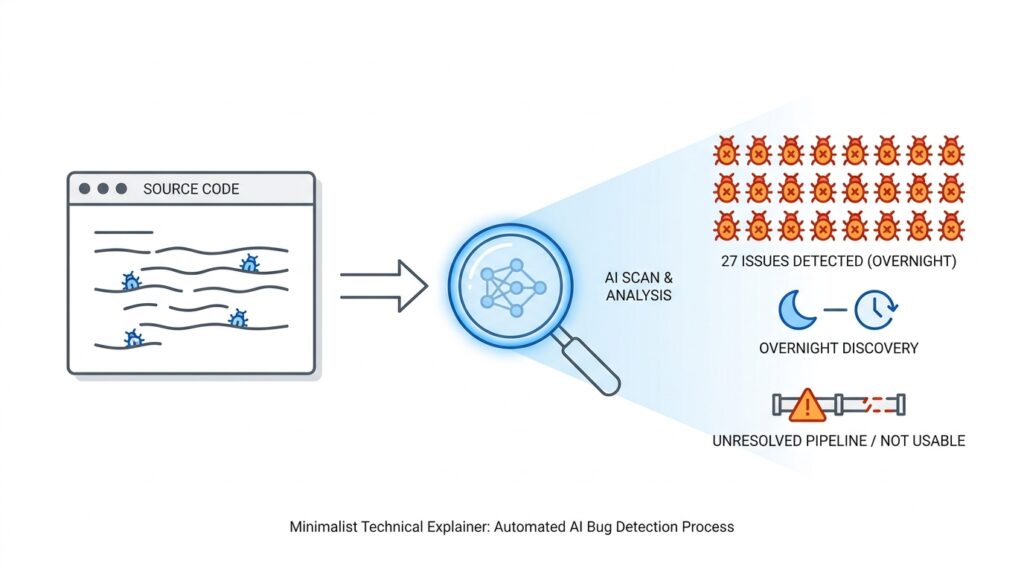
Why Legacy Code Hides Bugs
What makes a bug disappear into old software and stay there for years? In legacy code, the answer is usually not that the bug is tiny; it is that the surrounding code gives us very few good places to look. Michael Feathers’ classic definition treats legacy code as code without automated tests, and Martin Fowler notes that hard-to-test parts of a system are exactly where bugs can quietly live because we cannot exercise them with confidence. When a system has no reliable test harness, the code may keep working well enough to ship, while the faulty path remains invisible until one rare input wakes it up.
Another reason legacy code hides bugs is that time erases the map. Older systems often carry inconsistent documentation, missing design notes, and assumptions that once lived in a developer’s head but never made it into the source itself. The Carnegie Mellon Software Engineering Institute has long described legacy code as difficult to understand for exactly these reasons, which means the code may be running inside a fog: you can see the outputs, but not the full logic that produced them. That is why a bug can sit untouched for years—no one is looking at the right corner, and no one is fully sure what “the right corner” even is anymore.
Legacy code also hides bugs by tying too many things together. When one function reaches into another, and that one reaches into a database, a file, and a network call, we lose the ability to isolate a single behavior and observe it cleanly. Fowler’s idea of a seam—a place where behavior can change without editing the code at that point—shows why this matters: without seams, we cannot easily separate one small idea from the rest of the machine. The result is a system where a bug may appear to be in one line, but the real cause sits three layers away, buried under dependency after dependency.
Technical debt makes that hiding place even deeper. The SEI describes technical debt as a short-term shortcut that increases long-term complexity and cost, and it also notes that growing complexity creates more opportunities for vulnerabilities. In practice, that means old code often accumulates workarounds, special cases, and duplicated logic until a bug can slip through a side door nobody remembers adding. Static analysis tools can catch some issues, such as unnecessary complexity or duplicated code, but many defects still require deeper inspection because the problem is not a single broken line; it is the shape of the whole system.
So when we ask, “Why do bugs hide in legacy code?”, the honest answer is that old systems often remove the very things that make bugs visible: tests, documentation, clean boundaries, and fresh context. That is also why AI can uncover surprising defects overnight and still leave the system hard to trust; finding a bug is not the same as proving the rest of the code is safe. In a strong testing culture, the response to a bug is to write a test that exposes it and then fix the code, because the test becomes a permanent flashlight for that exact failure mode. Without that flashlight, we are left guessing in the dark, which is precisely where legacy code is most comfortable hiding its surprises.
How AI Finds Hidden Flaws
Now that we have seen why old code can hide so well, the next question is how AI bug detection actually shines a light into that fog. The trick is that these systems do not read a codebase the way a person skims a page; they turn it into something they can search, compare, and trace. CodeQL, for example, treats code like data and builds a relational database from the project before running queries over it, while recent research on large language models shows that step-by-step prompting can help models reason about security flaws more effectively than a single quick glance.
A useful way to picture this is to imagine a plumbing system. AI often looks for places where water enters the pipes, where it leaves them, and whether it takes a dangerous route in between. In security work, those entry points and danger points are called a source and a sink, and many vulnerabilities happen when ordinary-looking data flows from one to the other without enough cleaning or checking. CodeQL path queries are built for exactly this kind of data-flow tracing, so the tool can follow the path of a variable through the code instead of staring at one line in isolation.
That is where hidden flaws start to surface. Once the system spots one bug pattern, it can look for its cousins across the rest of the codebase, which is called variant analysis, meaning the search for logical siblings of a known vulnerability. GitHub’s CodeQL documentation describes this as using a known flaw as a seed and then expanding outward to find similar problems in one repository or many repositories at once. In practice, this is one reason AI can uncover old bugs overnight: it does not need to discover every flaw from scratch if it can recognize that today’s strange corner case looks a lot like yesterday’s mistake.
AI also gets help from techniques that behave more like explorers than readers. Fuzzing is a testing method that throws many different inputs at a program to see what breaks, while symbolic execution is a technique that treats input values as symbols and reasons about the conditions needed to reach a path. Research on hybrid testing shows that combining the two can uncover subtle errors and vulnerabilities, because fuzzing reaches broad ground quickly and symbolic execution helps push into deeper paths that random tests might miss. Another classic bug-finding system found that symbolic execution alone can run into path explosion, which is why pairing it with fuzzing makes the search more practical.
Still, this is where the breakthrough starts to look less magical and more like a very smart triage assistant. The best studies on LLM-based vulnerability detection describe only modest overall effectiveness, with better performance on simpler intra-procedural issues, meaning flaws that stay mostly inside one function or routine. The same research also found that prompting models to reason step by step improves results, and that models can sometimes recognize useful clues such as sources, sinks, and whether code appears sanitized. So when AI finds hidden flaws, it is usually not proving the whole system safe; it is narrowing a massive haystack into a much sharper set of needles for humans to inspect next.
Why Overnight Wins Matter
When AI surfaces a 27-year-old bug before the coffee cools, the important part is not the drama; it is the proof. One overnight win tells us the codebase is not a black box anymore, because tools like CodeQL model code as data and trace a path from a source to a sink, which is a practical way to follow a bad value through the system. If you have ever asked, “How can AI find hidden bugs so fast?”, this is the answer: it narrows the maze to one visible corridor.
That matters because hidden bugs are only useful when we can act on them. CodeQL’s variant analysis is built around reusing one known flaw as a seed and searching for similar ones elsewhere, so one find can become many findings instead of one lonely alert. In practice, an overnight win gives us a starting point for review, a pattern for a new query, and a concrete place to add a regression test so the same mistake does not return.
Overnight wins also matter because they keep people engaged. A vague warning can feel like background noise, but a bug you can reproduce becomes a story the team can follow: where the data entered, where it traveled, and why it slipped through. Static-analysis research has long noted that violations are often signs of defects and that tracking them over time helps teams see what got introduced and what got fixed, which is why a single strong finding can improve the whole conversation around AI bug detection.
The catch is that overnight wins still are not the same as usable automation. Studies of large language models on vulnerability detection found that step-by-step reasoning improves results, but overall performance remains modest and is stronger on simpler, mostly single-function problems. That means AI can point at the fire alarm, but it cannot yet promise the building is safe.
This is also why the older testing tools still matter. Fuzzing, which hammers a program with many inputs, and symbolic execution, which reasons about inputs as symbols, each solve part of the puzzle, but symbolic execution runs into path explosion, where the number of paths grows too fast to manage. Hybrid systems like QSYM combine the two because fuzzing reaches broadly while symbolic reasoning helps push deeper, and that balance is a good model for how we should treat overnight AI wins: as a fast scout, not the final judge.
So the breakthrough matters because it changes our posture toward legacy code. Instead of waiting for certainty, we get a real defect, a real path, and a real next step, which is enough to move from speculation to action. The win is overnight, but the payoff is slower and more durable: it teaches us where the code breaks, where to look next, and where human review still has to take over.
Where AI Still Fails
What still fails is not raw speed; it is fit. The tools can race through a codebase, but they work best when the problem can be translated into a model with a source, a sink, and a known path between them. CodeQL’s path queries are built exactly that way, and GitHub’s variant-analysis flow can run them across up to 1,000 repositories; the catch is that the tool still depends on the boundaries we draw for it. In practice, that means AI bug detection is strongest when the flaw looks like a pattern we already know how to name, and weaker when the bug lives outside the map we provided.
So where does AI bug detection still fall short? The clearest answer is in deeper reasoning. A recent study of 16 large language models found modest overall vulnerability-detection performance, with better results on intra-procedural issues like null-pointer dereferences and command-injection bugs. The same study found that step-by-step prompting improved F1 score by up to 0.18 on real-world datasets, which is encouraging but also a reminder that the models still need careful guidance to reach that level. In other words, they are improving at spotting clues, but not yet reliable enough to be trusted as independent reviewers of messy legacy code.
The harder the bug stretches across the system, the more the illusion breaks. Fuzzing, which bombards a program with many test inputs, and symbolic execution, which reasons about inputs as symbols, each cover a different weakness, but a survey of hybrid testing still notes that path-explosion remains a practical obstacle even after years of mitigation. That is why these methods are often paired: fuzzing can widen the search quickly, while symbolic execution can push into deeper corners, yet neither one can promise full coverage of a complicated codebase. AI feels powerful here because it can scout fast, but the underlying search problem still refuses to become small.
There is also a quieter failure that matters in real teams: alerts are not the same as answers. Static-analysis warnings are described as indications of defects, not proof of defects, and tracking them across revisions takes care because the same issue can move, change shape, or reappear in a slightly different place. That is the moment where AI bug detection still needs a person in the loop, because someone has to decide whether the finding is a real bug, a duplicate, or a symptom of some larger design problem. If we skip that judgment, we risk turning a useful flashlight into a pile of noisy beeps.
That is why the breakthrough is real but limited. AI can pull one hidden flaw into the light overnight, and that can be a huge win for legacy code, but it still fails at the work that makes the win durable: proving scope, separating signal from noise, and turning a one-off discovery into a test the team can trust. The practical lesson is humble and useful: let the tool search, let humans decide, and let the new test carry the lesson forward. That division of labor is what makes the result feel less like magic and more like progress.
Human Review Still Required
After the overnight alert lands, the temptation is to treat it like a solved mystery. But AI bug detection is only the opening move: code-scanning tools usually surface a highlighted line, a traced path, and a reason to look closer, and GitHub’s workflow expects you to review that alert before you dismiss or resolve it. That matters because the tool is not vouching for truth; it is pointing to a suspicious shape in the code, and human review decides whether the shape is dangerous, duplicated, or harmless in context.
That is not a weakness unique to AI. NIST has long treated static-analysis warnings as inputs for human analysis, not as final answers, because a warning can reflect anything from a real weakness to an insignificant inconsistency. In other words, the scanner is a metal detector, and the reviewer is the person who decides whether the beep came from a coin or a nail. In older systems, that judgment matters even more, because the surrounding context often decides whether an alert is meaningful.
CodeQL helps by treating code like data and tracing a path from a source to a sink, which is a powerful way to expose data-flow bugs. It can also run variant analysis, where one known flaw becomes a seed for searching similar patterns elsewhere. That is why AI can find something that has slept for 27 years overnight—but the result is still a candidate, not a verdict, because a path in a query is not the same thing as a proven exploit in a running system.
How do you know whether the alert is real? You verify the exact input, follow the surrounding code, and ask whether the dangerous path is actually reachable under the program’s rules. Hybrid testing helps here: fuzzing throws many inputs at the program, while symbolic execution reasons about inputs as symbols, but research still notes path explosion as a practical limit for pure symbolic reasoning. That is why these techniques find promising leads, not final answers; they make human review faster, sharper, and less guessy.
So the useful output of AI bug detection is not the alert itself; it is the handoff to a person who can confirm impact, dismiss noise, and decide whether the finding deserves a fix. GitHub’s code-scanning flow centers that workflow by letting reviewers inspect the alert, read the guidance, and dismiss it with a reason when the evidence does not hold up. In practice, that is the moment where human review turns a fast scan into a trustworthy security decision, and where the overnight breakthrough becomes the start of the next investigation.
Practical Use Cases Today
If you’re asking, “What does AI bug detection actually do for me today?”, the honest answer is that it works best as a fast first pass over code that already feels overwhelming. In practice, CodeQL—the query engine GitHub uses for code scanning—treats code as data, which lets it search for patterns instead of reading every file like a person would. That makes it especially useful for variant analysis, where one known bug becomes a template for finding its logical cousins across the rest of the codebase.
The most immediate use case is triage inside a normal development workflow. When code scanning raises an alert, the team reviews the finding, decides whether it is real, fixes it or dismisses it, and can add a reason so the choice is recorded for later. GitHub also notes that alerts can differ by branch, and dismissed alerts can be reopened if the team later decides they do need a fix, which makes the process feel less like a one-way gate and more like a running conversation about risk.
A second practical use is sweeping across many related repositories instead of hunting one project at a time. With multi-repository variant analysis, you can run a CodeQL query across up to 1,000 repositories from Visual Studio Code, using a controller repository to coordinate the run. That matters when a shared library, product family, or old fork network may contain the same weakness in dozens of places, because one confirmed flaw can become a search pattern for the whole fleet.
A third use case is patch drafting, not patch finalization. GitHub Copilot Autofix for code scanning gives targeted recommendations for CodeQL alerts, and GitHub says those suggestions are generated automatically by large language models using the codebase and code scanning analysis. The feature is explicitly best-effort, though, so it can support a fix review rather than replace it; that makes it useful when you want a plausible starting patch without asking a human to write every repair from scratch.
The fourth use case is the one that feels most powerful in legacy systems: using AI findings to steer deeper testing. Hybrid testing combines fuzzing, which throws many inputs at a program, with symbolic execution, which reasons about inputs as symbols; the research literature says fuzzing can miss deep paths, while symbolic execution by itself runs into path explosion. In that setting, AI is not the final judge. It becomes a scout that helps narrow the search, especially because recent LLM studies found only modest overall vulnerability-detection performance, even though step-by-step prompting improved F1 score by up to 0.18 and the models did better on simpler intra-procedural issues like command injection and null-pointer dereferences.
So the practical use today is narrow, but real: let AI bug detection scan the haystack, let CodeQL turn suspicious paths into concrete alerts, let Copilot Autofix draft candidate repairs, and let humans decide what the findings actually mean. That is the sweet spot right now, and it is why the overnight breakthrough matters even before full automation arrives.