a traffic jam.
The next trick is FP8 mixed precision training, and this is where model efficiency gets very practical. FP8 means the model uses 8-bit numbers for part of training instead of larger, heavier number formats, which cuts memory use and reduces the amount of data that has to move around. That may sound like a tiny adjustment, but at this scale, tiny adjustments become enormous savings, like replacing a fleet of moving trucks with smaller delivery vans. DeepSeek says FP8 helped it speed up training and lower GPU memory usage, and it describes the approach as being validated on an extremely large model for the first time. In other words, the model does not just think hard; it stores and moves information more efficiently too.
Then comes the part that many readers miss: the training system itself does not stand still while the model computes. DeepSeek’s DualPipe setup overlaps computation with communication, which means the GPUs can keep working while data is being passed between nodes in the background. That is a little like loading the next tray in a bakery while the current batch is still in the oven. The paper says this reduces pipeline bubbles, hides most communication during training, and helps achieve near-full overlap, which is a big reason the DeepSeek efficiency story is about systems engineering as much as it is about model design.
This is also why the model can avoid some of the most expensive old habits in large-scale training. DeepSeek says it optimized memory so carefully that it could train without costly tensor parallelism, a method that usually splits one model across many chips and can create a lot of extra coordination overhead. It also built efficient cross-node all-to-all communication kernels to better use InfiniBand and NVLink bandwidth, which are the highways GPUs use to talk to each other. That combination of routing, low-precision math, and communication overlap is the real answer behind the model efficiency story: the system trims dead time at every layer, so the hardware spends more time learning and less time waiting.
Seen that way, DeepSeek’s headline cost is not a mystery number floating in space. It is the result of a model that activates only the experts it needs, stores information in a leaner format, and keeps its chips busy instead of idling at traffic lights. DeepSeek says those choices let it complete training with 2.788 million H800 GPU hours, but the larger lesson is even more useful: in modern AI, the winners are often the teams that find the hidden waste first. That idea is what makes the next comparison so interesting, because once the model is built efficiently, the question shifts from how to train it to how to run it well at scale.
Benchmarking Performance Differences (scientificamerican.com)
After we understand how DeepSeek trimmed training waste, the next question becomes the one everyone really cares about: did it do that without losing quality? That is where benchmark performance differences enter the story. A benchmark is a standardized test for an AI model, the way a final exam checks what a student can do under the same conditions as everyone else. In Scientific American’s coverage, DeepSeek-R1 reportedly matched OpenAI o1 on common math and coding tests, while DeepSeek’s own V3 technical report says the model reaches performance comparable to leading closed-source systems.
But a benchmark is still only one kind of test, and not all tests ask the same question. A model can look excellent on math problems, for example, and look less impressive when it has to handle long, messy, real-world work. METR’s evaluation of DeepSeek-V3 found that, on AI R&D tasks, the model performed on par with Claude 3 Opus, slightly better than GPT-4o, and clearly below Claude 3.5 Sonnet and o1. In the same report, METR said that with 8 hours per task, DeepSeek-V3 performed like a 24th-percentile human expert, which gives us a more grounded picture of DeepSeek benchmark performance outside the usual headline numbers.
This is why benchmark performance differences can be so confusing at first glance. What do DeepSeek benchmark results really mean if one suite says near-parity and another shows a wider gap? Part of the answer is that evaluation methods matter as much as the model itself. OpenAI’s evaluation guidance says comparisons become more reliable when we use clear criteria, pairwise comparisons, and scoring rules that match the task, and it warns that effects like response-length bias and position bias can distort results. In other words, the test setup can quietly change the score, the way lighting can change how a room looks in a photograph.
That is also why researchers pay so much attention to contamination, which means a model may have seen benchmark questions, or close versions of them, during training. METR specifically checked DeepSeek-V3 against the original GPQA Diamond benchmark, a paraphrased version, and a held-out set of GPQA questions, and found the model stayed consistently better than GPT-4o and slightly below Claude 3.5 Sonnet. Because the results held up across those versions, METR said contamination seemed unlikely to explain the benchmark outcome. That does not prove every score is perfect, but it does make the DeepSeek benchmark performance story look more credible than a single polished leaderboard number might suggest.
Seen together, these results tell a familiar story: DeepSeek looks especially strong when the task is narrow, measurable, and easy to score, but the gap can narrow or widen when we move into more realistic work. That is not a contradiction; it is a reminder that AI benchmarks are like different mirrors, each reflecting a slightly different face of the same model. DeepSeek benchmark performance is impressive enough to unsettle bigger rivals, yet the real lesson is that speed, reasoning, coding, and research assistance do not always travel together in the same neat package. As we move forward, the important question is not only what the model scores, but where those scores still hold up once real users start asking messy, half-formed questions.
Open Source Access and Reach (cnbc.com)
Once the training cost story starts to make sense, the next surprise is reach. Open source access is what turns DeepSeek from a clever lab result into something developers, hobbyists, and rival teams can actually pick up and use. In plain language, open source means the model’s code and key model files are available for people to inspect, modify, and build on instead of staying locked inside one company’s walls. DeepSeek said R1 was fully open-sourced under the MIT License, and its official site says users can try DeepSeek through the web, app, and API with free access.
That matters because access lowers the first barrier before any real innovation can happen. If you can download the recipe, you can test the meal, change the seasoning, or cook it in your own kitchen, which is very different from waiting on one vendor to serve it to you. DeepSeek’s official GitHub organization shows public repositories for DeepSeek-V3 and DeepSeek-R1, along with an integration repo meant to help developers plug DeepSeek into popular software. The company also publishes model files on Hugging Face, which is one of the main places people go to find and run open models.
That kind of open-source access changes how an open-source AI model spreads. Instead of growing only through ads or enterprise sales, it spreads through reuse, forks, experiments, and community fixes. DeepSeek’s own pages say its V3 series supports local running and that the team works with open-source communities and hardware vendors to make that possible, which makes the model feel more like shared infrastructure than a private product. For a newcomer, the important idea is simple: the more people can study and adapt the model, the faster its ideas travel beyond the original launch.
How did DeepSeek reach so many people so quickly? Part of the answer is that open source and consumer access arrived together. AP reported that DeepSeek’s assistant became the No. 1 downloaded free app on Apple’s iPhone store, and TechCrunch reported that the app had also passed 1.2 million downloads on Google Play and 1.9 million on the App Store worldwide soon after launch. That kind of reach matters because it moves the open-source AI model from the developer crowd into everyday hands, where curiosity grows fast and word of mouth can outrun marketing.
Open source reach also creates a feedback loop that big, closed systems often struggle to match. Once people can tinker with a model, they begin building wrappers, chat apps, coding tools, and research projects around it, and each new layer makes the model easier for the next person to try. DeepSeek’s own integration list is a good sign of that ecosystem taking shape, because it catalogs applications, agent frameworks, browser extensions, code editors, and other tools built around DeepSeek. That is why open source access is more than a philosophy here; it is a distribution engine that can turn one model into a public platform.
For readers trying to connect the dots, the takeaway is that reach does not come only from raw model quality. It also comes from how easily people can touch the model, test it, and carry it into their own projects. DeepSeek’s story shows that an open-source AI model can spread through code, community, and free access at the same time, which helps explain why the company’s influence grew so quickly. In the next step, that wider reach sets up a bigger question: what happens when a model becomes both cheap to build and easy for everyone to adopt?



