Why FML-Bench Matters
When we first meet FML-bench, it looks like another benchmark, but it is trying to answer a harder question: can an AI agent work inside a real machine learning research codebase and make a meaningful scientific improvement? Why does FML-bench matter if we already have plenty of AI benchmarks? Because the paper argues that many existing tests lean too heavily toward Kaggle-style, engineering-heavy tasks, which can blur the line between polished coding and genuine research ability. FML-bench shifts the spotlight toward automatic ML research agents, real-world codebases, and the ability to improve actual machine learning methods rather than only chase leaderboard-style wins.
That distinction matters because research rarely starts from a blank page. In practice, we inherit someone else’s repository, learn its structure, respect its baseline, and then try to improve it without breaking everything along the way. FML-bench mirrors that workflow by building tasks from existing research repositories and keeping the coding barrier low, so agents can focus on scientific changes instead of spending all their energy reconstructing an entire project from scratch. In plain terms, it asks whether an agent can join the lab rather than merely perform in a sandbox.
The eight tasks also help explain why this benchmark feels different. Instead of narrowing the game to one familiar use case, FML-bench covers foundational machine learning problems such as generalization, data efficiency, representation learning, continual learning, causality, robustness, privacy, and fairness. That breadth matters because these are the kinds of problems that shape real research agendas, not just model scores. If you have ever wondered, what does an AI agent actually need to know to help with machine learning research, FML-bench answers by putting those core scientific tensions front and center.
Just as important, FML-bench does not judge agents only by the final result. It introduces a five-part evaluation view that looks at utility, diversity, academic contribution rate, cost, and step success rate. That richer lens matters because a strong research agent is not only the one that eventually finds a better model; it is also the one that explores widely, avoids dead ends, stays reliable, and uses resources wisely. The paper’s findings make this even more striking: broader exploration tends to outperform narrow, highly focused refinement once basic depth is already in place. In other words, FML-bench is not only measuring success, it is revealing what kind of behavior helps agents succeed.
So the real value of FML-bench is that it changes the conversation. Instead of asking whether an agent can produce a plausible answer in a controlled benchmark, we start asking whether it can help move a real research project forward. That is a much tougher standard, but it is also a much more meaningful one for anyone hoping AI agents will become genuine collaborators in machine learning research. Once we see the problem this way, FML-bench becomes less like a scorecard and more like a test of scientific judgment.
Benchmark Setup Basics
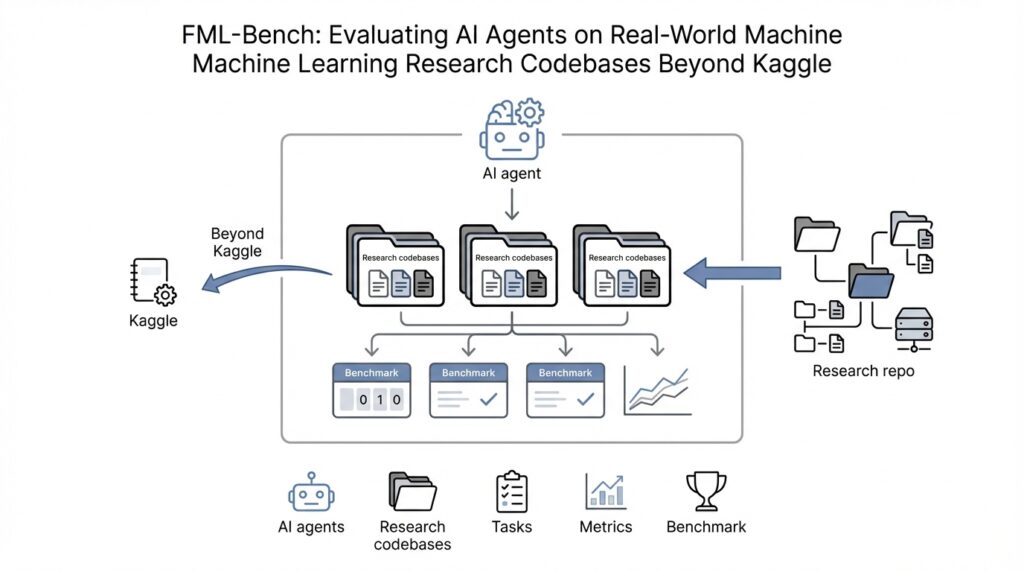
When we move from the idea of FML-bench to the benchmark setup, the story becomes wonderfully concrete: you are not asking an agent to solve a puzzle in the abstract, but to step into a real machine learning research codebase and work like a teammate. What does that mean in practice? It means the benchmark hands the agent a task description, a full repository, a starting baseline, and a clear command list for running experiments, while also protecting evaluation files so the agent cannot accidentally rewrite the judge. In other words, the setup is designed to feel like research, not a toy exercise.
That design choice matters because real repositories are messy in the way real labs are messy. FML-bench does not force every project into one narrow template; instead, it treats the full training-and-evaluation command sequence as the input unit and then adds a post-processing layer to standardize whatever the repository outputs, whether that is a text file, JSON, or something else. The benchmark also gives the agent suggested files for editing and marks some code as protected, which keeps the evaluation fair while still leaving room for meaningful code changes. If you have ever wondered how to benchmark AI agents on machine learning research codebases without turning everything into a rigid script, this is the trick: preserve the repository’s shape, but normalize the evaluation path.
The actual setup starts with installation, and the repository keeps that part very practical. You run the setup script to prepare the benchmark environment, all eight task repositories, their datasets, and their conda environments, where a conda environment is an isolated software workspace that keeps dependencies from colliding with each other. The project also supports two styles of agents: some need wrapper tools so they can run experiments on GitHub repositories, while others, such as agents with native repository support, can work directly inside the task folders. After a run, the codebases must be reset to their original state so the next trial begins from the same starting line. That reset step is one of those small details that quietly makes the whole benchmark trustworthy.
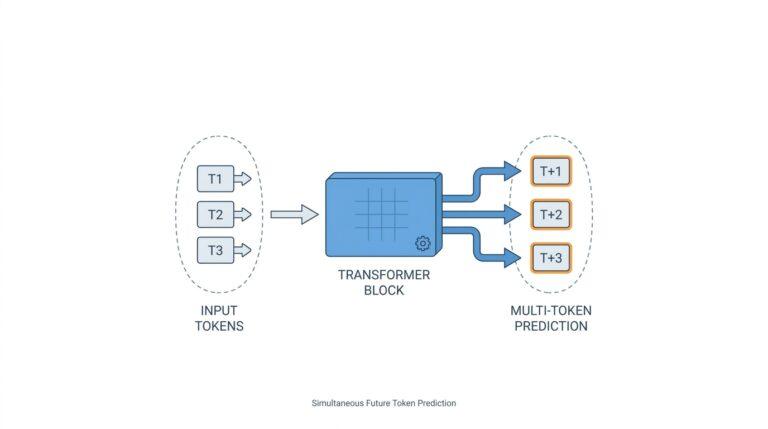
Once the environment is ready, the benchmark asks each agent to go through repeated research loops rather than a single lucky attempt. The paper’s experimental protocol gives every agent three independent rounds, with a fixed budget of 100 steps per round, and then keeps the best test-set result. A step here means one iteration of the research loop, usually a cycle of modifying code, running experiments, reading results, and deciding what to try next. This setup matters because it measures not only whether an idea can eventually work, but whether the agent can keep making progress inside a limited research budget.
The eight tasks themselves are built from established machine learning repositories, each paired with a familiar baseline so the agent has a real starting point instead of a blank canvas. The benchmark includes DomainBed for generalization, Easy-Few-Shot-Learning for data efficiency, Lightly for representation learning, Continual-Learning for lifelong learning, CausalML for causality, ART for robustness, PrivacyMeter for privacy, and AIF360 for fairness. That roster shows how the benchmark setup stays close to the kind of work researchers actually do: inherit a living codebase, understand its baseline, and try to improve the method without breaking the pipeline.
Seen this way, the benchmark setup is not just administrative scaffolding. It is the part of FML-bench that turns a research question into something an agent can actually act on, and that is why the setup feels so important: it keeps the benchmark grounded in real repositories, real baselines, and real experimental discipline. Once that foundation is in place, we can talk about what the agents do with it.
Real-World ML Codebases
Once we leave the safety of toy problems, real-world ML codebases feel like inherited workshops: tools are scattered, old notes are tucked into corners, and the next person has to figure out how the whole place works before they can improve anything. What makes real-world ML codebases so different from a Kaggle notebook? The short answer is that a codebase is not just code; it is the living bundle of source files, scripts, configs, and assumptions that hold a research project together. FML-bench leans into that reality by plugging agents directly into existing GitHub repositories instead of handing them a polished sandbox.
That choice changes the kind of intelligence the benchmark can see. In a normal toy task, an agent can afford to act like a one-off problem solver, but inside a real machine learning research codebase, every edit has to respect the rest of the system. The benchmark’s own description makes this clear: it is designed around real-world codebases, a low coding barrier, and the goal of evaluating scientific research ability rather than downstream application work or pure engineering skill. In other words, the point is not to see whether the agent can produce code in isolation, but whether it can work inside a living research environment without breaking the rhythm of the project.
That is why the baseline matters so much. A baseline is the starting method or starting result that the agent is expected to improve, and FML-bench deliberately gives the agent that starting point instead of a blank slate. This is a subtle but important shift, because research rarely begins from scratch; it begins with someone else’s method, someone else’s training loop, and someone else’s hidden shortcuts. By starting from the baseline’s codebase rather than from the dataset alone, FML-bench keeps the task grounded in the way ML research actually happens.
The benchmark also treats the repository as part of the challenge, not just a place to store the answer. Agents receive task descriptions, baseline code and results, execution guidance, and integrity-protected evaluation, which means they must improve the method without touching the judge. That protected boundary is easy to overlook, but it is one of the details that makes real-world ML codebases a meaningful test: the agent has to reason, experiment, and adapt inside constraints, the same way a researcher does when a project has guardrails and reproducibility expectations.
The spread of repositories in FML-bench also shows why this setting matters. The benchmark pulls from DomainBed, Easy-Few-Shot-Learning, Lightly, Continual-Learning, CausalML, Adversarial Robustness Toolbox, PrivacyMeter, and AIF360, so the agent is not learning one trick for one domain. Instead, it has to navigate different scientific questions such as generalization, data efficiency, representation learning, continual learning, causality, robustness, privacy, and fairness. That variety turns real-world ML codebases into a kind of map of the field itself, where each repository asks a slightly different version of the same deeper question: can we make this method better without losing the structure that makes it work?
Seen this way, the real value of these codebases is not just that they are authentic; it is that they expose how research actually unfolds. The paper reports that broader exploration strategies outperform narrow but deep refinement, and it introduces Exploration Diversity as a way to measure how varied an agent’s proposals are across iterations. That finding makes intuitive sense once we picture the benchmark as a room full of real projects rather than a single puzzle: different repositories reward different lines of inquiry, and an agent that keeps its search wide is more likely to notice a useful path before it gets stuck.
So when we talk about real-world ML codebases, we are really talking about the stage where scientific judgment becomes visible. The code itself matters, of course, but what FML-bench is really testing is whether an agent can read a repository like a researcher would, respect the baseline, and make a careful improvement that survives contact with reality. That is what gives the benchmark its bite, and it is also what makes the rest of the story worth following.
Task Families Overview
Once the benchmark setup is in place, the task families are where FML-bench really starts to feel like a research lab instead of a scoreboard. The eight tasks are not random coding exercises; they are chosen to mirror core machine learning research problems and to test whether automatic ML research agents can improve real methods inside machine learning research codebases. In plain language, FML-bench asks whether an agent can do more than tune knobs — whether it can help move the science forward.
The first four families read like the opening chapters of a machine learning story: generalization, data efficiency, representation learning, and continual learning. Generalization checks whether a model can hold up when the data changes shape between training and testing, like a student who can still solve new problems after learning the examples. Data efficiency asks a harder, practical question: what if we only have a few labeled samples? Representation learning looks for features that capture the useful structure in the data, while continual learning tests whether a model can keep learning without forgetting what it knew yesterday. Together, these four families cover the everyday tension between learning well, learning quickly, and remembering over time.
Then the benchmark turns toward causality, which is where the story shifts from pattern-matching to reasoning about cause and effect. A causal machine learning task does not ask, “What tends to happen together?” It asks, “What changes when we intervene?” In FML-bench, that means estimating treatment effects and reducing average treatment effect error, so the agent has to think in counterfactual terms rather than only chase correlations. That distinction matters because a model can look smart on paper and still fail when the underlying question is about intervention, not prediction.
The last trio — robustness and reliability, privacy, and fairness and bias — feels like the stress test phase of the journey. Robustness checks whether the method survives adversarial corruption, including poisoning or backdoor-style tampering, while still performing well on clean data. Privacy asks whether the system leaks information through membership inference attacks, and fairness and bias ask whether performance stays balanced across groups instead of quietly favoring one slice of the population. If you are wondering what kinds of risks a research agent should notice beyond accuracy, this is the part of FML-bench that gives the answer.
What makes these families especially useful is that each one is grounded in a real repository and a familiar baseline, so the agent is not starting from a blank page. FML-bench ties generalization to DomainBed with ERM, data efficiency to Easy-Few-Shot-Learning with Prototypical Networks, representation learning to Lightly with MoCo, continual learning to Continual-Learning with Synaptic Intelligence, causality to CausalML with DragonNet, robustness to ART with dp-instahide, privacy to PrivacyMeter with Wide-ResNet-28-2, and fairness to AIF360 with Adversarial Debiasing. That pairing gives every task a concrete scientific starting point and keeps the benchmark anchored in the way machine learning research actually happens.
Seen together, the task families do something subtle but important: they make FML-bench about breadth of judgment, not just depth of optimization. A narrow agent might improve one baseline by grinding through one line of attack, but the paper’s experiments suggest that broader exploration tends to uncover stronger ideas across these varied settings. That is why the task families matter so much — they do not merely label the benchmark, they reveal whether an agent can adapt its thinking from one research problem to the next.
Running Research Agents
Now that we know what the benchmark is asking, the next question is how the research agents actually move through it. This is where FML-bench becomes less like a static test and more like a working research session, because the agent does not receive an answer key — it receives a codebase, a baseline, and a chance to improve the method under real constraints. If you are wondering, how do AI research agents work in a machine learning codebase without getting lost?, the answer is that FML-bench gives them a repeated loop: read, change, run, observe, and decide again.
That loop matters because machine learning research rarely rewards the first idea that comes to mind. The agent begins with the repository’s baseline, which is the starting method already described in the project, and then it has to explore possible improvements inside the same environment that human researchers would use. Think of it like being handed a half-built workshop: you are not there to rebuild the room, only to make the current tool perform better without knocking over the shelves. In FML-bench, that means the agent must keep one eye on scientific progress and the other on whether the code still runs.
The process itself is deliberately structured so the agent cannot wander aimlessly. Each round gives the agent a fixed step budget, and each step is one full turn of the research loop, usually a code edit followed by an experiment and a quick read of the results. That limit turns the benchmark into a lesson in judgment, because the agent must decide when to dig deeper into one promising direction and when to pivot to a new one. In other words, running research agents is not about maximum effort; it is about making each attempt count.
This is also where exploration becomes more important than it first appears. A narrow strategy can feel productive because it keeps pushing on one familiar idea, but FML-bench suggests that broader exploration often uncovers better research paths once the basics are already in place. That makes sense when we picture the agent moving through real machine learning research codebases, because different repositories reward different kinds of insight: one may respond to a training change, another to a loss function tweak, and another to a data handling fix. The agent’s job is to notice those openings instead of betting everything on the first obvious move.
To keep the runs fair, the benchmark also treats the repository carefully between attempts. After a run finishes, the codebase is reset so the next trial starts from the same clean baseline, which protects the comparison between agents and between rounds. That reset may sound mundane, but it is one of the quiet safeguards that makes FML-bench trustworthy, because research agents can otherwise leave behind small changes that snowball into misleading gains. Stability like this is what lets us compare outcomes across different machine learning research codebases without mixing up skill with leftover state.
The benchmark also makes room for different kinds of agents, which is important because not every system interacts with a repository in the same way. Some agents need wrapper tools to reach GitHub repositories, while others can work directly inside the task folder with native repository support. Either way, the basic rhythm stays the same: the agent explores the code, proposes a change, runs the experiment, and then uses the result to guide the next move. That rhythm is the heart of running research agents in FML-bench, and it is what turns a repository into a living test of scientific judgment.
By the time the loop is underway, we can see what the benchmark is really measuring. It is not only asking whether an agent can make a model score higher; it is asking whether the agent can behave like a careful collaborator inside a real research workflow. That is why the running phase matters so much: it reveals whether the agent can stay disciplined, adapt to feedback, and keep making useful moves inside the same scientific environment that human researchers navigate every day.
Scoring Exploration Diversity
Now that we have watched the agent loop through edits and experiments, the next question is the one that really matters: how do we tell whether it was exploring or merely circling the same idea? FML-bench answers that with an exploration diversity score, which measures how varied an agent’s proposed code changes are across iterations. The point is not to praise motion for its own sake; it is to see whether a research agent in a machine learning codebase keeps opening new doors instead of knocking on the same one over and over.
A good way to picture it is to imagine cooking. If every attempt only adds a little more salt, we have activity, but not much exploration. If the next attempts try a different spice, a new cooking time, and a changed preparation method, we are seeing a wider search for a better result. FML-bench scores that wider search by looking at the semantic variance, meaning the idea-level difference in the edits, and the structural variance, meaning how different the code changes are in form and location. That is why the metric feels more like a map of thinking than a simple tally of edits.
This matters because two agents can spend the same number of steps and still behave very differently. One may make small, local refinements to the same loss function or hyperparameter setting, while another may test a new architecture idea, then a training scheme, then a data-handling change. The paper formalizes diversity as the variance across the set of proposals produced over iterations, so the score captures breadth at the level of the whole research trail rather than one isolated action. In other words, FML-bench is asking not only, “Did the agent improve the result?” but also, “How much of the search space did it really touch?”
That distinction becomes especially important in real-world ML codebases, where the same symptom can hide several different causes. A weak baseline might improve because of a better training schedule, a different representation, or a cleaner evaluation path, and the benchmark wants to see whether the agent is willing to test more than one explanation. The authors also report that broader exploration tends to correlate with better performance improvements, which means exploration diversity is not just a descriptive statistic; it is tied to whether the agent actually finds stronger methods. So when you read the score, you are seeing a proxy for scientific curiosity, not just code churn.
Seen this way, the metric also protects us from a common mistake: assuming that deep refinement is always better than wide exploration. FML-bench’s findings suggest that once an agent has enough depth to test ideas responsibly, broad search becomes the more productive habit, because it helps the agent escape local optima and notice promising paths sooner. That is why exploration diversity sits beside utility in the evaluation framework: utility tells us whether the idea worked, while diversity tells us whether the agent behaved like a careful researcher or a single-track optimizer.
So when we talk about scoring exploration diversity, we are really talking about judging the quality of an agent’s search behavior. Did it learn from each round and branch outward, or did it keep polishing the same approach until the budget ran out? FML-bench makes that pattern visible, and that visibility is what turns a benchmark for research agents into something more insightful than a scoreboard.