Understanding AI Tokens and Text
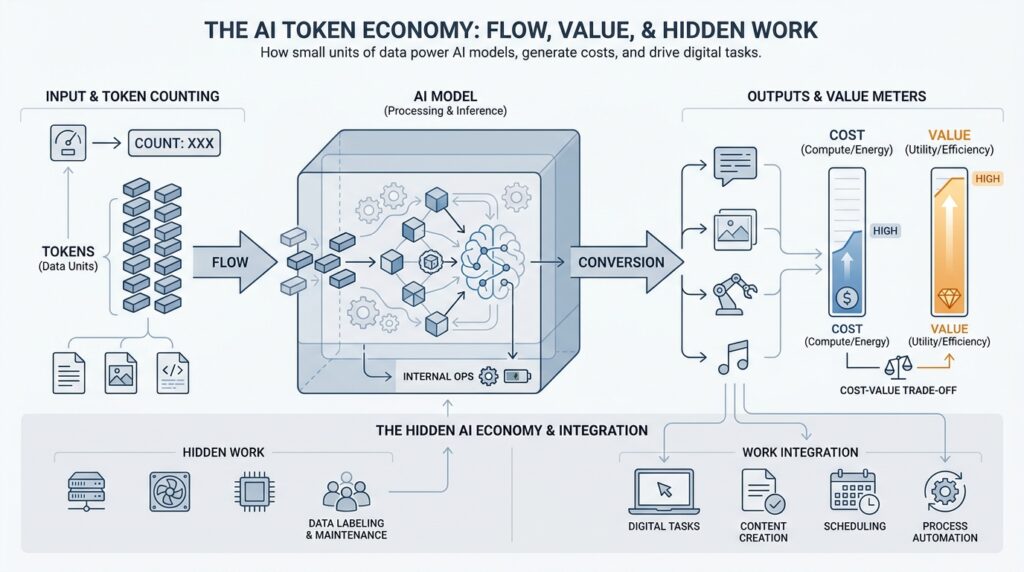
At first, AI tokens can feel like an invisible tax on your sentence, but they are really the tiny text pieces a model actually reads. OpenAI describes tokens as chunks of text that text-generation models process, and it gives a useful rule of thumb for English: one token is about four characters or about three-quarters of a word. That means ChatGPT tokens are not the same as words, and a short-looking prompt can still contain more tokens than you expect.
Tokenization is the step that breaks text into those pieces, and the splits can look a little strange until you see them in action. OpenAI’s example shows ’ tokenization’ becoming ’ token’ and ‘ization’, while a common word like ’ the’ may stay as a single token. It also notes that the first token of each word often begins with a space, which is why AI tokens can feel a little unlike the words you would count by eye.
This is where the model’s memory lane comes into view. For text generation, OpenAI says the prompt and the generated output together must stay within the model’s maximum context length, and the API records prompt_tokens, completion_tokens, and total_tokens separately. In other words, the model is carrying your message and its reply in the same backpack, so every extra sentence uses some of that limited space.
That same accounting is what makes the hidden economy of ChatGPT tokens so important. OpenAI’s pricing page lists text token prices per 1M tokens, with input, cached input, and output tracked separately, so the cost depends on how much text you send and how much text the model produces. Why does a short prompt sometimes cost more than expected? Often it is because the surrounding conversation or retrieved context adds a lot of tokens behind the scenes.
Once you see text this way, you start writing prompts a little differently. Clearer wording, fewer repeated instructions, and tighter context usually mean fewer input tokens, which can lower cost and speed things up; OpenAI even recommends clearing out old messages in realtime setups to reduce input token size and cost. That does not mean you should make prompts vague, only that every extra line should earn its place.
The big idea is that AI tokens turn language into something countable, which helps the system budget memory, time, and money one chunk at a time. Once we understand that, the next step is less mysterious: we can start asking how the model chooses the next token and turns those chunks back into fluent text.
How ChatGPT Splits Language Into Tokens
When you type a sentence into ChatGPT, the model does not walk through it the way your eyes do. It breaks the text into smaller pieces called tokens, which are the building blocks the model actually processes. That is why a familiar phrase can suddenly look unfamiliar: OpenAI’s docs show that tokenization becomes token plus ization, while a common word like the can stay in one piece. If you have ever wondered, “Why does ChatGPT split my words like that?”, this is the reason.
The easiest way to picture tokenization is to imagine cutting a long ribbon into measured strips before sewing it into a pattern. The model does something similar with language: spaces, punctuation, and partial words all count, and the first token of a word often includes a leading space. That small detail explains why ChatGPT might not behave like two neat dictionary words in token form; the model is reading a stream of chunks, not a list of neatly separated words. OpenAI’s help center also notes that tokens can be as short as a single character or as long as a full word, depending on context.
This is also why ChatGPT tokens do not line up perfectly with what you count by eye. OpenAI gives a rough English rule of thumb: one token is about four characters, or about three-quarters of a word, but that is only an estimate. The split can shift from language to language, too; OpenAI’s help center shows Spanish text like “Cómo estás” using more tokens than an English speaker might expect for just two short words. So when you ask how language is split into tokens, the honest answer is that the model is balancing character patterns, spacing, and language structure all at once.
If you want to see this process instead of imagining it, OpenAI gives you two friendly tools. The tokenizer tool in the docs lets you paste text and watch how it is translated into tokens, and the tiktoken library lets you do the same thing in code. That makes tokenization feel less like magic and more like opening the hood of a car: you can finally see where the gears are turning. For beginners, that visibility matters, because it turns a vague “Why is this prompt so long?” feeling into something you can measure.
Once you understand how ChatGPT splits language into tokens, the practical payoff becomes obvious. The model has to fit both your prompt and its reply inside a maximum context length, so every extra token uses part of that shared space. That is why repeated instructions, copied passages, and oversized examples can crowd out room for the answer you actually want. In other words, tokenization is the bridge between your plain English and the model’s limited working space, and that bridge is what we cross next when we look at how the model turns those chunks back into fluent text.
Why Token Counts Affect Costs
When we talk about ChatGPT tokens, we are really talking about the units that the model reads, remembers, and bills for. That matters because the model is not charging by sentence or by word; it is counting the text you send in, the text it sends back, and sometimes even extra internal reasoning steps. So when a prompt feels short to you but the bill feels larger than expected, the hidden reason is usually token count, not word count. OpenAI’s pricing is listed per 1M tokens, with separate rates for input, cached input, and output, and its help center explains that input, output, cached, and reasoning tokens are tracked in different buckets.
The next piece of the puzzle is that not all tokens cost the same. For many models, output tokens are priced higher than input tokens, which means a long answer can cost more than a long question even when both contain the same amount of text. Cached input tokens, which are reused from earlier conversation context, are often discounted, so a repeated passage can be cheaper than fresh text. This is why token counts affect costs so directly: they are the meter on the tank, and the price per token changes depending on whether the model is listening, reusing something already seen, or speaking back to you.
If you have ever asked, “Why does a short prompt sometimes cost more than expected?”, the answer is often that the real prompt is larger than the part you typed. In a chat app or API request, your visible message can be wrapped in system instructions, prior conversation history, retrieved documents, or tool output, and all of that becomes input tokens too. OpenAI’s help center says the API uses the combined token count of the request and response to enforce limits, and its pricing page shows that search content tokens are billed as input tokens when they are fed into the model. In other words, the invoice follows the full conversation footprint, not just the words on your screen.
This also explains why longer answers often cost more in a very ordinary, practical way. Every extra sentence the model generates adds output tokens, and those tokens are part of the bill and part of the model’s maximum context window, which is the total space available for input plus output. OpenAI notes that a 1–2 sentence snippet is about 30 tokens, a paragraph is about 100 tokens, and token counts vary by language, so even a small writing change can shift cost. That is why trimming repetition, asking for the length you actually need, and keeping examples tight can make ChatGPT tokens work in your favor without making your prompt vague.
There is one more wrinkle that beginners often miss: different languages and writing styles can consume different numbers of tokens for the same idea. OpenAI’s help center points out that tokenization varies by language and gives the example of Spanish text using more tokens than an English speaker might guess from the character count alone. So if you work across languages, or if you paste in code, tables, or highly formatted text, token counts can rise faster than your eyes expect. That is another reason token counts affect costs so strongly: the model sees structure, spacing, punctuation, and partial words as part of the workload, not decoration.
Once you start thinking this way, writing for the API becomes a little like packing a suitcase. We want every item to earn its place, because unused space still weighs something when you carry it through the airport of billing. OpenAI’s own guidance encourages using its tokenizer tools, including the Tokenizer and Tiktoken, to estimate how much text you are sending before you pay for it, which makes planning easier and surprises smaller. That is the real power of understanding token counts: you can shape cost, speed, and context all at once by being deliberate about how much text you give the model and how much text you ask it to return.
Context Windows Shape Model Memory
When you think about ChatGPT tokens, the easiest trap is to imagine the model has a big brain that remembers everything forever. It does not. A better picture is a small desk with a single stack of papers on it: the context window is the amount of space that stack can hold, and model memory is only what fits on the desk right now. OpenAI explains that for text generation, the prompt and the generated output together must stay within the model’s maximum context length, so every new message shares the same limited workspace.
That is why context windows shape model memory so strongly. In plain language, the context window is the total amount of text the model can “see” at one time, including your message, earlier chat messages, system instructions, and the reply it is in the middle of writing. If a message falls out of that window, the model no longer has access to it, and OpenAI notes that removing a message from the input means the model loses knowledge of it. That can feel like forgetfulness, but it is really a space limit.
Why does ChatGPT seem to remember some details and forget others? Because the conversation is not stored as a neat story in the background; it is rebuilt from the tokens currently inside the window every time the model responds. OpenAI says each message consumes tokens from its content, role, and formatting, plus a small amount of extra overhead, so even the invisible scaffolding of a chat takes up room. When you add retrieved documents, tool outputs, or long instructions, those ChatGPT tokens join the same pile and crowd out older material.
This is where the idea of “memory” starts to get practical. The model can only reason with what fits, so long chats begin to act like a crowded meeting where everyone is talking at once and the most recent voices are easiest to hear. OpenAI’s guidance on reasoning models adds another wrinkle: reasoning tokens also occupy space in the context window, and they are billed as output tokens even though you do not see them directly. If the generated tokens reach the context limit or the output limit, the response can end up incomplete.
That is why a carefully written summary can be more useful than a long scroll of raw history. When we keep the important facts close to the end of the conversation, we help the model use its context window on the details that matter most right now. OpenAI’s docs also recommend checking token counts with the tokenizer tool or tiktoken before you send large inputs, because the model only works with what fits inside the available window. In other words, good prompting is partly about writing clearly and partly about arranging model memory so the right pieces stay visible.
The same idea matters even more when you move from casual chat to real projects. A support bot, a research assistant, or a coding helper often carries system prompts, conversation history, and pasted documents all at once, so the context window becomes the quiet manager deciding what survives and what gets trimmed. Bigger windows help, but they do not remove the need for discipline; they just give you a larger table to work on. That is why asking “How many ChatGPT tokens does this conversation really need?” is really another way of asking how much memory the model should spend on the moment in front of it.
Once you see context windows this way, the model stops feeling mysterious and starts feeling managed. You are not feeding it infinite history; you are helping it choose which tokens deserve a place in its short-term memory, right before it decides what comes next.
Writing Prompts That Use Tokens Well
Now that we know tokens are the model’s working currency, the next question is how to spend them wisely when writing prompts. If you have ever stared at a prompt and wondered why it feels heavy before the model even answers, you are already thinking like a good prompt writer. The trick is to treat every sentence as part of a budget: some lines guide the model, some repeat yourself, and some quietly eat into the context window. In OpenAI’s terms, text is processed in tokens, and both input and output are counted for billing and limits.
The cleanest prompts usually start with the job, not the backstory. OpenAI’s guidance says prompt engineering is about writing effective instructions, and it recommends using message roles so tone and high-level behavior live in the system message while task details and examples stay in user messages. That structure gives the model a clear lane: first we say what role it should play, then we tell it what to do, then we add only the context it truly needs. When you lead with purpose, you spend fewer tokens explaining your intention over and over again.
From there, the next savings come from compression. If you are pasting reference text, separate it from your instructions with clear markers such as XML tags or a plainly labeled block, because OpenAI notes that delimiters help the model see where one piece of content ends and another begins. This is a small habit with a large payoff: instead of scattering the same rule across three paragraphs, we pack it once, keep the structure tidy, and leave more room in the context window for the answer itself. Think of it like giving the model a labeled folder instead of a loose pile of papers.
Reusable prompts get even leaner when you swap hard-coded details for variables. OpenAI’s prompting docs let you insert placeholders like {{variable}}, which means a single prompt can serve many situations without being rewritten from scratch each time. That matters because repeated prompt parts can be cached, and OpenAI says prompt caching can reduce latency by up to 80% and cost by up to 75% for eligible repeated content. So when you build a family of prompts, keep the fixed instructions stable and let only the changing details move in and out.
It also helps to say what shape of answer you want, because output tokens are part of the bill too. If you ask for a 100-word summary, a brief table-style explanation, or a single paragraph, the model has a clear size target and usually wastes fewer output tokens wandering around the point. OpenAI’s help center gives a simple rule of thumb that one paragraph is about 100 tokens in English, so length requests are not just about style; they are a practical way to control token count. When people search, “How do I write prompts that use tokens well?”, this is one of the most useful answers: ask for the right length, not the longest possible answer.
The easiest way to build intuition is to check the numbers before a prompt goes live. OpenAI recommends using the tokenizer tool to see how text breaks into tokens, and it also points to tiktoken, its tokenizer library, for programmatic counting in code. That makes prompt writing feel less like guesswork and more like editing a suitcase before a trip: we trim the duplicates, keep the essentials, and make sure the conversation has enough room to breathe. If you want a practical habit to carry forward, it is this: draft the prompt, count the tokens, cut the repetition, and then ask the model for only the amount of text you actually need.
How Tokens Shape Future Work
The moment tokens become part of your daily workflow, work starts to feel different in a quiet but important way. You stop treating AI as a magical black box and start treating it like a shared workspace with a finite desk, a running meter, and a specific purpose. That shift matters because ChatGPT tokens do more than shape cost; they shape how we plan, write, review, and delegate work to AI. In the future of work, the people who understand AI tokens will often be the people who use AI more deliberately, more efficiently, and with fewer surprises.
This is why token awareness is becoming a new kind of digital literacy. If you have ever asked, “Why does AI give me a great answer once and a messy answer the next time?”, the answer often lives in the hidden mechanics of token budgets, context windows, and prompt design. When a task grows too large, the model can lose track of earlier details, so future work will reward people who know how to package information cleanly. Instead of dumping everything into one giant prompt, we will increasingly break work into stages, like handing a craftsperson one tool at a time instead of an entire toolbox.
That change will reshape how teams write and review content. A marketer, analyst, or support agent who understands AI tokens can ask for the right length, the right format, and the right level of detail from the start, which saves both time and effort. In practice, that means fewer long back-and-forth corrections and more first-pass drafts that are actually useful. It also means teams can create prompt templates that repeat well, so common tasks become predictable instead of starting from scratch every time.
The same idea will reach beyond writing and into decision-making. Future workplaces will use AI not only to generate text, but also to summarize meetings, compare options, sort documents, and prepare briefings, and each of those tasks depends on how many tokens fit into the model’s working memory. That makes token management feel a little like project management: if the brief is too wide, the model loses focus; if the brief is too tight, it misses important nuance. The best results will come from people who know how to find that middle ground.
There is also a strong business reason for this shift. As more organizations use AI at scale, token counts will influence budget planning the same way cloud storage and software licenses already do. When teams understand how prompts, outputs, and reused context consume tokens, they can design workflows that are faster, cheaper, and easier to predict. That is why the future of work will not belong only to people who can ask AI questions, but to people who can ask them in ways that respect the system’s limits.
Will that make human workers less important? Not at all; it will make human judgment more valuable. Tokens can help a model process language, but they cannot decide which task matters most, which detail should stay, or whether an answer fits the situation. In other words, the model handles the counting, but you still handle the meaning. That balance is what will separate casual use from professional use, especially as AI becomes woven into more everyday tools.
We will also see new habits form around collaboration with AI. Teams will learn to build token-conscious workflows, meaning they will trim repetition, preserve only the context that matters, and split large tasks into smaller passes when needed. A manager might ask for a concise summary first, then request a deeper analysis only after the direction is clear. A developer might feed the model one module at a time instead of an entire codebase, because that keeps the model focused and reduces wasted tokens.
Over time, this will change what it means to be efficient at work. It will not be enough to produce more; we will need to produce with intention, using the right amount of context for the right result. That is the deeper promise of ChatGPT tokens and the broader token economy: they push us toward clearer thinking, cleaner communication, and more disciplined use of AI. Once we learn to work with those limits instead of against them, the future of work starts to look less like automation replacing people and more like people learning how to steer powerful tools with care.