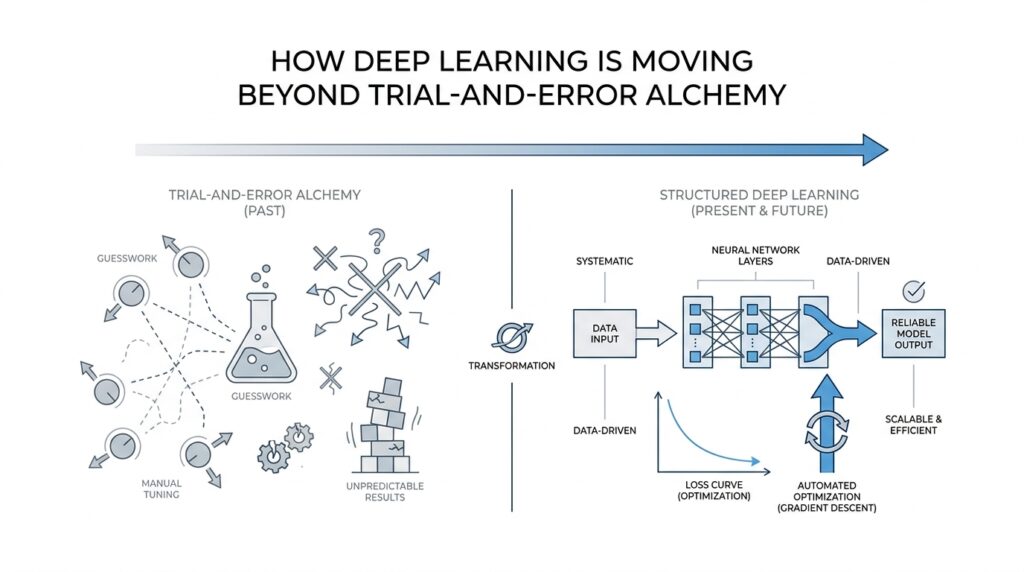
Why Deep Learning Feels Random
When people first meet deep learning, it can look like a magician’s workshop: you mix in data, adjust a few settings, wait, and hope the model starts behaving. That is why deep learning feels random at first glance. You may change one tiny detail and watch the result swing in a direction you never expected, even though you followed the same steps as last time. So if you have ever wondered, why does deep learning feel random when we are supposedly doing the same thing? you are asking the right question.
Part of the answer is that a neural network, which is a model made of layers of connected numbers that pass signals forward, has many moving parts at once. Each connection has a weight, meaning a value that controls how strongly one unit influences another. During training, the model keeps nudging those weights to lower its error, which is the gap between what it predicts and what it should predict. That sounds orderly, but when millions of weights change together, the whole system behaves a bit like a crowded room where one person’s small move can shift the balance for everyone else.
Another reason deep learning feels random is that the training process itself includes chance. The model usually starts with random initial weights, so two runs do not begin from the same place. Then there is stochastic gradient descent, a training method that updates the model using small batches of data rather than the whole dataset at once, which adds more variation from step to step. It is a little like teaching two students with the same textbook but letting each one flip through the pages in a different order; both may learn, but they will not travel the exact same path.
The settings we choose before training also make the process look unpredictable. These settings are called hyperparameters, and they include choices like learning rate, batch size, and network depth. The learning rate is how big each update step is, batch size is how many examples the model studies at once, and network depth is how many layers it has. Change any of those, and you are not merely turning a dial; you are changing the route the model takes through a very complicated landscape. That is why deep learning can seem more like steering in fog than following a straight road.
There is also a story happening inside the data itself. Deep learning models do not read the world in a neat, human way; they learn patterns from examples, and those patterns can be surprisingly sensitive to noise, missing context, or small differences in the training set. A model might learn one clue strongly because it appears often, then latch onto a different clue when the data shifts slightly. This is one reason results can vary across runs, across datasets, or even across attempts that look almost identical on paper. The system is learning, but it is learning from a messy world.
That messy learning process is what makes neural networks feel like a black box. We can often measure what goes in and what comes out, but the path between those two points is tangled enough that even experts cannot always predict it step by step. The surprise is not that deep learning is broken; the surprise is that such a flexible system can still find useful structure at all. In practice, that is where the “alchemy” feeling comes from: we keep seeing impressive results without being able to trace every cause with clean, human certainty.
Still, the randomness is not pure chaos. It is the visible sign of a search process exploring a huge space of possibilities, with some chance built in and many interacting parts pushing against one another. Once you see that, the mystery softens a little. Deep learning feels random because it is balancing noise, scale, and sensitivity all at once, and that tension is exactly what makes the next question so interesting: how do we bring more direction to a process that seems to wander?
Expose Model Decisions
When a deep learning model makes a prediction, the real shift happens when we stop treating that answer like a sealed envelope. We want to see model decisions unfold in front of us, because a useful model is easier to trust when it can show its work. That is the heart of interpretability, which means the ability to understand why a model produced a result. And if you have ever wondered, how do we expose model decisions in deep learning? the answer begins by turning the black box into something more like a window.
One of the first ways we do that is with feature attribution, a method for estimating how much each input part influenced the final prediction. Imagine a model reading a movie review and deciding whether it is positive or negative. Instead of only telling us the label, we ask which words pulled the decision in that direction, such as “wonderful” or “boring.” This does not give us the whole story of the neural network, but it gives us a trail of clues, and those clues make deep learning feel less mysterious.
A common companion to attribution is a saliency map, which is a visual overlay that highlights the most influential parts of an input. If the model is looking at an image, the map might glow around a face, a wheel, or a shadow that mattered more than the rest. If the input is text, the same idea can appear as highlighted words or phrases. The point is not that the model thinks like a human; the point is that we can see which parts of the input were loudest inside the model’s decision.
This is where the story gets interesting, because exposing model decisions is not the same as reading the model’s mind. A highlighted region can tell us what the model relied on, but not always whether it relied on the right thing. A neural network might focus on a patch of background in an image because that patch happened to correlate with the label during training. So when we ask, “Why did the model choose this answer?” we are really asking two questions at once: what influenced the output, and whether that influence makes sense to us.
Another useful idea is counterfactual explanation, which means asking what would need to change for the model to change its mind. Think of it like testing a locked door by turning different keys and seeing which one works. If a loan model rejects an application, a counterfactual explanation might say that a slightly higher income or a lower debt load would have flipped the result. This kind of explanation is powerful because it gives us a concrete path forward, not just a postmortem.
Some modern deep learning models also use attention, a mechanism that helps the model focus on certain parts of the input more than others. Attention can be helpful for understanding model decisions, because it shows where the model concentrated as it processed information. Still, attention is not a perfect explanation on its own, which is why we should treat it as a clue rather than a verdict. In practice, interpretability works best when we combine several views and compare what they reveal.
That combination matters because exposing model decisions is really about building a conversation with the model. We are no longer staring at a prediction and guessing; we are asking for a reason, checking that reason against the input, and looking for signs that the model learned the right pattern instead of a misleading shortcut. This is one of the ways deep learning moves beyond trial-and-error alchemy: it gives us tools to inspect, challenge, and refine what the network has learned. Once we can see which parts mattered, we are ready to ask a deeper question—when should we trust those explanations, and when should we keep digging?
Learn Causal Structure
The next step is to ask a harder question than, “What did the model notice?” We start asking, “What actually caused that outcome?” That shift is where causal structure enters the story, and it matters because deep learning can be very good at spotting patterns without knowing which pattern really drives the result. If we want causal relationships instead of lucky correlations, we have to teach ourselves to look for the machinery underneath the surface.
At first, this can feel like a small wording change, but it is not. A correlation means two things move together, like umbrellas and wet sidewalks; a cause means one thing helps produce the other. Deep learning often learns the first kind very well, because it is excellent at finding repeated regularities in data. The trouble is that repeated regularities are not always the same as causal structure, and that is where models can become convincing in all the wrong ways.
So how do we look for causality in deep learning? We begin with a causal graph, which is a simple map of what might influence what, drawn with arrows instead of guesses. Think of it like tracing the flow of water through pipes instead of only watching puddles form on the floor. This kind of map helps us separate a true driver from a confounder, which is a hidden factor that influences two things at once and makes them look connected when they are not. Once we start looking for these hidden links, the picture becomes much clearer, even if it also becomes more honest about uncertainty.
The next clue comes from intervention, which means deliberately changing one factor to see what happens to another. That is different from passive observation, where we only watch the world go by. If we raise a variable in a simulation, adjust a feature in a dataset, or test a model under a controlled change, we are asking a cause-and-effect question instead of a pattern-matching question. In plain terms, causal inference is the art of learning from those interventions, whether real or imagined.
This is where the earlier idea of model decisions starts to deepen. A saliency map can show us that a model paid attention to a patch of the image, but causal structure asks whether that patch truly mattered or merely happened to be nearby when the model learned its shortcut. That distinction is huge. A model might notice snow in the background and use it to classify wolves, but the snow is not the reason an animal is a wolf. Causal reasoning helps us catch those brittle shortcuts before they break in the real world.
We can also use causal thinking to make deep learning more robust. Robust means a model keeps working when conditions change a little, rather than falling apart the moment the environment shifts. When a model understands causal structure, it is less likely to cling to accidental clues from the training data. That is why causal discovery, the process of uncovering likely cause-and-effect links from data, has become such an important companion to modern machine learning.
Another way to see it is to imagine a detective story. Correlation gives us a room full of footprints, but causal structure helps us figure out who walked where, in what order, and why. We are not only asking which clues appear together; we are asking which ones would still matter if we changed the scene. That question is the heart of causal inference, and it is one of the biggest ways deep learning is moving beyond trial-and-error alchemy.
The payoff is practical. When we learn the causal structure behind a problem, we can design models that are easier to trust, easier to debug, and better at handling new situations. We also get a clearer sense of where the model is likely to fail, which is often just as valuable as a high score on a test set. And once we can ask not only what the model sees, but what actually makes the world change, we are ready for the next leap: using those causal ideas to build systems that reason, not just recognize.
Automate Model Search
After we’ve learned to read model decisions and look for causal structure, the next bottleneck becomes familiar in a different way: we still have to choose which model to build. That is where automate model search changes the story. Instead of treating architecture choice like a blindfolded guessing game, we let software explore many candidate models for us, compare them on a clear score, and keep the promising ones. If you’ve ever wondered, how do we automate model search without losing control?, the answer begins with turning that search into a guided process rather than a lucky hunch.
The first piece of that process is model search, which means exploring different model designs to find one that works well for a task. Think of it like trying on coats before winter arrives: you do not assume the first one fits, and you do not want to inspect every possible fabric in the store by hand. In deep learning, those “coats” might differ in the number of layers, the number of neurons in each layer, or the way information moves through the network. When we automate model search, we ask a system to try those options for us under a fixed budget of time or compute.
That search usually includes hyperparameter optimization, which means tuning settings the model does not learn directly from data. A hyperparameter is a choice we make before training, such as learning rate, batch size, or dropout rate, and each one can change training behavior in a big way. The automated search engine tests combinations of these settings, watches how the model performs on a validation set—a separate slice of data used to judge progress—and learns which directions are worth more attention. In plain language, it is less like rolling dice and more like sending out scouts.
Different search methods do this scouting in different ways. Grid search tries every combination in a neat checklist, which sounds organized but can become expensive fast. Random search samples combinations at random, which often works better than it sounds because not every setting matters equally. More advanced methods, such as Bayesian optimization—a technique that uses past results to guess which trial should come next—try to be smarter about where they spend effort. The common thread is that model search becomes a managed expedition instead of a series of isolated guesses.
Once the search starts, the real skill is deciding what the machine should explore. We define a search space, which is the range of model designs and settings the system is allowed to test. If the space is too small, automation cannot discover much; if it is too broad, it can waste time wandering through weak ideas. This is why automated model search works best when human judgment shapes the boundaries first. We still need to decide what “good” means, what constraints matter, and how much compute we can afford to spend.
That last point matters more than it first appears, because automated search can become another kind of trial and error if we are careless. A system may find a model that scores well on the validation set but only because it adapted too closely to that one benchmark. That problem is called overfitting, which means learning patterns that look strong in testing but fail in the real world. So when we automate model search, we are not handing over our thinking; we are asking the machine to do the repetitive testing while we keep an eye on whether the results still make sense.
The best part of this shift is that it changes our role. We stop acting like artisans who must shape every detail by hand, and we start acting like designers of a search process: we pick the goal, set the rules, and let the system explore the possibilities. That is why automated model search is such an important step beyond trial-and-error alchemy. It does not remove uncertainty, but it turns uncertainty into something we can navigate more deliberately, and that opens the door to a deeper question about what to trust when the search itself has done its job.
Close the Experimentation Loop
Once we can see what a model pays attention to, and once we start asking whether those signals are causal or merely convenient, the next step is to bring the whole process back around. That is what it means to close the experimentation loop: we use what we learned from one run to shape the next run, instead of treating each training attempt like a fresh roll of the dice. In deep learning, this matters because progress usually comes from many small corrections, not one lucky breakthrough. The goal is to turn model building into a conversation: observe, revise, test, and learn again.
That sounds abstract until we picture the everyday version of it. If you bake bread and the crust comes out too dark, you do not start over with a completely unrelated recipe; you change the oven time, the temperature, or the rack position, then watch what happens next. Deep learning works the same way when we treat model decisions as clues rather than final answers. We look at a failure, form a hypothesis, and run a new experiment to see whether the change helped. The experimentation loop gives that process a structure, so we are not chasing noise with more noise.
The loop usually begins with a clear question. Maybe the model performs well overall but keeps failing on one slice of data, such as low-light images or short customer reviews. That is where evaluation becomes more than a single score, because a single score can hide the very pattern we need to fix. We break the results into smaller views, compare the good cases with the bad ones, and ask what changed between them. If you are wondering, “How do we know which change actually helped?” this is the moment where careful comparison matters most.
From there, we turn insight into a testable adjustment. If interpretability shows that the model leaned on a misleading shortcut, we can modify the data, add augmentation, or remove that shortcut from training examples. If causal structure suggests that a variable should matter but does not, we may need a better feature, a different label definition, or a more realistic intervention. This is where model decisions stop being a puzzle on the screen and become instructions for the next experiment. We are no longer guessing blindly; we are using evidence to guide the next move.
Good experimentation also depends on discipline, because it is easy to change too many things at once. When we alter the architecture, the data, and the training settings all together, the result may improve, but we lose the trail that tells us why. Closing the experimentation loop works best when we change one meaningful piece at a time and record the outcome carefully. That record might be a notebook, a dashboard, or a simple log of what we tried and what happened. In practice, that trail is the memory of the entire deep learning project.
The same logic helps when automated model search is part of the story. Search tools can explore many candidates, but we still need to read the results like investigators, not spectators. A model that wins on one benchmark may be pointing us toward a real improvement, or it may have overfit a narrow test set and learned a brittle trick. By feeding those results back into the next round of experimentation, we keep the search grounded in reality. The loop closes only when the machine’s suggestion becomes a human question, and then a better-designed test.
That is the quiet power of this approach. Instead of treating deep learning as a mysterious machine that occasionally produces magic, we build a rhythm of measurement and response. Each experiment teaches us something about the model, the data, or the problem itself, and each lesson shapes the next attempt. Over time, the process becomes less like trial-and-error alchemy and more like skilled craftsmanship, where every pass leaves us a little closer to a model we can trust and understand.
Validate Under Real-World Shifts
After we close the experimentation loop, the story does not end with a good validation score on familiar data. Real life has a habit of changing the rules while the model is still trying to play the game. A deep learning system that looks strong in the lab can stumble when the lighting changes, the users change, or the language on the screen shifts just a little. That is why validation under real-world shifts matters: it asks whether the model still holds together when the world stops looking like yesterday’s training set.
This is where the idea of distribution shift enters, which means the data a model sees later no longer matches the data it learned from earlier. Think of it like learning to drive on a sunny afternoon and then being handed the same route in heavy rain. The road is still there, but the conditions have changed enough to expose weak habits. In deep learning, those changes can come from new cameras, new customer behavior, seasonal trends, or even a different writing style. If you have ever asked, “Why does my model fail after deployment?” distribution shift is usually part of the answer.
So we stop asking only, “Did it score well once?” and start asking, “Did it score well across the situations that matter?” That is where robustness, meaning the ability to keep working when conditions change, becomes the real test. We can check robustness with carefully chosen slices of data, which are smaller groups split by condition, such as age group, device type, region, or time period. These slices act like windows into the model’s behavior, and they often reveal trouble hiding inside an otherwise healthy average.
A good validation plan also needs a stress test, which is a deliberate challenge that pushes the model into uncomfortable territory. Imagine checking a bridge not only with normal traffic, but with wind, weight, and weather added on purpose. For deep learning, that might mean testing blurry images, slang-heavy text, missing fields, or noisy sensor readings. These tests do not punish the model for being realistic; they help us learn whether it relies on sturdy patterns or on fragile clues that disappear the moment life gets messy.
Temporal shifts deserve their own attention too, because the future often looks different from the past. A model trained on last year’s data may face new products, new customer habits, or changing language this year, and a random train-test split can hide that problem by mixing the past and future together. To validate under real-world shifts, we often use time-based splits, which means training on earlier data and testing on later data. That approach feels less flattering, but it gives a truer picture of how deep learning will behave after launch.
Another helpful habit is watching not only whether the model is correct, but how confident it sounds when it is wrong. A model can be inaccurate and still seem sure of itself, which is risky in the real world. That is why calibration, meaning how closely predicted confidence matches actual correctness, matters during validation. If a system says it is 95 percent sure but is right far less often than that, we have not built trust—we have built a polished illusion. Real-world validation helps expose that gap before users do.
The important shift here is mental as much as technical. We are no longer treating validation as a finish line; we are treating it as a rehearsal for deployment. That changes how we judge deep learning models, because we begin to prefer models that stay steady under change over models that only shine under ideal conditions. In other words, validating under real-world shifts turns deep learning from a clever prediction machine into something closer to a dependable tool, and that is the standard that matters when the model leaves the notebook and meets the world.



