DocDancer Overview and Goals
If you’ve ever opened a long PDF and felt like the answer was hidden somewhere in a maze of headings, tables, and side notes, you already understand the problem DocDancer is trying to solve. In the world of long-PDF RAG, the hard part is not only finding text; it is finding the right evidence, in the right order, and keeping track of how each clue connects to the question. The DocDancer paper starts from a simple frustration: existing Document Question Answering, or DocQA, agents often do not use tools well and still depend heavily on closed-source models.
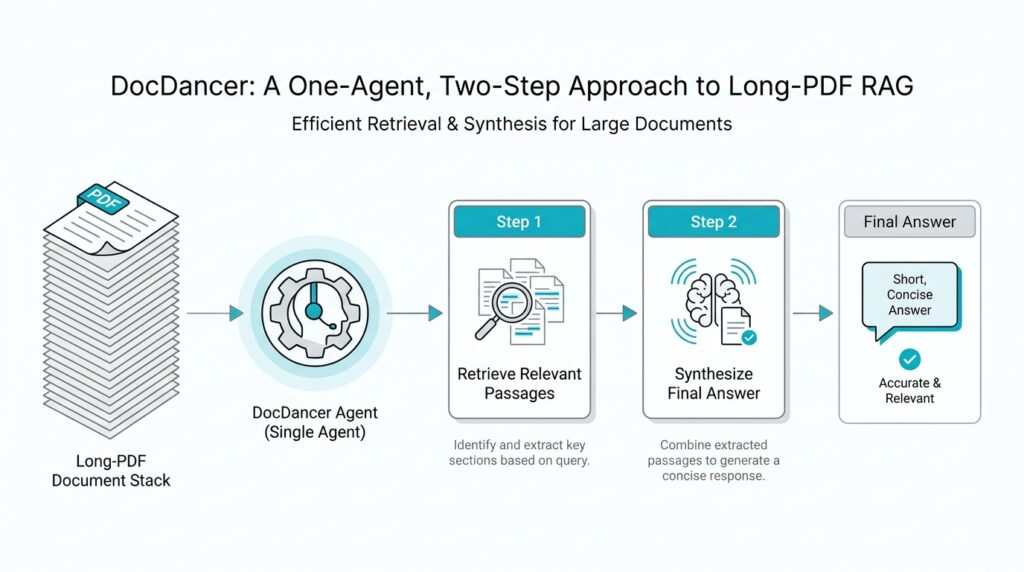
DocDancer’s core idea is to treat DocQA as an information-seeking problem rather than a one-shot lookup task. That shift matters because information seeking feels more like investigating a room than reading a flash card: you look around, notice something useful, then narrow in on what matters next. The system is described as an end-to-end trained open-source Doc agent, and its tool-driven framework is built to model both document exploration and comprehension instead of pretending those two things happen at once.
So what does the “one-agent, two-step” picture look like in practice? At a high level, we can think of the agent as first exploring the document and then synthesizing what it found into an answer, which is exactly what the paper’s Exploration-then-Synthesis pipeline is designed to support. That is an inference from the pipeline name and abstract, but it fits the system’s goal neatly: first gather the right evidence, then turn that evidence into a usable question-and-answer pair. In other words, DocDancer tries to make the agent behave like a careful reader who takes notes before speaking.
This is where the project becomes more than a clever prompt recipe. The paper says the team built the Exploration-then-Synthesis pipeline specifically to address the scarcity of high-quality training data for DocQA, which is a common bottleneck in long-PDF RAG systems. If the agent never sees good examples of how to search, read, and combine evidence, it cannot learn those habits reliably. DocDancer’s goal is therefore not just to answer questions well, but to create the kind of training signal that teaches an agent how to move through a document with purpose.
That goal becomes even clearer when you look at the kinds of documents involved. The paper evaluates trained models on two long-context document understanding benchmarks, MMLongBench-Doc and DocBench, which tells us the target is not short snippets but genuinely sprawling, information-dense files. In that setting, a long-PDF RAG system has to do more than fetch a relevant chunk; it has to connect pieces that may be spread across pages, sections, and visual elements. DocDancer is aiming for that fuller kind of reading, where the answer grows out of a trail of evidence rather than a single retrieved passage.
Seen this way, DocDancer’s bigger promise is surprisingly practical. It tries to make document-grounded answering feel less like gambling on the right chunk and more like following a disciplined reading strategy. The paper’s emphasis on tool design and synthetic data suggests a clear message: if we want long-PDF RAG to become more reliable, we need agents that know when to explore, when to pause, and when the document has finally given up enough clues to support a solid answer.
Parse PDFs Into Structured Outlines
When we start with a long PDF, the first problem is usually not finding some text. It is finding the right text in a shape the agent can actually reason over. That is why DocDancer’s PDF parsing step matters so much: it turns a flat, intimidating file into a structured outline, so the system can treat the document less like a paper dump and more like a navigable map. How do you parse PDFs into a structured outline without losing the meaning hiding in headings, tables, and figures? DocDancer answers that by making document exploration an explicit part of the workflow, not an afterthought.
The important shift is that the parser does not merely extract text line by line. In the paper summary, DocDancer’s document parsing stage uses MinerU2.5 to pull layout and semantic information into an XML outline, then clusters headings into finer sections and attaches captions for images and charts. In plain language, that means the PDF keeps its bones: sections stay grouped, visuals stay connected to their place in the story, and the agent can tell where one idea ends and the next begins. That is a very different experience from scraping raw text and hoping the model remembers what belonged together.
Once that outline exists, search becomes much more honest. Instead of scanning a giant wall of text, the agent can ask for keywords and get back section IDs, page numbers, and nearby snippets, which gives it a trail to follow instead of a single lucky chunk. In long-PDF RAG, this matters because the answer often lives across several pages, and a single retrieval hit can miss the surrounding context that makes the evidence usable. The outline works like a well-labeled hallway system: you still have to walk, but you no longer wander in circles.
The Read step builds on that same structure, and this is where the outline starts to feel alive. DocDancer’s summary describes Read as gathering text, images, tables, and even section screenshots before producing goal-relevant content, which means the agent can bring together multimodal clues instead of pretending the PDF is only prose. That is especially useful when a question depends on a chart label, a table row, or a visual caption tucked beside the main paragraph. In other words, the structured outline does not replace reading; it gives reading a path.
This is also why the parsing step fits so neatly with the paper’s Exploration-then-Synthesis pipeline. The same structure that helps the agent explore a document also helps the system generate better training examples, because each trajectory can preserve where the evidence came from and how it was gathered. DocDancer’s abstract makes clear that the project is built around document exploration, comprehension, and synthetic training data for long-context document understanding benchmarks such as MMLongBench-Doc and DocBench. So when we talk about parsing PDFs into structured outlines, we are really talking about teaching the model the first habit of good document work: notice the document’s shape before you try to answer from it.
Use Search and Read Tools
Once the PDF has been turned into a structured outline, DocDancer can start doing the part that feels most like real investigation: using search and read tools to move through the document with intent. This is where long-PDF RAG stops feeling like a blind guess and starts feeling like a guided walk through a building with labeled rooms. If you have ever wondered, “How does a long-PDF RAG agent know where to look next?” the answer is that it does not rely on one giant search box alone. It first searches for likely places, then reads those places carefully.
The search tool is the agent’s first scout. In plain language, search means asking the document outline for clues such as keywords, section IDs, page numbers, and nearby snippets, so the agent can narrow the field before it commits to reading. That matters because a long PDF often hides the answer across several pages, and a single retrieved passage can miss the context that makes the evidence useful. In DocDancer, search is not about finding a perfect final answer; it is about finding the best doorway into the document.
This is a subtle but important shift for long-PDF RAG. Traditional retrieval can feel like tossing a fishing line into a lake and hoping the right sentence bites, while DocDancer’s search behaves more like checking a map, then choosing the most promising hallway. Because the outline preserves structure, search can follow headings and sections instead of treating the file like one flat wall of text. That gives the agent a sense of direction, which is especially valuable when the question depends on a detail buried inside a specific subsection or figure caption.
Once search has pointed the way, the read tool does the closer work. Read is the step where the agent opens the chosen section and gathers the actual evidence, including text, images, tables, and even screenshots when they help explain what is on the page. That definition matters because reading in a PDF is not the same as copying prose into a text box. A table row, a chart label, or a caption can carry the key fact, and DocDancer’s read step is built to keep those pieces in play instead of flattening them away.
This is where the system starts to feel more human. We rarely answer a hard question by looking at one line and moving on; we glance, compare, return, and check the surrounding details. DocDancer’s read tool supports that same habit by letting the agent collect multimodal evidence, meaning evidence from more than one kind of content. In long-PDF RAG, that flexibility is not a luxury. It is the difference between seeing a clue and understanding why the clue matters.
The real strength of search and read tools appears when they work together as a loop. Search trims the document down to a manageable path, and read turns that path into usable evidence that the agent can reason over. That pairing is also what makes the training pipeline stronger, because the system can record how evidence was found and how it was assembled into an answer. In other words, DocDancer does not only teach the model what to answer; it teaches the model how to move through a long PDF without losing its place.
That is why this tool-driven approach is so central to the project’s promise. Search and read give the agent a rhythm: look around first, then examine closely, then decide whether enough proof is on the table. For long-PDF RAG, that rhythm is what turns scattered document fragments into a coherent reading process, and it prepares the ground for the synthesis step that follows.
Collect Multi-Hop Evidence Trajectories
Once the outline is in place and Search and Read are working, the next job is to capture the path the agent took, not only the answer it reached. That path is what we mean by an evidence trajectory: a step-by-step record of how one clue led to the next, until the document finally yielded enough support to answer the question. In DocDancer, this matters because the paper treats DocQA as an information-seeking problem and builds an Exploration-then-Synthesis pipeline specifically to train agents on that kind of behavior.
If you are wondering, “How do we collect multi-hop evidence trajectories when the answer is scattered across a long PDF?”, the answer starts with patience. We do not expect one retrieved passage to solve everything; instead, we let the agent move from one piece of evidence to another, with each hop adding a little more certainty. A hop can be a search result that points to a section ID, a read action that opens that section, or a follow-up check against a table, figure, or screenshot when the first clue is not enough. The important part is that the chain stays visible, so we can later see not only what the agent used, but why it chose the next step.
That visibility is what turns a loose collection of snippets into useful training data. In a long-PDF RAG setting, evidence often lives in different places and different forms, so the trajectory needs to preserve provenance, or source history, for every clue. A good trajectory keeps the question, the intermediate search terms, the retrieved sections, and the final supporting passages tied together like beads on a string. DocDancer’s tool-driven design supports this because the system is built around document exploration and comprehension rather than a single-pass retrieval answer.
The collection process itself feels a bit like watching a careful reader work out loud. First we present a question, then the agent searches for likely entry points, reads the most promising section, and asks a new question based on what it just found. If that second clue points to another page, a table row, or a caption, the agent follows it, and we log the whole sequence as a multi-hop evidence trajectory. This is where the “multi-hop” part earns its name: the answer is not built from one leap, but from several smaller crossings between related clues.
DocDancer’s design choices also suggest why these trajectories need to stay clean and compact. The paper reports that, for tool usage, its simpler Search-and-Read setup performs better than a heavier baseline with more tools, and that stronger outline construction improves results as well. That combination hints at an important lesson for data collection: cleaner document structure makes it easier to record cleaner reasoning paths, and cleaner reasoning paths make it easier for the model to learn when one piece of evidence is enough and when another hop is still needed.
So the real goal is not to hoard snippets. It is to capture a believable route through the document, one that shows how a question about a long PDF becomes a sequence of grounded choices, each choice narrowing the search until the evidence finally lines up. That is what gives long-PDF RAG its discipline: the model learns to move like a reader who checks, confirms, and connects, instead of a system that grabs the first sentence that looks close enough.
Generate Synthetic QA Pairs
Now that we have a trail of evidence, the next move is to turn that trail into synthetic QA pairs—paired examples of a question and its answer that the model can learn from. This is where DocDancer shifts from collecting proof to shaping training data, and that matters because long-PDF RAG systems usually do not suffer from a lack of documents; they suffer from a lack of clean examples. If you have ever asked, “How do we train a model to answer questions from a huge PDF when human annotations are scarce?”, this is the part where the paper starts to feel especially practical.
The basic idea is wonderfully human, even if the machinery behind it is technical. We read the evidence trajectory like a note-taking assistant would, then we ask what question that evidence could honestly answer. In other words, the system does not invent facts first and hunt for support later; it starts with grounded passages, tables, images, or screenshots, and only then drafts a question that matches them. That ordering is important because it keeps the long-PDF RAG pipeline tied to the document instead of drifting into vague, unsupported examples.
A synthetic QA pair is useful only if the answer can be traced back to the evidence path that produced it. So DocDancer’s synthesis step has to preserve the relationship between the question, the supporting clues, and the final answer, much like a good teacher writing both the problem and the worked solution on the board. The question should sound natural, the answer should stay concise, and the supporting context should come from the exact document trail the agent followed. When those pieces line up, the pair becomes more than a flashcard; it becomes a training example that teaches the model how to think with the document.
This is also where multi-hop reasoning earns its keep. Some synthetic QA pairs can be answered from one section, but the more interesting ones force the model to combine clues across pages, headings, or visual elements, just as we saw in the evidence-collection stage. DocDancer can use those multi-hop trajectories to generate questions that require a little back-and-forth between clues, which is exactly the kind of behavior long-PDF RAG systems need to learn. Instead of rewarding the first sentence that looks close enough, the dataset nudges the model toward careful, document-grounded reasoning.
The payoff is data quality, not data volume for its own sake. Manual annotation for DocQA is slow, expensive, and hard to scale across sprawling PDFs, so synthetic QA pairs give the system a way to grow a training set without losing structure. Because the questions and answers come from real exploration paths, they are more likely to reflect how a reader actually works through a complex file: find a clue, verify it, connect it, and then speak. That makes the resulting supervision feel less like noise and more like a memory of good reading habits.
DocDancer’s approach also helps explain why synthetic QA generation is not the same as careless text rewriting. The model is not asked to paraphrase random passages into fake questions; it is guided by the evidence trajectory, which gives every example a reason to exist. That is a subtle but powerful distinction, because it keeps the training signal aligned with the same exploration-then-synthesis rhythm that powers the rest of the system. In long-PDF RAG, that alignment is what helps the agent learn not only what an answer looks like, but how to earn it.
And that is the real point of generating synthetic QA pairs here: we are building a bridge between document exploration and answer writing. The exploration step finds the path, the synthesis step turns that path into a usable question-answer example, and the model later learns to follow the same pattern on new PDFs it has never seen before. In the next stage, that stored experience becomes the raw material for training a stronger document agent that can read with more discipline and answer with more confidence.
Train and Evaluate the Agent
Once the synthetic QA pairs are ready, the project reaches its most delicate moment: teaching the agent to behave like a careful reader instead of a lucky guesser. In DocDancer, training is the process of showing the model many document-grounded examples so it can learn the rhythm of long-PDF RAG: search for clues, read the right evidence, and then write an answer that stays faithful to the document. That matters because a document question answering, or DocQA, system is only as useful as the habits it can repeat when the PDF is messy, long, and full of distractions.
The training loop starts with the examples we built from evidence trajectories, and that gives the model more than a question and answer. It also sees the trail that led there, which helps it learn which actions are worth taking and which ones waste time. Fine-tuning, which means continuing to train a model on task-specific examples, nudges the agent toward those habits so it does not rely on generic language skills alone. In practice, this is how long-PDF RAG begins to feel less like pattern matching and more like guided investigation.
What makes this especially important is that the agent is not learning a single trick. It is learning a sequence of decisions, and each decision has to make sense in context. If the search step points to the wrong section, the read step becomes noisy; if the read step misses a table or figure, the final synthesis can drift away from the evidence. When you ask, “How does a long-PDF RAG agent actually get better?” the answer is that it practices this full chain until the sequence starts to feel natural.
Evaluation is where we check whether that practice paid off. DocDancer tests trained models on MMLongBench-Doc and DocBench, two long-context benchmarks for document understanding, so the agent has to prove itself on genuinely sprawling files rather than short, tidy passages. That kind of testing matters because a strong result on a small excerpt does not tell us whether the model can survive a dense PDF with tables, section breaks, and visual clues scattered across pages. Here, the evaluation is not only about getting the right answer; it is about getting there by reading the document well.
That is also why the paper’s comparisons are so revealing. The simpler Search-and-Read setup performs better than a heavier tool arrangement, which suggests that cleaner tool use can be easier for the agent to learn and easier for the system to trust. In the same spirit, stronger outline construction improves results, showing that the quality of the document structure affects both training and evaluation. These findings reinforce a practical lesson for long-PDF RAG: the agent does better when the path through the document is clear enough to follow.
For us, the useful takeaway is that evaluation should look beyond a single score and ask whether the model is grounded in evidence. Did it find the right section? Did it use the table, image, or caption when the question needed them? Did it answer with the same trail of support that a human reader would use? Those questions matter because they tell us whether the agent has learned a stable reading strategy or only a surface-level shortcut.
Seen from that angle, training and evaluation become two halves of the same story. Training gives the agent its reading habits, and evaluation checks whether those habits still hold when the document gets long, noisy, and unfamiliar. That is what makes DocDancer’s open-source agent promising: it is not only built to answer questions, but to earn those answers through a repeatable, document-grounded process that can stand up under real long-PDF RAG pressure.