Query Building Blocks
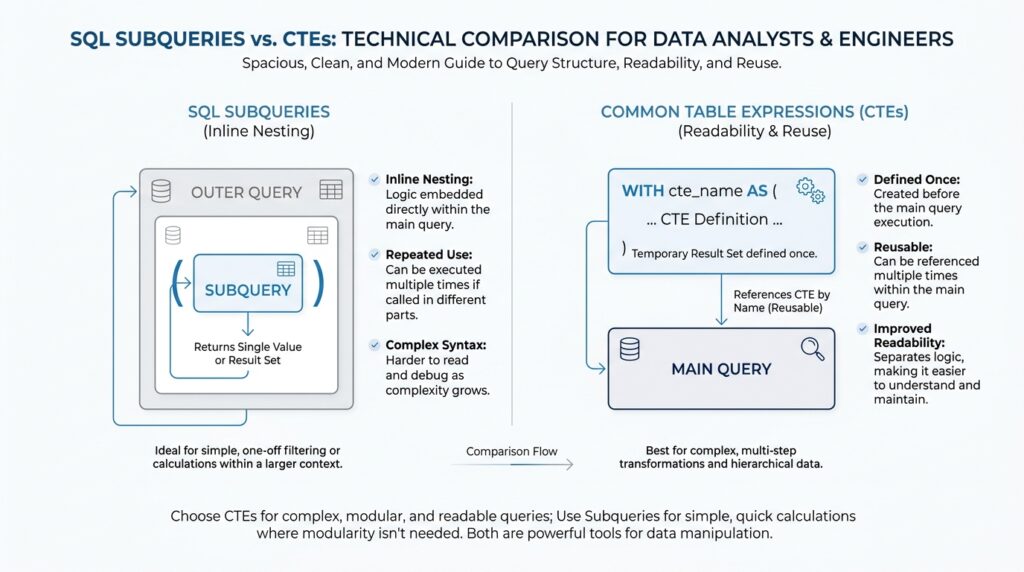
When you first step into a SQL query, it can feel a little like opening a toolbox and seeing a dozen small pieces that all claim to be useful. Subqueries and CTEs, or common table expressions, are two of the most important building blocks because they let us break a big problem into smaller, readable parts. A subquery is a query nested inside another query, while a CTE is a named intermediate result defined with WITH and used within the same SQL statement.
That difference matters because it changes how we think while we write. A subquery often feels like a tucked-away helper: it solves one small question so the outer query can keep moving. In practice, subqueries show up in places like WHERE, HAVING, SELECT, and FROM, and they are especially handy when you want to compare rows one at a time or filter based on another result set.
A CTE feels more like putting a sticky note on a step in the middle of your thought process. Instead of hiding the logic inside another clause, you give the intermediate result a name and let the rest of the query refer to it. PostgreSQL describes CTEs as a way to write subqueries for a larger query, and Microsoft’s documentation describes them as temporary result sets that can be reused within the scope of a statement. That reuse is the part many beginners appreciate first, because it turns a long, nested query into something closer to a story you can read from top to bottom.
So how do you decide which building block to reach for first? A good rule of thumb is to ask whether you want a quick, one-off answer or a named step that makes the whole query easier to follow. If you only need the result once, a subquery can keep the logic compact. If you want to reuse an intermediate result, or you want the query to read like a sequence of plain-language steps, a CTE often makes the path clearer.
Here is the part that surprises many people: a CTE is not always a physical temporary table sitting somewhere on disk. PostgreSQL notes that some WITH queries can be executed inline when they are nonrecursive and have no side effects, which means the database may fold them into the larger query instead of storing them separately. That is why CTEs are best thought of as an organizational tool first and a performance tool second.
This is also where the shape of the query starts to matter. Subqueries can feel like nested boxes, where each layer depends on the one inside it. CTEs, on the other hand, can act like labeled stations on a route: first we calculate one result, then we build on it, then we finish with the final output. PostgreSQL even shows this by using a CTE to break a complex sales query into smaller named pieces instead of piling on deeper nesting.
There is one more gentle lesson hidden in this comparison. The best query building blocks are the ones that help the next person understand your intent without having to reverse-engineer your logic. That next person might be your teammate, your future self, or both. When we choose between SQL subqueries vs CTEs with readability, reuse, and scope in mind, we make the query easier to reason about before we ever think about tuning it.
Subquery Patterns
Once we move from the idea of subqueries into the real work of writing them, the shapes start to repeat. You’ll usually see SQL subqueries doing one of three jobs: checking whether a value belongs in a set, asking whether related rows exist, or pulling a single result into a larger calculation. In PostgreSQL and SQL Server, those patterns show up most often in IN, comparison operators, EXISTS, and sub-SELECT statements in FROM, so learning the shapes helps you read the query before you even run it.
The first pattern feels like a bouncer at the door: we ask whether a value belongs to a list returned by another query. IN is the natural fit when you want to match against one returned column, and PostgreSQL notes that it returns true when it finds a matching row. If you are thinking, “Should I use EXISTS or IN here?”, the practical question is whether you care about the matching values themselves or only whether any match exists. EXISTS is built for that yes-or-no test, and SQL Server documents it as an existence check that returns TRUE or FALSE instead of data.
The second pattern is the correlated subquery, and this is where the query starts feeling personal to each row. A correlated subquery depends on a value from the outer query, so SQL Server explains that it runs repeatedly, once for each row being considered. That makes it useful when your question changes with the row in front of you, like finding whether each employee has a matching bonus record, or whether each product belongs to a specific related group. It is a little like checking a travel pass at every station instead of once at the start.
The third pattern is the single-value lookup, where the subquery feeds one answer into a comparison. SQL Server says a subquery used with an unmodified comparison operator, such as =, >, or <, must return a single value, and it often pairs that pattern with an aggregate like AVG or MIN. That is why queries such as “find rows above the average” feel so natural with subqueries: the inner query produces one number, and the outer query compares every row against it. The catch is important for beginners: if the inner query returns more than one value, the comparison stops making sense.
The fourth pattern lives in the FROM clause, where a sub-SELECT acts like a temporary table for one SELECT command. PostgreSQL says this form must be wrapped in parentheses and given an alias, because the outer query needs a name for the virtual table it is reading from. This pattern is especially helpful when you want to shape the data first and filter or join it afterward, instead of burying the logic inside a deeper WHERE clause. It is one of the clearest examples of how SQL subqueries vs CTEs can overlap in purpose: both can stage an intermediate result, but the subquery keeps the step local to one clause.
As you practice these subquery patterns, a simple habit makes the choices easier: ask what the inner query is really returning. If it returns a list, reach for IN or a comparison with ANY or ALL; if it returns a yes-or-no answer, EXISTS is usually the cleaner move; if it returns one value, a scalar comparison can work well; and if it needs to behave like a small table, a subquery in FROM gives you that shape. Once we see those patterns clearly, the decision between SQL subqueries vs CTEs feels less like guesswork and more like choosing the right container for the same idea.
CTE Fundamentals
When you first meet a CTE, or common table expression, it often feels like someone has handed you a clean notebook page in the middle of a messy SQL problem. We have already seen how subqueries can hide a useful answer inside another clause, but CTEs change the mood of the query: they give that intermediate answer a name and a place to live for the rest of the statement. If you have ever wondered, “What is a CTE in SQL and why do people reach for it so often?”, the short answer is that it helps you turn tangled logic into a sequence of readable steps.
A CTE begins with the WITH keyword, which acts like a doorway before the main query starts. Inside that doorway, you define a temporary result set, meaning a result that exists only while that one SQL statement runs. The important part is the name: once you label the result, you can refer to it later in the same query as if it were a small table. That naming step is what makes SQL CTEs feel so friendly, because we no longer have to mentally unpack nested parentheses just to understand what the query is doing.
The real strength of CTEs shows up when a problem has more than one logical step. Imagine you are sorting through sales data and first need to calculate totals, then rank customers, and then filter to the top group. A CTE lets us write those moves in the same order we think about them, almost like placing stepping stones across a stream. Instead of asking the reader to jump straight to the end result, we guide them through each intermediate result, which is why CTE fundamentals matter so much for readability.
This is also where CTEs differ from subqueries in a practical way. A subquery often lives inside one clause and stays hidden there, but a CTE sits at the front of the statement and announces its purpose before the rest of the work begins. That front-loaded structure makes SQL CTEs especially useful when you want to reuse the same intermediate result more than once in a query, or when you want the query to read like a small story with a beginning, middle, and end. In other words, the database may not care about the drama, but the human reading your SQL definitely will.
It helps to think of a CTE like a labeled bowl on a kitchen counter. You mix one ingredient, put it in the bowl, label it, and then use it in the next step instead of measuring it again. That analogy is useful because it captures the two most important habits behind CTE fundamentals: first, we isolate one meaningful step; second, we give that step a name that the rest of the query can trust. A lot of beginners search for a huge performance trick here, but the first win is usually clarity, not speed.
CTEs can also chain together, which means one CTE can build on another CTE in the same WITH block. That makes them feel like a little assembly line: the first station prepares the raw material, the next station shapes it, and the final query assembles the output. This pattern is especially helpful when you are working through SQL subqueries vs CTEs in a real project, because the CTE version often exposes the reasoning more cleanly than a deeply nested alternative. Once you see that flow, the query becomes easier to debug, easier to explain, and easier to change later.
The key idea to carry forward is that a CTE is not magical storage and it is not a permanent object in your database. It is a named, temporary step that exists inside one statement, which makes it a perfect tool for breaking a complicated request into manageable pieces. When we understand that, SQL CTEs stop feeling like advanced syntax and start feeling like a simple, dependable way to organize our thinking. And once that foundation is comfortable, we can move on to the situations where CTEs shine most clearly in real query design.
Correlation and Scope
Now that we have the pieces on the table, the next question is the one that trips people up: what happens when a subquery needs to look outside itself? That is where correlation enters the story. A correlated subquery is a nested SELECT that depends on values from the outer query, so it changes its answer row by row instead of running as one self-contained check. A CTE, by contrast, is a named result that belongs to the whole statement, which means it gives us structure but not row-by-row awareness.
You can picture a correlated subquery as a question that gets asked separately for every row the outer query touches. That is why it feels so personal: each employee, order, or product brings its own context, and the inner query borrows that context to decide what to return. SQL Server’s documentation shows this clearly by noting that a correlated subquery depends on the outer query’s values and cannot be evaluated independently. In practice, that makes correlated subqueries a strong fit when we need a row-specific answer rather than a shared lookup.
Scope is the quieter half of the same story, but it matters just as much. A CTE lives only inside the statement that defines it, which is why PostgreSQL describes WITH queries as temporary tables for one query and shows them as named steps inside the larger statement. That means we can give an intermediate result a clear name, reuse it later in the same query, and keep our logic readable without turning it into a maze of nested parentheses. The CTE is visible where we define it, and nowhere else.
This difference explains why SQL subqueries vs CTEs can feel so different even when they produce the same rows. A correlated subquery is narrow in scope but wide in context, because it can reach outward to the current row. A CTE is wider in scope inside the statement, because later parts of the query can refer to it by name, yet it does not automatically inherit the current row’s values. If you are asking, “Can a CTE change its answer for each outer row?”, the practical answer is no; that row-by-row behavior belongs to correlation, not to a named CTE step.
There is also a small performance-shaped lesson hiding here. PostgreSQL notes that WITH queries are normally evaluated only once per execution of the parent query, even when the parent references them more than once, although the optimizer may inline some nonrecursive cases. That makes a CTE feel like a shared preparation step: we compute it, name it, and then reuse it without rewriting the logic. A correlated subquery works differently because its meaning shifts with each outer row, so it is doing a different kind of work altogether.
When we put correlation and scope side by side, the choice becomes easier to feel in our hands. If the inner query needs to react to each row from the outside, correlation is the right lens. If the query needs a named intermediate result that the rest of the statement can read from, a CTE gives us that room to breathe. So the real habit to build is this: ask whether the inner logic belongs to one row, or to the whole statement, and the shape usually reveals itself.
Performance Tradeoffs
The moment a query works but starts to drag, we stop asking whether the syntax is legal and start asking how the engine actually runs it. That is where SQL subqueries vs CTEs become a performance question, because the same logic can be folded, repeated, or staged depending on the database planner. In other words, the shape you write is only half the story; the execution plan tells us whether the database treats it like one piece of work or several.
A CTE, or common table expression, is a temporary named result set. SQL Server docs say CTE results are not materialized, meaning they are not stored as a separate intermediate table, so each outer reference re-executes the definition. PostgreSQL is more flexible: a side-effect-free WITH can be folded into the main query and optimized jointly when it is used once. That means a CTE is often an organization tool first, and only sometimes a performance lever.
This is why a single-use CTE often performs like a subquery in FROM. PostgreSQL explicitly notes that folding can happen by default, and SQL Server treats the CTE as part of one statement rather than as a stored object. If the optimizer can see through the wrapper, it can combine filters, joins, and aggregates more freely, which is the best-case outcome for both subqueries and CTEs.
The tradeoff sharpens when we reuse the same intermediate result. SQL Server warns that multiple references to a CTE can trigger repeated execution, and PostgreSQL says a folded WITH used more than once can duplicate computations; for queries that need several references, SQL Server’s docs even suggest considering a temporary object instead. That is the point where a CTE becomes a convenience with a cost, especially if the inner query does expensive joins or aggregations.
Correlated subqueries bring a different cost profile, because they are row-aware: the inner query depends on values from the outer row, so the database has to revisit the logic as each row changes. Microsoft’s training material frames correlated subqueries as the tool for row-by-row comparisons, which is exactly why they feel natural but can get expensive on large result sets. When that pattern grows wide, the repeated work becomes easier to notice in the plan.
So, are CTEs faster than subqueries? Not by default. The real win comes from matching the shape to the work: one-off logic that the optimizer can inline, repeated logic that should be computed once, or row-specific logic that truly needs correlation. When the same expensive step is reused, we should think about temporary tables or other staging objects; when the step is only a bridge to the final result, the cleanest form is often fast enough and easier to maintain.
The practical habit is to read the execution plan, not the rumor. Microsoft’s query performance guidance emphasizes estimated and actual plans, and that is the fastest way to see whether SQL subqueries vs CTEs are doing one efficient pass or quietly retracing the same path. Once we can spot repeated scans, repeated joins, and repeated aggregation, the performance tradeoff stops feeling mysterious and starts feeling like a choice we can make with confidence.
Practical Use Cases
When we get past the syntax and into real work, SQL subqueries vs CTEs start to feel less like abstract options and more like different tools for different moments. A subquery often helps when you need one focused answer to feed another question, while a CTE, or common table expression, works well when you want to name an intermediate step and let the rest of the statement read like a path instead of a maze. So when should you use a subquery instead of a CTE? The practical answer is: use the shape that matches the job in front of you.
Subqueries shine when the question is small, specific, and tightly attached to another clause. PostgreSQL’s documentation shows that IN is a natural fit when you are checking whether a value appears in a one-column result, and EXISTS is the clean choice when you only care whether any matching row exists at all. Microsoft’s training path also frames subqueries as either scalar, meaning one value, or multi-valued, and as either self-contained or correlated, which makes them useful for row-by-row checks and compact filters. In practice, that means SQL subqueries are often the right move for “show me rows above the average,” “keep only customers with orders,” or any question where the inner result acts like a small yes-or-no gate.
A CTE becomes more helpful when the work has a few clear stages and you want to guide the reader through them. SQL Server describes a CTE as a temporary named result set inside one statement, and PostgreSQL describes WITH queries as auxiliary statements that act like temporary tables for a single query. That makes CTEs a natural fit for report-style logic, where you might calculate a base metric first, then rank it, and then filter the ranked result. The story here is not about hiding complexity; it is about giving each step a name so the next step can build on it without making you untangle nested parentheses.
This is also where CTEs earn their keep in analytical work that needs reuse inside one statement. If you compute a cleaned or enriched dataset once and then refer to it several times later in the same query, a CTE gives that intermediate result a place to live. That is why SQL analysts often reach for CTEs in dashboard queries, cohort breakdowns, and multi-stage transformations: the logic reads in the same order you think about it. In SQL subqueries vs CTEs, this is one of the clearest dividing lines, because a CTE makes the intermediate shape visible at the top of the query instead of burying it inside a clause.
Recursive CTEs deserve their own spotlight because they solve a very specific kind of problem: data that branches. PostgreSQL notes that recursive queries are typically used for hierarchical or tree-structured data, such as parts lists or parent-child relationships, and SQL Server’s documentation likewise supports recursive CTEs with an anchor member and a recursive member. If you have ever needed to walk an org chart, a folder tree, or a bill of materials, this is the moment when a CTE stops being a convenience and becomes the clearest expression of the task. The query begins with the root, then keeps expanding outward until there is nothing left to add.
CTEs also show up in practical data-moving work, not only in reporting. PostgreSQL documents that WITH can include INSERT, UPDATE, DELETE, or MERGE, which means you can use one step to prepare rows and another step to consume them in the same statement. That is handy when you want to move records into an archive table, delete a slice of data while capturing it for logging, or stage changes before inserting them elsewhere. The pattern feels like passing a note from one station to the next: the first step prepares the package, and the main statement delivers it.
If we reduce all of this to a working habit, it becomes easier to choose. Use a subquery when the inner question is narrow, local, and meant to answer one clause. Use a CTE when you want a named checkpoint, a multi-step transformation, or a recursive walk through connected data. In SQL subqueries vs CTEs, the best choice is rarely about looking clever; it is about matching the structure of the query to the shape of the problem, so the logic feels natural both when you write it and when someone else reads it later.