Assess Source Schema
Before we redraw anything, a PostgreSQL to MongoDB migration starts with a quiet but important task: looking closely at the source schema. The source schema is the table layout, the columns inside those tables, and the rules that tie everything together. What does the data really look like once we peel back the table names? In PostgreSQL, those rules often live in primary keys, unique constraints, foreign keys, and column types, and they tell us which parts of the model are structural rather than accidental. That first pass gives us a map before we choose a new shape for the data.
The next thing we want to notice is how the tables talk to each other. A primary key is the column, or group of columns, that uniquely identifies a row, and PostgreSQL can even use more than one column for that job. A foreign key is the bridge that says one table must point to a real row in another table, which is how PostgreSQL keeps referential integrity, meaning it prevents broken relationships. When you assess the source schema, you are not just counting tables; you are tracing those bridges and asking which relationships are essential, which are optional, and which exist only because a relational design needs them.
Once the relationships are clear, the data types start telling their own story. PostgreSQL distinguishes carefully between exact numbers and approximate numbers: numeric is recommended when exactness matters, such as money, while real and double precision are inexact and can introduce small discrepancies. That difference matters during a migration because MongoDB documents can store values flexibly, but flexibility is not the same as clarity. If a column should always behave like an integer, a date, or an exact decimal, we want to recognize that now so the MongoDB schema can preserve the same business meaning instead of merely copying the shape of the old table.
This is also the moment to ask how the data is actually used. MongoDB works best when related data is either embedded in one document or linked with references, and the choice depends on the shape of the relationship and the way your application reads it. Embedded documents keep related data together and can reduce reads, but MongoDB documents must stay under 16 mebibytes, so very large or frequently changing child records may need to stay separate. References fit better when you have complex many-to-many relationships or data that changes often. In a migration, that means we should look at the PostgreSQL joins and ask which ones describe a natural “belongs together” relationship and which ones only exist because normalization split the data apart.
As we review the source schema, we should also look for the small clues that reveal the real model: nullable columns, composite keys, repeated lookup tables, and columns that seem to travel together in every query. Those patterns tell us where the PostgreSQL design is enforcing rules and where the application is simply carrying baggage from an older structure. This is the heart of a good PostgreSQL vs MongoDB migration guide: we are not copying tables one for one, we are learning the story those tables were trying to tell. With that map in hand, the next step is to decide how each piece should reappear in the MongoDB schema.
Map Tables to Documents
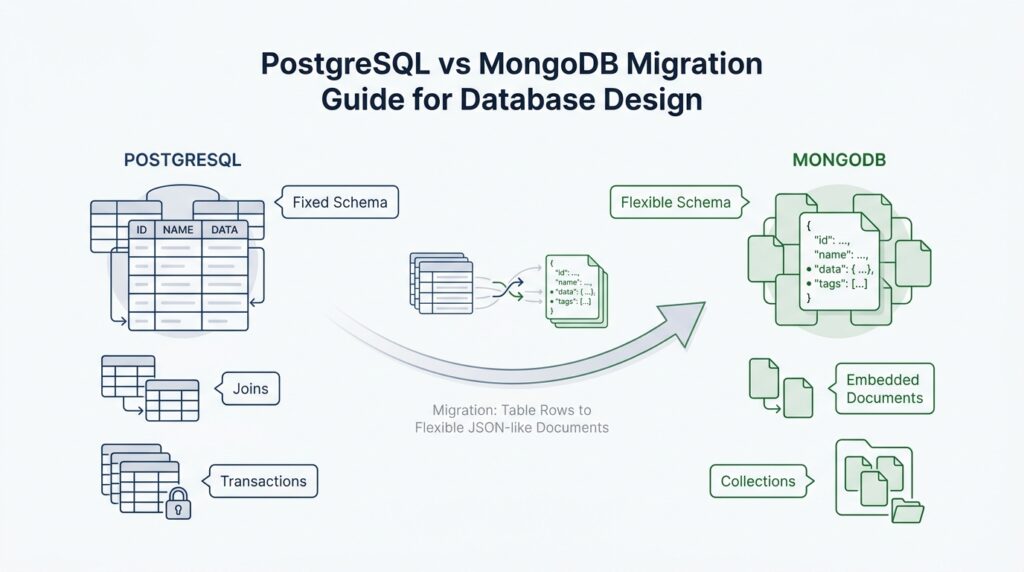
Now that we have the source schema in view, the next move in a PostgreSQL to MongoDB migration is to redraw the data around the way people actually use it. Instead of asking, “Which table becomes which collection?”, we ask, “Which pieces of information belong together in the same MongoDB document?” That shift matters because MongoDB performs best when related data is either kept together in one record or linked in a way that matches the application’s read patterns. In other words, we are not copying tables; we are reshaping a story into a document model.
A good starting point is to look for data that always travels as a small group. Think of an order, its shipping address, and the handful of line items attached to it: if your application usually reads them together, embedding them in one document can reduce the number of queries and let related updates happen in a single atomic write. That is the kind of fit MongoDB rewards. The catch is that documents have a hard size ceiling, so the combined data must stay comfortably below the 16 mebibyte BSON document limit. Once a group starts growing without a clear boundary, the design stops feeling tidy and starts feeling crowded.
This is where one-to-many relationships become very practical. If the “many” side is small, naturally owned by the parent, and usually read in context, an embedded array often feels like the right home. A customer profile with a few phone numbers, a product with a short list of attributes, or a ticket with a small history of status changes all behave like parts of one larger object. In a PostgreSQL to MongoDB migration, these are the places where a normalized design often loosens into a document structure without losing meaning. The important question is not whether the relationship exists, but whether the child data still makes sense when viewed as part of the parent.
Other relationships ask for more distance. When the child data changes often, when the relationship is many-to-many, or when each side needs to stand on its own, references are the safer choice. References keep the related records in separate collections and connect them with an identifier, which preserves independence and avoids duplicating data that would be painful to keep in sync. If you are wondering, “When should I embed, and when should I reference?”, this is the moment to let the access pattern answer for you: together for stable, tightly owned data; separate for complex, shared, or fast-changing data.
That same lens helps with more awkward parts of the source schema, like junction tables and lookup tables. In PostgreSQL, those structures often exist because normalization slices a business concept into smaller pieces; in MongoDB, we can often infer whether they are truly meaningful on their own or whether they are just a way of holding two related ideas apart. If the join table exists only to connect two entities that always appear together in the application, it may collapse into an embedded structure. If it also carries its own lifecycle, heavy reuse, or frequent independent reads, it usually deserves to remain separate. This is one of the quiet but important judgments in MongoDB schema design, and it comes from reading the data’s behavior, not its table names.
By the time we finish this mapping step, we should have a clear picture of which PostgreSQL tables become embedded objects, which ones become separate collections, and which relationships stay linked by references. That picture gives the MongoDB schema its first real shape, and it also tells us what to optimize next: field names, indexes, and query paths that match the new document layout. In a migration like this, the win comes from making each document feel like a complete, useful piece of the application rather than a table row in disguise.
Redesign Relationships
Once the tables have been mapped to documents, the real work begins: redesigning relationships so they fit how MongoDB reads and writes data. What do you do when a PostgreSQL foreign key has no obvious home in MongoDB? You step back and ask which side owns the data, how often the pieces change together, and whether the application usually needs them in one read. MongoDB’s data-modeling guidance centers on those questions because embedding can simplify common operations, while references suit relationships that are large, shared, or frequently queried on their own.
The easiest relationships to redraw are the ones that feel like a single object in real life. If a parent record and a small set of child details always travel together, embedding them in one document keeps the write local and lets MongoDB satisfy the request with one read; MongoDB also treats a single-document write as atomic, meaning either all of that document’s changes land or none do. That makes embedded data a good fit for stable “has-a” relationships, especially when the child data is not growing without bound.
This is where the 16 mebibyte BSON document limit becomes more than a footnote. If a child list can keep growing, or if the combined payload starts to feel bulky, the design needs breathing room, because MongoDB documents must stay under that size ceiling. In practice, that means we often keep the parent in one collection and move the expanding pieces into their own collection, linked by a reference field such as _id.
Many-to-many relationships deserve special care in a PostgreSQL to MongoDB migration. In PostgreSQL, a join table can look like a neutral connector, but in MongoDB we have to decide whether it is really part of the business object or a reusable relationship in its own right. If the connection is simple and always read with one side, we may collapse it into embedded subdocuments; if both sides need to stand alone, or if the relationship is complex and widely shared, references usually preserve the model better.
The next question is less about structure and more about change. When two pieces of data are updated at very different times, embedding can create accidental churn, because every small change rewrites the larger document; MongoDB’s guidance points to references when the child data changes often, has high cardinality, or would create too much duplication. Seen that way, relationship redesign is really a conversation about ownership: who owns this fact, who needs it first, and who can live without it for a moment?
As we make these decisions, we are also setting up the rest of the database design. A relationship that becomes embedded may no longer need a join, but it may need careful field naming and perhaps an index on a nested field; a relationship that stays referenced may need $lookup later, so we should keep the reference path clean and predictable. That is the heart of MongoDB schema design during migration: not preserving the old shape, but preserving the business meaning while letting the new document model work the way MongoDB expects.
Handle Data Type Changes
When we handle data type changes, we stop thinking about table shapes and start protecting meaning. In a PostgreSQL to MongoDB migration, the real question is: what happens to money, timestamps, arrays, and enums when the storage engine changes under them? PostgreSQL gives you a rich type system, including numeric, date/time types, arrays, enums, and uuid, while MongoDB stores values as BSON types such as string, array, date, integer, long, and Decimal128. That means the move is less about translation and more about choosing the closest MongoDB home for each idea.
Money and exact counts are usually the first place where we need to slow down. PostgreSQL numeric is designed for exact results and is often recommended when exactness matters, while MongoDB’s Decimal128 gives us a 128-bit decimal format with 34 digits of precision. If the source column used real or double precision, we should ask whether the application can live with approximation or whether the field deserves a more exact home in the MongoDB schema. That one decision can save us from tiny rounding errors that would be hard to explain later.
Dates need special care because PostgreSQL distinguishes date, time, timestamp without time zone, and timestamp with time zone. PostgreSQL stores timezone-aware values in UTC and displays them in the current local zone, while BSON Date represents a UTC datetime and BSON Timestamp is meant for internal MongoDB use rather than ordinary application dates. In practice, a PostgreSQL timestamptz often becomes a BSON Date, but if the original system cared about the exact wall-clock time a user entered, we may need to preserve that zone or local-time meaning in a separate field.
Arrays are the next kind of shape-shifter. PostgreSQL can store one- and multi-dimensional arrays of many element types, and MongoDB arrays can hold values, nested objects, and arrays of documents. If the PostgreSQL array was a simple ordered list, we can carry it across as a BSON array; if it was really a bundle of structured records, we should convert it into an array of subdocuments so each item keeps its own fields. That choice keeps the MongoDB schema honest instead of forcing a relational trick into a document-shaped space.
Some types change more in spirit than in syntax. PostgreSQL enums are separate, ordered types, while MongoDB’s BSON layer gives us primitives like strings and integers that our application can use to represent those states. Plain text and varchar fields usually become strings, and UUIDs can stay UUID-like by using MongoDB’s binary UUID support, or be stored as strings if that fits the surrounding code better. For PostgreSQL JSON or JSONB data, nested MongoDB documents and arrays often feel natural because both models already speak in tree-shaped data.
The safest way to finish data type changes in a PostgreSQL to MongoDB migration is to write down a conversion rule for every important column: source type, target type, validation rule, and any code that must reinterpret the value. MongoDB’s schema design process is meant to be iterative, so these notes give us a clear path from the old model to the new one instead of a vague pile of assumptions. If a field is exact, preserve exactness; if it is temporal, decide whether you need UTC or local meaning; if it repeats, decide whether an array or embedded object tells the truth better. Once those decisions are written down, the new MongoDB schema starts feeling like a translation, not a compromise.
Migrate and Validate Data
Once the first batch lands in MongoDB, the PostgreSQL to MongoDB migration turns into a trust exercise. We are no longer only asking whether the document shape looks right; we are checking whether every row arrived with the same meaning. If you’re wondering, “How do I know the migration is correct?”, the answer starts with a staging collection, where we can compare, correct, and repeat before the application points at the new data. MongoDB schema validation can then act like a gatekeeper, checking fields for allowed types and value ranges once we know what the application expects.
The first comparison is usually the simplest: counts, keys, and required fields. MongoDB standard collections require a unique _id field, so keeping the old PostgreSQL primary key alongside it during the import makes traceability much easier while we reconcile the two worlds. If a source row disappears, duplicates, or lands under the wrong key, we find it faster when we can trace one record to another instead of guessing from the shape alone. That small habit saves a lot of confusion later.
After that, we tighten the target with schema validation. MongoDB lets us define JSON Schema rules, which means we can require specific fields, limit accepted types, and set minimum or maximum values. If we add those rules after the initial load, validationLevel decides how the rules apply to existing documents, and MongoDB rejects invalid inserts or updates by default; if we later need to change the rules, collMod updates the collection validation without rebuilding the whole collection. This is the part of migration where the database itself starts helping us protect the new model from drift.
This is also the right moment to inspect the documents themselves, not just the totals. When related data now lives together in one BSON document—BSON being MongoDB’s binary JSON storage format—MongoDB treats a single-document write as atomic, so the grouped data should feel complete every time we read it back. A few hand-picked records can reveal whether embedded arrays, nested objects, and renamed fields still tell the same business story the PostgreSQL tables used to tell. In a PostgreSQL to MongoDB migration, those spot checks are often where we catch the awkward details that aggregate counts miss.
Size checks matter too, because MongoDB limits a BSON document to 16 mebibytes. The $bsonSize aggregation operator returns the size of a document in bytes, which makes it handy for spotting records that are drifting toward that ceiling before they become a problem. In practice, that means we do not wait for a large order, a long history, or a crowded embedded array to break the design; we measure early and confirm the migrated shape can actually hold the real data.
For referenced data, we verify the relationships the old foreign keys used to enforce. If a child collection stores IDs that point back to a parent, every reference should resolve cleanly or be explained on purpose; if a lookup table used to feed many records, we should confirm that the target values still line up after the move. MongoDB’s schema-validation tools also make it possible to find documents that no longer match the rules after validation changes, which is useful when we are hunting for these quiet outliers. This is where the migration stops being a copy job and starts becoming a consistency check.
Once the staging data passes these checks, we run the application’s real read and write paths against it. We want the same business answers, not just the same document counts, because a migration can still be wrong if a query now returns the right number of records in the wrong shape. When the imports are clean, validation stays quiet, and the important queries behave the same way they did before, we have more than a copy—we have a trustworthy MongoDB version of the old system.
Optimize Indexes and Queries
Once the data model is in place, the next job in a PostgreSQL vs MongoDB migration is to tune indexes and queries so the new schema can actually move fast. This is the moment where we stop admiring the shape of the documents and start asking how the application will walk through them every day. An index is a searchable shortcut, like the tabs in a well-marked notebook, and MongoDB queries are the paths that use those shortcuts to find data without scanning everything. If the schema is the map, indexes are the roads we decide to pave first.
The easiest place to begin is with the questions the application asks most often. How do you know which fields deserve an index? You look at the read patterns we uncovered earlier: the filters, sorts, and lookups that appear again and again in the same screens or API calls. If a query always searches by customer_id and then orders by created_at, a compound index, which is an index built from more than one field, can help MongoDB answer both parts of the question in one pass. This is a familiar idea from PostgreSQL index design, but in MongoDB query optimization the order of the fields matters even more because the index should match the way the query narrows and sorts results.
That is why we want to read the query shape before we reach for more indexes. A query that filters on a highly selective field, meaning a field with many distinct values, usually benefits more from indexing than a field that repeats the same value across thousands of documents. If a query asks for one order by its ID, an index gives us a fast lane. If it asks for every order with a common status like open, the index may still help, but not as dramatically, because MongoDB has to walk through more matching entries. In a PostgreSQL vs MongoDB migration, this is where we stop thinking in table terms and start thinking in traffic patterns.
The next step is to make the query itself work with the document layout we built earlier. When we embedded related fields, we reduced the need for joins, and now those nested fields can often be queried directly with dotted paths, which are field paths like address.city or items.sku. That is powerful, but it also means the query has to stay precise, because a small change in structure can change how MongoDB uses an index. If we are sorting or filtering on a nested field, we often need an index on that exact path rather than on the parent object as a whole. This is one of the quiet advantages of a thoughtful MongoDB migration: the schema and the query plan start fitting together instead of fighting each other.
We also want to be careful with joins that survived the move as references. MongoDB can connect collections with $lookup, which is a stage that joins data from another collection, but every join adds work, so it should feel like a deliberate choice rather than a habit carried over from PostgreSQL. If a query keeps reaching across collections for the same related records, that is a signal to revisit the schema, the index strategy, or both. In other words, query tuning is not only about making MongoDB faster; it is also a final test of whether the new data model matches the way the application really thinks.
The best habit here is to inspect the execution plan, which is MongoDB’s explanation of how it decided to run a query. That plan tells us whether MongoDB used an index, scanned too many documents, or sorted in memory because the index did not line up with the request. In practice, we compare the slow queries first, trim unused indexes, and add only the ones that support real traffic rather than imagined traffic. In a PostgreSQL vs MongoDB migration, this is the point where the database starts feeling responsive instead of merely compatible, and the application can finally read its new documents the way they were meant to be read.



