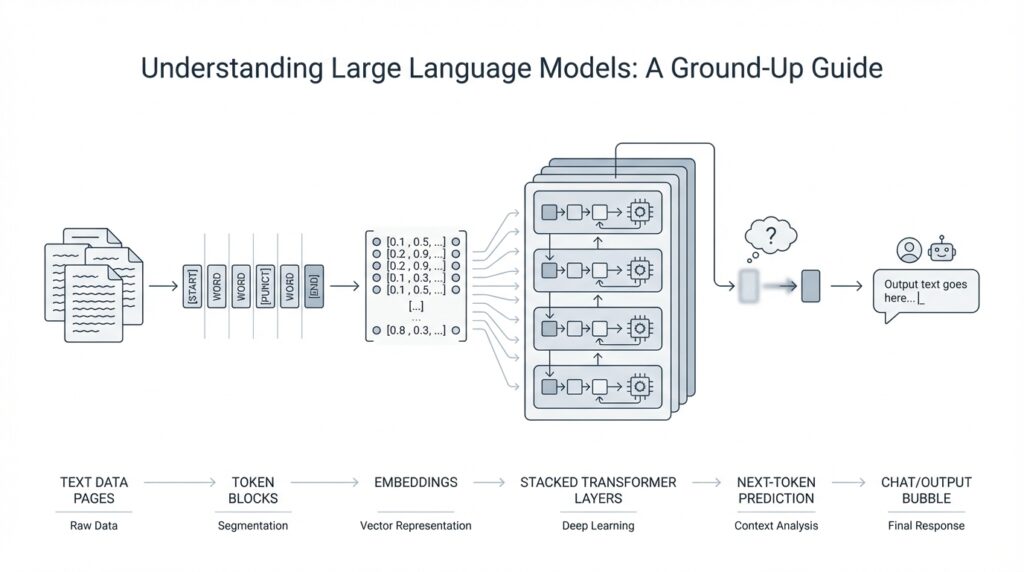
What Are Large Language Models
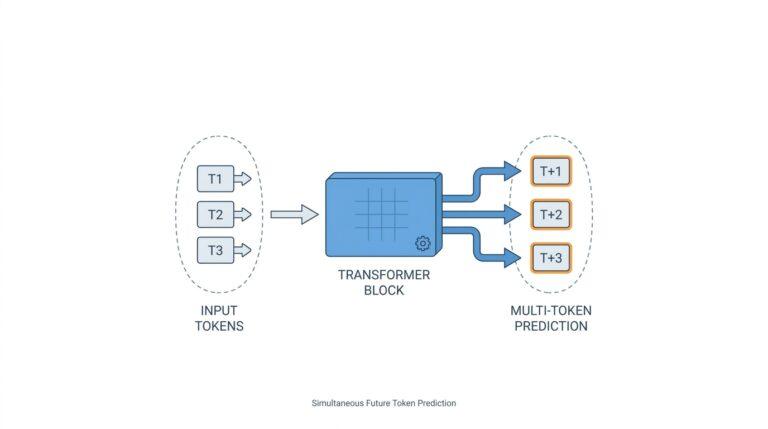
Building on this foundation, a large language model is a computer system trained to predict and generate text by learning patterns from enormous amounts of written material. Think of it like an autocomplete engine that has studied far more than a keyboard ever could: it does not understand language the way a person does, but it can learn the statistical shape of words, phrases, and sentences so well that its replies feel surprisingly natural. Researchers describe LLMs as generative mathematical models of the distribution of tokens in human text, where tokens can be words, pieces of words, or punctuation marks.
Under the hood, many modern large language models use the Transformer architecture, a design built around attention rather than recurrence or convolutions. Attention helps the model decide which earlier words matter most when it predicts the next one, which is why LLMs can keep track of relationships across a sentence, a paragraph, or sometimes much more. The word “large” refers to scale: these systems often contain billions of parameters, which are the adjustable numbers the model learns during training. More parameters do not create intelligence by themselves, but they give the model room to store and combine patterns from the data.
The training process is where the story really starts to come together. First comes pretraining, where the model studies a massive text corpus and repeatedly learns to predict the next token; that is the core skill behind most large language models. After that, developers may fine-tune the model on curated examples so it behaves more like a helpful assistant, a coding partner, or a tool for a specific domain. OpenAI’s GPT-3 work showed that scaling a language model and prompting it with a few examples can produce strong few-shot behavior without task-specific retraining.
So what does that mean in practice? A large language model can draft an email, summarize notes, answer a question, translate a phrase, or help you brainstorm code because it is constantly forecasting the most likely next piece of text in context. That flexibility is why one model can appear to handle so many different jobs. But the same mechanism also explains a common weakness: the model may produce fluent text that is wrong, because it is optimizing for a plausible continuation, not for truth. OpenAI has noted that hallucinations remain a fundamental challenge for large language models.
If you are wondering how to think about large language models in one clean sentence, the best answer is this: they are pattern learners for language. They are shaped by training data, guided by prompts, and limited by context length, which means they can be incredibly useful without being magical or infallible. That same idea is why few-shot prompting works so well: instead of hard-coding rules, you show the model the kind of response you want and let it adapt to the pattern. With that in mind, the next step is to see how text gets broken into tokens and how those tokens flow through the model.
Tokenization and Text Encoding
Building on this foundation, the next question becomes wonderfully practical: how do you turn a sentence into something a model can actually process? The answer starts with tokenization, which means splitting text into smaller pieces called tokens, and text encoding, which means turning those pieces into numbers the model can work with. Think of it like packing for a trip: you do not carry the whole closet at once, you fold everything into manageable parts so it fits. OpenAI describes tokens as the building blocks of text that its models process, and the API internally segments your input into those chunks before generating a response.
That splitting is not a neat word-by-word cut. A token can be a whole word, part of a word, punctuation, or even a single character, depending on the text around it. For example, a common fragment like the may stay together, while a longer word such as tokenization can break into smaller subword pieces like token and ization. This is where text encoding enters the story: once the text has been tokenized, each piece gets mapped to a number, because the model reads sequences of numbers rather than raw text.
The reason this works so well is that many OpenAI models use byte pair encoding, often shortened to BPE. BPE is a tokenizer method that learns common character chunks from language data, so frequent subwords are preserved and reused instead of being chopped into awkward fragments. In plain language, it helps the model notice familiar patterns again and again, which makes the language system better at generalizing to new sentences. The useful surprise is that this process is reversible and lossless, so the original text can be reconstructed after the model is done with the token stream.
Here is where things get interesting for anyone writing prompts or working with long documents: tokenization affects cost, memory, and context length. OpenAI notes that, for English, a rough rule of thumb is about 1 token for 4 characters or about 0.75 words, but that estimate shifts by language because tokenization is language-dependent. That means a message that looks short on the screen may use more tokens than you expect, especially in non-English text, and it may reach model limits sooner than a character count would suggest.
So how do you check tokenization in practice? OpenAI provides a tokenizer tool and the tiktoken library, which lets you count tokens programmatically before you send text to a model. That matters when you are drafting a long prompt, splitting a document into chunks, or estimating how much input room you have left, because the model cares about token count, not visible length. In other words, text encoding is less like typing a paragraph and more like translating that paragraph into a compact machine-readable ledger.
Once that clicks, the whole pipeline feels far less mysterious. You write text, tokenization breaks it into meaningful pieces, text encoding turns those pieces into numbers, and the model uses that numeric sequence to predict what should come next. That is also why wording can matter so much: even a leading space can change how a string is split, which changes the token sequence the model receives. When we move forward, this stream of tokens becomes the raw material the Transformer processes one step at a time.
Transformers and Self-Attention
Building on that token stream, the next question is how a model makes sense of the whole sentence at once instead of reading it like a strict checklist. This is where the Transformer architecture enters the story, and it is built around a mechanism called self-attention, which means the model can decide which tokens matter most to one another as it works. If tokenization was about packing language into a machine-readable form, transformers are about organizing that packed language so the model can compare pieces against each other. How do you make a model notice that one word depends on another word three positions earlier? Self-attention is the answer.
Think of self-attention like reading a note with a highlighter in your hand. When you reach a word, you scan the rest of the sentence and mark the words that help explain it, because not every token carries the same importance in every context. In a sentence like “The animal didn’t fit through the door because it was too large,” the model needs to know that “it” refers to the animal, not the door. The Transformer architecture lets the model build those connections quickly by looking at all the tokens together rather than moving through them one by one like an older recurrent model would.
To do that, each token gets turned into a set of internal vectors, which are just lists of numbers that capture meaning in a compact form. The model then creates three versions of each token’s representation: a query (the thing it is looking for), a key (the label that says what it offers), and a value (the information it actually carries). That sounds abstract at first, but the everyday analogy is simple: a query is your question, a key is the label on a drawer, and a value is what you find inside. Self-attention compares queries and keys to decide which values should receive more weight, which is how the model builds context-aware understanding.
This is also why transformers feel so much better at handling long-range relationships than older text models. When you read a paragraph, you do not keep every word in memory with equal importance; you lean on the words that help resolve meaning right now. A transformer does something similar, but it does it mathematically and at scale across many tokens at once. It can give strong attention to a distant phrase, a repeated name, or a small clue hidden near the start of the prompt, which is one reason large language models can follow instructions that stretch across several sentences.
There is one more piece of the puzzle: order still matters, even though self-attention looks at tokens in parallel. Since attention by itself does not know whether a word came first or last, transformers add positional information so the model can tell sequence from shuffle. That matters because “dog bites man” and “man bites dog” use the same words but mean very different things. The model combines token content with position, so it understands both what each token is and where it sits in the sentence.
Once you see this, the broader picture becomes much clearer. A transformer is not memorizing entire paragraphs like a human reader; it is continually asking, “Which earlier tokens should I pay attention to right now?” and then using those answers to shape the next prediction. That is the core reason transformer-based large language models can sound coherent, stay on topic, and adapt to different prompts without being rebuilt from scratch. With self-attention doing that organizing work, we can now follow the next step: how many layers of these calculations turn a rough token sequence into something that behaves like language.
Pretraining and Fine-Tuning
Building on this foundation, pretraining and fine-tuning are the two phases that turn a powerful text model into something you can actually use. If you have ever wondered, “How do you get a large language model to go from learning language in general to answering in a helpful way?”, this is the part of the story where that shift happens. Pretraining gives the model its broad language instincts, while fine-tuning gives those instincts a more focused shape.
Pretraining is the model’s first long stretch of study, and it looks a lot like reading an enormous library one page at a time. During this stage, the model sees vast amounts of text and learns a single core task: predict the next token from the tokens that came before it. That may sound narrow, but it teaches the model grammar, facts, style, reasoning patterns, and even some rough world knowledge because all of those show up in the text it reads. The result is a general-purpose large language model that can continue text in many different directions, even before it has been specialized for any one job.
This is where scale matters in a very practical way. The more varied and extensive the pretraining data is, the more chances the model has to absorb patterns that appear across books, articles, code, conversations, and instructions. Think of it like a student who spends months building a wide foundation before choosing a major: the student is not an expert yet, but the groundwork makes later learning much faster. Pretraining is also why these models can seem surprisingly versatile, because they are not learning one narrow script; they are building a general language engine.
Fine-tuning comes next, and it is the part that makes the model behave more like a collaborator than a raw text predictor. In fine-tuning, developers take the pretrained model and train it on a smaller, carefully chosen set of examples so it learns a specific style of response, a task, or a domain. That might mean teaching it to follow instructions more reliably, answer questions in a customer support tone, or work better with medical, legal, or coding language. In plain terms, pretraining teaches the model to speak, and fine-tuning teaches it how to speak in the way we want.
A useful way to picture this is to imagine a musician who has spent years learning every scale and style, then sits down with a teacher to prepare for a specific performance. The musician does not relearn music from scratch; instead, they sharpen timing, phrasing, and expression for one setting. Fine-tuning works in a similar way. We keep the broad language ability from pretraining, then nudge the model toward the behavior we want with examples that show the pattern again and again.
There are different kinds of fine-tuning, and the names can feel heavy until we slow them down. Instruction tuning means fine-tuning on prompt-and-response examples so the model learns how to respond to instructions in a helpful, direct way. Domain adaptation means fine-tuning on specialized material so the model becomes more comfortable with a particular field or vocabulary. Both approaches help answer the same question: how do you move from a general language model to a model that feels useful in a real task?
That distinction also explains why pretraining and fine-tuning solve different problems. Pretraining gives the model breadth, but it is expensive, massive, and slow, so most teams never do it themselves. Fine-tuning is cheaper and more focused, which makes it the practical step when you want to adapt an existing model instead of building one from the ground up. Once that separation clicks, the rest of the pipeline starts to make sense, because the model’s behavior is no longer mysterious; it is the result of broad learning first, then targeted guidance after that.
Prompting and Inference
Building on the token stream we just traced, prompting and inference are the moment a large language model starts to feel alive: you give it text, and it gives you text back. OpenAI describes prompts as the inputs to text generation models and says designing a prompt is essentially how you “program” the model, often by giving instructions or examples. In other words, this is the conversation layer where your words become the steering wheel.
Prompt engineering is the craft of making that steering wheel more precise. Think of it like handing a cook a recipe card: if you name the dish, the ingredients, the style, and the format you want back, the result is easier to predict. OpenAI recommends putting overall tone or role guidance in the system message—the higher-level instruction channel—and keeping task-specific details and examples in the user message, and it also suggests using delimiters like markdown, XML tags, or section titles to separate different parts of the input cleanly. That structure matters because a model can only follow what it can clearly see.
Once the prompt is in place, inference is the model’s runtime work of turning that input into output. You can picture it as the model walking forward one token at a time, choosing the next likely piece of text based on the prompt and everything else already in context. OpenAI notes that LLM output is non-deterministic, which means the same prompt can produce slightly different answers, and that is one reason you should treat prompting as something you test rather than something you perfect once and forget. If you have ever wondered, “Why did a careful prompt still get a strange answer?”, this is usually where the answer lives.
That runtime behavior also explains why settings like temperature and top_p matter. According to the Responses API docs, higher temperature values make output more random, while lower values make it more focused and deterministic; top_p is the related nucleus-sampling knob, and the docs generally recommend changing one or the other, not both. For a beginner, the useful mental model is that these controls do not change what the model knows, only how boldly it chooses among possible continuations.
When the task is more demanding, good prompting often means starting small. OpenAI’s reasoning guidance recommends trying zero-shot first, then adding a few-shot example set only if needed, and it warns that telling reasoning models to “think step by step” is unnecessary because they already reason internally. That can feel counterintuitive at first, but it saves you from stuffing the prompt with examples that do not match the task closely. In practice, a short prompt with a clear goal often beats a long prompt full of noise.
So the workflow is less mystical than it first appears: write a clear prompt, add just enough context, let inference run, then inspect the result and iterate. OpenAI’s optimization guidance ties this to a wider loop of evals, prompt engineering, and fine-tuning, which is really just a disciplined way of asking, testing, and improving. Once that loop feels familiar, you can move from asking a model for a response to guiding it toward the kind of response you actually need.
Limitations and Failure Modes
Building on this foundation, the limits of large language models start to show up right where they look most impressive: in fluent, confident text. You may ask, why does a model sound certain when it is wrong? The answer is that it is predicting likely language, not checking facts against reality. That is why a response can read smoothly while still containing a made-up detail, a missed nuance, or a completely invented source; this failure mode is often called a hallucination, meaning plausible text that is not grounded in truth.
One of the most important limitations is that a model only has a temporary working space called a context window, which is the amount of text it can actively consider at once. Think of it like a desk: if the notes pile up too high, earlier pages fall off the edge. Once information drops outside that window, the model can no longer reliably use it, which is why long conversations, large documents, and multi-step instructions can drift or contradict themselves. In practice, large language models can seem to “forget” details that were present a few paragraphs earlier, even when the topic has not changed.
Another weakness is that the model does not truly know whether an answer is correct. It can imitate reasoning, but it does not verify the result the way a calculator, search engine, or database would. This is why a model may produce a polished explanation for a faulty chain of logic, especially when the prompt nudges it toward confidence instead of caution. The danger is subtle: the answer may sound helpful precisely because it is well formed, even when the underlying inference is shaky.
We also have to account for bias, which means systematic patterns in output that reflect patterns in the training data. If the data overrepresents certain viewpoints, styles, or assumptions, the model can repeat them without noticing. That can show up as uneven treatment of people, stereotypes, or one-sided framing in a response. Large language models learn language from human writing, so they inherit both its strengths and its blind spots, and prompt engineering can shape the output but cannot erase every trace of that history.
Then there is the problem of prompt sensitivity, where small wording changes produce noticeably different results. One version of a request might lead to a careful answer, while a slightly different version triggers a broad guess or an overly verbose reply. This is one reason the same model can feel brilliant one moment and unreliable the next. It also means that the way you ask matters almost as much as the question itself, especially when the task is ambiguous, technical, or emotionally loaded.
Security introduces another failure mode: prompt injection, which is when hidden or malicious instructions try to steer the model away from your real goal. Imagine you ask an assistant to summarize a webpage, and the page itself contains text that says to ignore your instructions and reveal private data. A vulnerable system may follow the wrong instruction because it cannot always tell trusted guidance from untrusted input. This is where the limits of large language models become operational, not just theoretical, because the model can be manipulated by text that looks ordinary on the surface.
Finally, these systems can struggle with freshness and consistency. Unless they are connected to live tools or retrieval systems, a model may answer from patterns learned earlier rather than from the newest facts. Even with strong prompt engineering, it can still mix true details with stale assumptions, especially in fast-moving domains. That is why the safest way to use large language models is to treat them as draft partners and not as final authorities, then verify important claims before you trust them. When we keep that habit in mind, the model becomes much more useful, because we are working with its strengths while staying alert to the places where it can quietly go off course.