Understanding Dialect Variation
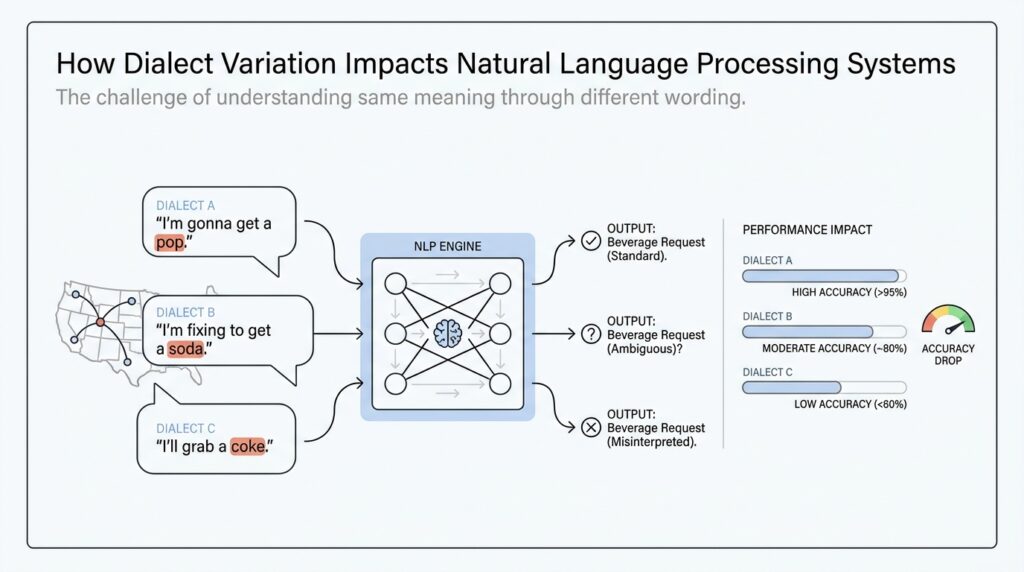
When natural language processing systems meet dialect variation, the first thing we usually notice is confusion. A sentence can look perfectly normal to the people who use it, yet a model may treat it like an error because it was trained mostly on standard-language examples. That is why dialect variation matters so much: it is not random noise, but a structured part of how people speak and write in real communities. Recent NLP research also makes this clear by treating dialects and language varieties as real evaluation targets, not edge cases to ignore.
A helpful way to picture a dialect is as a familiar route through language with its own steady landmarks. A dialect is not a pile of mistakes; it is a pattern of choices in grammar, vocabulary, and spelling that tends to repeat within a community. Researchers studying dialects note that the differences show up in the presence, absence, and frequency of many small features, rather than in one big switch that turns a dialect on or off. That is why a phrase like “He running” can be meaningful in one variety even though a model trained on standard English may stumble over it.
This is where the idea of a language feature becomes useful. A feature is one small, recognizable pattern, like a dropped word, a different verb form, or a preferred expression, and linguists often study dialects by comparing minimal pairs, which are near-identical examples that differ in just one feature. Thinking this way helps us see dialect variation as a collection of tiny signals rather than a vague impression. For NLP systems, that matters because a model learns from patterns in data; if the training data barely contains a feature, the model may never learn to recognize it confidently.
What happens when those features appear in real-world text? In practice, the model’s first job may be language identification, which means deciding what language or variety it is looking at. That sounds straightforward until you add local dialects and code-switching, which is when speakers move between varieties in the same conversation or even the same sentence. Research on language identification found that many systems systematically miss minority dialect speakers and multilingual speakers, which means the pipeline can go wrong before the main NLP task even begins. Once that first step slips, every later step has a harder job.
We can see the consequences most clearly in dialects that have been studied extensively, such as African American English. One study found that part-of-speech taggers trained on Mainstream American English produced non-interpretable results when applied to African American English because the systems had not seen those features during training. More recent work on language generation found performance gaps across tasks when models were asked to handle African American Language versus White Mainstream English, showing that the problem is not limited to one narrow NLP task. In other words, dialect variation can affect recognition, tagging, generation, and even the way a system judges what counts as normal language.
So when we talk about dialect variation, we are really talking about the gap between how language lives in the world and how a model has learned to expect it. Standard-only benchmarks can miss that gap entirely, which is why newer resources such as DIALECTBENCH focus on many varieties and report clear performance differences between standard and non-standard language. That gives us a practical lesson to carry forward: if we want NLP systems that work for more people, we have to understand dialect variation as part of the language itself, not as a side note to be cleaned up later.
Data Gaps and Representation
Now that we have seen how dialect variation can confuse a model, the next question is where that confusion starts. In many natural language processing systems, the answer is training data: if most of the examples come from one standard variety, the model learns that variety as the center of the language world and leaves other communities at the edges. What does representation really mean here? It means whose language shows up, how often it shows up, and whether the data reflects real use or only a polished slice of it. Work on data statements argues that documenting data sources and populations helps expose exactly these blind spots, and more recent dialect research shows that under-represented dialects often need targeted augmentation because standard-only data leaves them behind.
This is why data gaps are more than a simple headcount problem. A dialect may be missing not because people do not use it, but because it is harder to collect, harder to write down consistently, or less likely to appear in the places researchers scrape for text. When that happens, the dataset can look large while still being narrow, like a library with many books that all tell the same story. Beginners often ask, “If the model has seen millions of sentences, why does it still fail on dialects?” The missing piece is representation: the training data may be plentiful, but it may not contain the communities, contexts, or forms that the model needs to recognize.
We can see the problem more clearly when we look at the tiny details that make a dialect feel like itself. Researchers describe dialects as patterns of features, such as a dropped copula or a particular verb form, rather than as one giant switch that flips a sentence from “standard” to “nonstandard.” That matters because a model cannot learn a feature it barely sees, and large annotated corpora for many dialects do not exist. Demszky and colleagues showed that a small set of minimal pairs, meaning near-identical examples that differ in one feature, can teach a model surprisingly well; in other words, representation is not only about volume, but also about contrast.
Once we widen the lens, the same pattern appears across tasks and languages. A 2023 study of large language models found a measurable dialect gap in machine translation and automatic speech recognition, and it reported that training data size and dataset construction mattered, though not in the same way for every model or language. That is an important lesson for us: more data can help, but more data alone does not guarantee fair coverage. If the collection process favors one prestige variety, the system may still look confident while quietly misreading everyone else.
This is why inclusive benchmarks matter so much. DIALECTBENCH was built to compare performance across standard and non-standard varieties and to make those disparities visible instead of hiding them inside one averaged score. It also points to a practical next step: better, higher-quality comparable data, along with broader task coverage, including speech-based systems. So when we think about data gaps and representation, we are really asking who the model has met, who it has overlooked, and which parts of language are still blank spaces on its map. That question will guide the next step as we think about how to close the gap.
Tokenization and Normalization Issues
If you have ever watched a model stumble over a sentence that looks perfectly normal to you, you have already met the heart of tokenization and normalization issues. Tokenization means splitting text into the smaller pieces a model reads, such as words or subword units, and normalization means rewriting text toward a more standard form so other tools can process it more easily. The trouble is that dialect writing often refuses to sit neatly inside those standard shapes, so the first split the system makes can already tilt everything that follows. Research on language variation shows that tokenizers can behave differently on less common forms, and that the best tokenizer settings can change depending on whether a task should ignore variation or pay close attention to it.
That is why a dialectal sentence can feel like a small puzzle box to an NLP system. A spelling like one used in a regional variety may break into more pieces than its standard-language counterpart, which changes how the model stores and compares it. In a recent study, the pre-tokenizer had the biggest overall impact on performance, and the strongest settings were not the same for tasks that needed robustness versus tasks that needed sensitivity to variation. In plain language, the way we chop language up is not a neutral step; it shapes what the model notices first and what it quietly smooths over.
Normalization brings us to the next part of the story. When we normalize dialectal text, we are trying to translate it into a form that standard-language tools can read, almost like turning handwritten notes into a typed page. That can be genuinely useful, because one Finnish study described dialect normalization as a necessary step for improving tools built for normative Finnish, and a broader multilingual study introduced dialect-to-standard normalization as a sentence-level task for mapping dialect transcriptions to standard orthography. In other words, normalization can open the door to existing NLP pipelines instead of forcing every new dialect to start from zero.
But normalization has a shadow side, and this is where the story gets tricky. When we smooth dialect text into standard form, we may also erase the very surface clues that carried meaning in the first place. A 2025 study on Greek dialect normalization found that earlier downstream results depended heavily on superficial linguistic information, including orthographic artifacts, while the remaining semantics still supported new observations. That is a careful reminder that normalization is not free cleanup; it is a transformation that can remove style, identity markers, and local spelling patterns even when it helps the model read the text more reliably.
So the practical question is not whether we should always normalize or never tokenize in a certain way. The better question is: what should the model preserve, and what should it abstract away? For dialect-aware NLP, we often need both. A small set of contrastive examples can teach a model to recognize dialect features, and subword granularity can matter a great deal for dialect classification, which means we can design tokenization more deliberately instead of treating it as a fixed preprocessing habit. When we do that, tokenization and normalization stop acting like blunt filters and start becoming careful tools that help the system respect variation instead of flattening it.
Model Errors and Bias
Once we move past tokenization and normalization, the question becomes sharper: what happens when natural language processing systems keep making the same mistake in the same communities? That is where model errors and bias start to separate from ordinary confusion. An ordinary error is a one-off miss, like misreading a sentence once; bias is a pattern, like a compass that leans a few degrees off north every time. In dialect-aware settings, that small lean can turn into a steady drift away from how real people actually speak.
The easiest place to see this is in classification tasks, where a system has to decide whether a text is toxic, positive, urgent, or safe. A false positive means the model predicts something is there when it is not, while a false negative means it misses something that really is there. In dialect variation, both can hurt. A dialect feature, a local expression, or a grammar pattern can make a harmless message look suspicious, or it can hide real intent because the model is too busy reacting to unfamiliar wording. So when someone asks, “Why does my model flag this dialect as negative or aggressive?” the answer is often that the model has learned language cues and social assumptions at the same time.
That is where bias becomes more than a technical flaw. Model bias means the system consistently favors one kind of language over another, even when the content is equally clear. If annotators label dialect speech as “ungrammatical,” “unclear,” or “hostile” more often than standard speech, those labels become part of the training signal. The model does not know it is inheriting a social judgment; it only sees patterns and tries to repeat them. Over time, natural language processing systems can end up treating standard forms as the default and dialect forms as deviations, which makes the bias feel normal even when it is unfair.
This matters because errors rarely stay in one place. A wrong classification can trigger a wrong moderation decision, a bad translation can distort meaning, and a poor summary can flatten a speaker’s tone or identity. In a pipeline, which is a sequence of steps where one output becomes the next input, a small early mistake can snowball into a much larger failure. We saw earlier that language identification and tokenization can wobble on dialects; now we can see the consequence more clearly: once the first step tilts, every later step has less stable ground to stand on.
The hardest part is that model errors and bias often hide inside average numbers. A system can look strong on a broad benchmark while still failing one dialect community far more often than another. That happens because an aggregate score, which is one score over the whole dataset, can blur together many different experiences. If one group gets excellent results and another group gets repeated misses, the final average may still look respectable. So the model appears balanced on paper, while real users keep running into the same frustrating pattern.
Bias also grows when the model learns from majority behavior as if it were the whole world. Training procedures usually reward the model for getting the most common cases right, which sounds reasonable until we remember that “most common” is not the same as “most fair.” The system may become very confident on standard-language examples and still stumble whenever dialect variation appears, not because the dialect is flawed, but because the model has made one variety feel like the center of language. That is why model errors and bias are connected: the error is what we see in a single output, and the bias is the repeated shape behind it.
Once we recognize that pattern, we can start asking better questions about the system’s behavior. Which dialects does it misread most often? Which labels seem to shift when the wording changes? Which errors come from the language itself, and which come from the model’s assumptions about what language should look like? Those questions do not solve the problem by themselves, but they give us the map we need before we try to fix it.
Evaluation Across Dialects
When we reach dialect evaluation, the story changes from how a model is built to how we find out whether it really works. A system can look strong on an overall score and still stumble badly on one community’s speech, so we need to test it the way a listener would hear it in the real world. That means looking beyond one blended number and asking a more careful question: how does the model behave when the language shifts? In natural language processing systems, that question matters because dialects do not appear as rare curiosities; they appear as ordinary language in ordinary use.
The first move is to stop treating the test set as one flat crowd. A test set is the collection of examples we use after training to see how a model performs, and a slice is one smaller part of that set, such as examples from one dialect or language variety. Once we split evaluation this way, we can compare performance across dialects instead of guessing from the average. That comparison often reveals a pattern that a single benchmark score hides: the model may sound fluent on standard forms while weakening as soon as local grammar, spelling, or vocabulary enters the picture.
This is why dialect-aware NLP needs more than accuracy alone. Accuracy tells us how often the model is right, but it does not tell us whether it is right for everyone in the same way. For tasks like sentiment analysis, language identification, or text classification, we also want to know whether the system makes more false alarms for one dialect and more missed detections for another. If you have ever wondered, “Why does my model work on one variety of English but fail on another?” the answer is often sitting in those slice-level results.
A careful evaluation across dialects also needs the right kind of comparison. We do not want to compare wildly different texts and pretend the difference is about dialect alone. We want matched examples when possible, meaning examples that are similar in content but different in dialectal form, so we can see what the model is reacting to. This is where the earlier idea of minimal pairs becomes useful again. When we hold the meaning steady and change only the dialect feature, we can watch whether the model stays calm or starts to drift.
But numbers alone still leave some important details in shadow. A model might score reasonably well while consistently misunderstanding a specific construction, and that kind of mistake can matter more than the average suggests. So evaluation across dialects often includes error analysis, which means reading the failures carefully and looking for patterns instead of treating them as random noise. We ask whether the system is confused by morphology, syntax, spelling, or vocabulary, and we ask whether those errors cluster in one variety. That is how evaluation becomes a diagnostic tool rather than a scoreboard.
Human judgment also has a place here, especially when the task involves generation or interpretation. A human evaluation is a review done by people rather than by automatic metrics, and it helps us notice things that a numerical score misses, such as tone, fluency, and whether a response respects the dialect instead of flattening it. Automatic metrics can tell us whether outputs match a reference, but they often miss the lived feel of language use. In dialect evaluation, that matters because a model can be technically close and socially wrong at the same time.
The strongest evaluations combine both views. We start with dialect-specific slices, then we inspect errors, then we bring in human review when meaning or style could be distorted. In that process, evaluation across dialects becomes less like a final exam and more like a map check on a long journey: it shows us where the model is steady, where it swerves, and where it has not learned the terrain yet. When we do this well, we make natural language processing systems more trustworthy, not only in the abstract, but for the people whose language they are meant to understand.
Mitigation Strategies for Fairness
Once we have seen where dialect gaps appear, the next question is what we can do about them. How do we make NLP systems fairer for dialect speakers? The research community usually answers that question in layers: pre-processing, in-training, intra-processing, and post-processing each give us a different place to intervene, instead of waiting until the model has already learned the wrong habits.
A good first step is to look at the data with honest eyes. Data statements are a simple but powerful practice for describing what a dataset contains, who it represents, and where its blind spots may be, so developers can judge generalization and deployment more responsibly. For fairness work, that matters because we cannot repair a gap we have not named yet. When the training set quietly centers one standard variety, the model learns that variety as the norm, and the rest of the language community becomes harder to see.
From there, we can widen the picture with targeted augmentation. One recent framework uses a dialect identification model to find under-represented dialectal examples and then adds more training data for those cohorts, which is a practical way to reduce imbalance without rebuilding the whole system from scratch. A related fairness trick is to use counterfactual or matched examples, where we hold the meaning steady and vary the dialectal form, so the model learns that the wording changed but the underlying task did not. That kind of contrast helps expose which patterns the system is overreacting to.
We can also teach the model to recognize dialect without treating it as an error signal. In one ACL study, researchers used multitask learning, which means training the model on two tasks at once, with dialect modeling as an auxiliary task to capture syntactic and lexical variation. Their experiments on African American English found that this approach improved fairness when compared with common learning baselines. In plain language, we are giving the model a second set of glasses: one lens for the main task, and one lens for dialect-aware understanding.
Normalization can help too, but it needs a light touch. Dialect-to-standard normalization maps dialectal transcriptions into the orthography of a standard variety, which can open the door to downstream tools that were built for normative text. That is useful when a system cannot process the original form well, yet it should feel like a bridge rather than a replacement, because the dialect itself still carries meaning, identity, and local structure. So when we normalize, we should ask not only whether the model reads better, but also what it loses in the process.
The safest fairness strategy is to test the system the way people will actually use it. Cross-dialect benchmarks show that large language models can still underperform on dialectal inputs even when headline scores look strong, which is why dialect-specific slices matter so much. Counterfactual evaluation adds another layer by checking whether a model’s output shifts when only a sensitive attribute changes, and that style of testing can reveal hidden bias that average metrics blur away. Human validation also matters here, because native speakers can catch nuance that automatic scores miss.
When we put these pieces together, fairness stops being a single patch and becomes a careful routine. We document the data, balance it where possible, add dialect-aware training signals, normalize only when it truly helps, and keep evaluating by dialect rather than by one blended score. That sequence lines up with the broader mitigation literature, which organizes bias reduction across pre-processing, in-training, intra-processing, and post-processing. The practical lesson is reassuring: fairer NLP systems usually come from many small, deliberate choices, not one dramatic fix.



