Architecture Overview
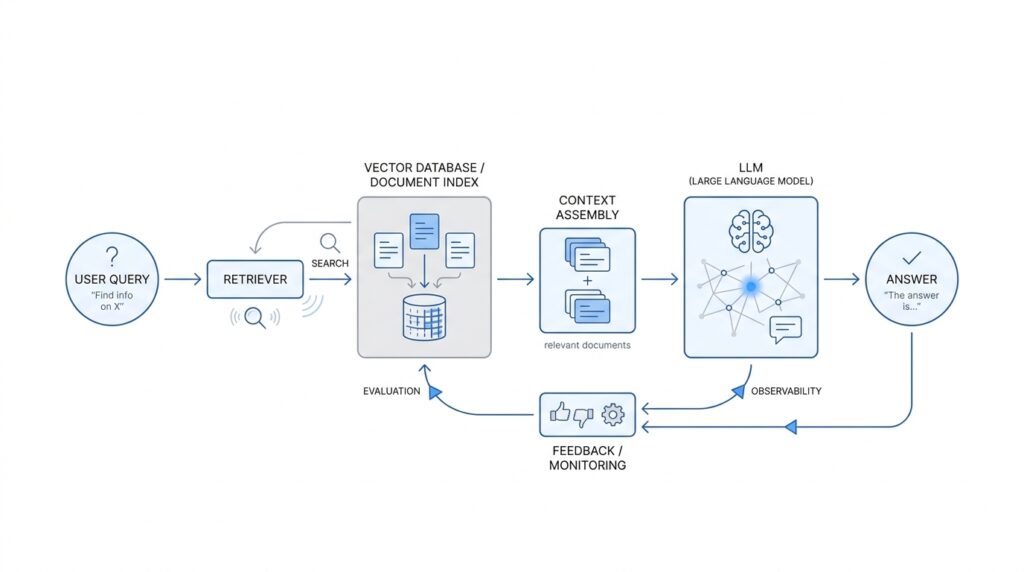
What does a production-ready retrieval-augmented generation system actually look like behind the scenes? The easiest way to picture it is as two connected journeys: one path prepares knowledge before anyone asks a question, and the other path serves answers in real time. In a typical RAG architecture, the first path takes documents, tables, or other source data, breaks them into smaller pieces, enriches them, and stores them for fast search; the second path turns a user’s question into a search, gathers the most relevant context, and sends that context to the language model as grounding data.
That split matters because it keeps the system both responsive and trustworthy. During ingestion, we prepare the knowledge base with chunking, which means dividing large documents into smaller passages that are easier to retrieve and cheaper to use than whole files. We then create embeddings, which are numerical representations of text that capture meaning so similar ideas sit near each other in vector space; a vector database stores and searches those embeddings. This is the quiet work that makes a RAG system feel intelligent later, because the model is no longer guessing from memory alone.
Once the data is indexed, the live request path begins to feel like a careful librarian at the desk. Your question is embedded with the same model or compatible representation, then the retriever looks for nearby chunks that match the intent of the query, often using vector search and, in more advanced setups, metadata filters or reranking to improve precision. Query translation can also help reshape a messy user question into something the retrieval layer can use more effectively. In plain language, this stage decides which facts deserve to sit at the front of the answer, instead of handing the language model a pile of loosely related text.
After retrieval, the orchestration layer assembles the prompt. This is where the system becomes more than a search tool: it combines the user’s request, the retrieved passages, and instructions that tell the model how to answer. Think of it like setting a dinner table before the guests arrive; the order matters, and the labels matter, because the model will follow the framing you provide. This is also where production-ready RAG architecture often enforces guardrails such as source citations, access control, and constraints on what the model can and cannot use.
Then comes generation, the moment the language model turns grounded context into a readable response. The best systems do not stop at one pass, though, because production RAG has to deal with imperfect retrieval, changing data, and real users who ask slippery questions. That is why many teams add evaluation and monitoring as a first-class part of the architecture, tracking quality, cost, and latency during development and in production, and measuring retrieval quality as well as end-to-end answer quality. In practice, that feedback loop is what keeps a RAG system from drifting from helpful to fragile over time.
If we zoom out, the whole architecture becomes easier to remember as a story with four scenes: prepare the knowledge, search the knowledge, frame the prompt, and generate the answer. Each scene has its own job, and each one can fail in a different way, which is why production systems separate them instead of hiding everything inside one black box. That separation gives us room to tune chunking, embeddings, retrieval, and monitoring independently, which is exactly what makes a retrieval-augmented generation system practical at scale.
Document Processing and Chunking
Before retrieval can feel smart, the documents themselves need to be made readable to the machine. That is where document processing and chunking enters the story: we take messy source files and turn them into pieces the retrieval layer can search with confidence. If the earlier architecture felt like building a library, this stage is the part where we unpack the boxes, repair the labels, and decide how to shelve each page so future questions land on the right shelf.
The first job is extraction, which means pulling text and structure out of the original file. A plain text document is straightforward, but a PDF, which is a file format designed to preserve layout, can hide text in awkward places, and a scanned image may contain no real text at all until we run optical character recognition, or OCR, software that reads text from images. In production RAG, this step matters because the quality of the final answer depends on whether we preserved headings, paragraphs, lists, and table boundaries instead of flattening everything into a meaningless wall of words.
Once the raw content is out, we clean it so the retrieval system does not trip over noise. That usually means removing repeated headers and footers, fixing broken line wraps, normalizing whitespace, and deciding what to do with page numbers, navigation text, or duplicated captions. This is also where we attach metadata, which is extra information about each piece of content, such as the source file, section name, page number, access level, or timestamp. Metadata gives us a map later, so when a chunk looks relevant, we know where it came from and whether the user is allowed to see it.
Then comes the part most people mean when they talk about document processing and chunking: splitting long content into smaller pieces. What is the right chunk size for RAG? There is no magic number, because the best size depends on how dense the writing is and how the system will search it. Very small chunks can miss context, while very large chunks can bury the useful sentence inside too much unrelated text, like trying to find one recipe note inside an entire cookbook.
A helpful way to think about chunking is to follow the document’s own logic before we fall back to fixed sizes. When we can, we split on natural boundaries such as headings, sections, paragraphs, or rows in a table, because those boundaries often match how humans organize meaning. If the document is long or uneven, we may use overlapping chunks, which means two neighboring chunks share a little text so important ideas near the edges do not disappear between slices. That overlap is a small but powerful trick in RAG chunking, because it protects context without forcing every chunk to become huge.
Not every document should be treated the same way, either. A legal contract, a support article, and a technical manual each carry meaning differently, so the chunking strategy should respect the shape of the content. Tables may need to stay together, code blocks may need to remain intact, and question-answer pages may work best when the question and answer travel as one unit. In other words, document processing is not only about breaking things apart; it is also about knowing what should stay together so the retrieved passage still reads like a coherent thought.
As we build this pipeline, we are really tuning a tradeoff between recall and precision, two retrieval terms that describe how broadly and how accurately the system finds relevant text. Bigger chunks can improve recall because they hold more context, but smaller, cleaner chunks often improve precision because they are easier to match to a specific query. The practical goal is to give the retriever enough meaning to recognize the right passage without handing it so much extra material that the answer becomes muddy. That balance is why chunking is one of the quiet make-or-break decisions in a production RAG system.
By the time we finish this stage, the documents no longer feel like unwieldy files on disk. They have become searchable pieces with structure, provenance, and enough local context to support good retrieval later. And once that foundation is solid, we can move into embedding and indexing with much better odds that the right information will surface when the user finally asks for it.
Retrieval, Hybrid Search, and Reranking
Once the chunks are in place, the story turns to a harder question: how do we find the right ones when a user asks something messy, incomplete, or oddly specific? This is where retrieval, hybrid search, and reranking earn their keep. In a production RAG system, retrieval is the part that goes hunting for candidate passages, and it has to work more like a careful librarian than a keyword matcher with a lucky streak.
A useful way to picture the search stage is to imagine two different assistants working side by side. One assistant looks for exact words and phrases, which is called lexical search, meaning the system matches the text you type against the text it already has. The other assistant looks for meaning, which is called semantic search, meaning the system compares the ideas in your query and the document chunks using embeddings, the numerical representations we introduced earlier. If you have ever wondered, “How do I make RAG retrieval accurate when users don’t ask perfect questions?” this is the place where the answer starts to take shape.
Semantic search is powerful because it can connect a question to a passage even when the wording is different. If a user asks about “resetting access” and the document says “revoking login credentials,” a semantic retriever may still spot the relationship. But semantic retrieval is not flawless, especially when a query includes product names, error codes, legal phrases, or other exact terms that matter word for word. That is why many production systems use hybrid search, which combines lexical search and semantic search so the system can catch both literal matches and meaning-based matches.
Hybrid search works a bit like using a map and a compass together. The lexical side keeps us grounded in exact language, while the semantic side helps us understand intent, synonyms, and broader context. In practice, this often means the system runs both searches, merges the results, and then applies scoring rules to decide which passages deserve attention. For production RAG, hybrid search is often the safer default because it reduces the chance that the retriever misses an obvious clue just because the wording changed.
Even then, the first search pass is rarely the final answer. That is where reranking comes in, and reranking means taking the top candidate passages from retrieval and scoring them again with a more precise model. Think of it as a second opinion from a subject-matter editor who reads the shortlist carefully instead of skimming the whole library. The first pass is optimized for speed and breadth; reranking is optimized for judgment and relevance, which is why it often improves answer quality so noticeably.
Reranking matters most when several chunks look almost right. A vague user question can pull in a dozen similar passages, and some will be close enough to fool a generator but not close enough to help it answer well. A reranker can inspect the relationship between the query and each candidate passage in more detail, then push the strongest one to the top. That extra step often makes retrieval feel less like a pile of search results and more like a guided recommendation built for the exact question at hand.
The best results usually come from combining retrieval signals instead of trusting only one. Metadata filters can narrow the field by source, date, language, or access level; hybrid search can widen the net without losing exact matches; reranking can restore precision after the broader search has done its work. In other words, production RAG retrieval is less about finding one magical algorithm and more about layering several good ones so each compensates for the others’ blind spots. That layered approach is what keeps the system steady when documents are uneven and user questions are not perfectly written.
By the time this pipeline finishes, we have not just collected text—we have assembled a ranked set of evidence that is good enough to hand to the language model. The next step is deciding how to package that evidence so the model can use it without getting distracted or overwhelmed.
Prompt Design for Grounded Answers
Once retrieval has done its job, the prompt becomes the table where all the evidence is laid out. This is where prompt design for grounded answers starts to matter, because the model will lean on whatever we place closest, clearest, and most consistently. In OpenAI’s prompting guidance, overall role and tone belong in the system message, while task-specific details and examples belong in user messages; the same guide also recommends using concise few-shot examples and re-running evals whenever the prompt changes.
The first thing we want the prompt to do is narrow the model’s job. If the user asks a broad question, the prompt should quietly turn that into a narrower rule: answer using the retrieved context, prefer the supplied sources, and do not wander into memory unless the context truly leaves a gap. Why does that matter? Because long-form RAG answers can still drift away from the retrieved text even when the final answer sounds correct, and recent research shows that a significant share of generated sentences can remain ungrounded without stronger safeguards.
Next, we want the evidence to look unmistakably like evidence. A well-designed grounded prompt separates the user question from the retrieved chunks, often with clear labels or delimiters, so the model can tell instructions from source text at a glance. That structure is not cosmetic; it helps the model treat retrieved passages as the place to look for facts rather than as loose background noise. OpenAI’s retrieval docs describe semantic search results as returning relevant chunks along with similarity scores and file of origin, which makes the prompt easier to frame around traceable material instead of anonymous text.
Then comes the most important guardrail: the no-answer path. If the retrieved passages do not support the question, the prompt should tell the model to say so plainly instead of filling in the blank with a confident guess. In grounded RAG systems, this is often the difference between a trustworthy assistant and one that sounds polished while inventing details. Recent work on answer generation in RAG systems recommends including the user query, the retrieved chunks, explicit citation instructions, and a rule for insufficient information, so the model can stay faithful to the source material.
Citations are the next piece of the puzzle, because grounded answers need a paper trail. When we ask the model to cite which chunk supports which claim, we are not decorating the response; we are making it auditable. That audit trail is especially useful in production RAG, where users may need to verify a policy, locate the exact line in a manual, or compare two source passages side by side. The practical prompt pattern is to require citations for factual claims and to keep the answer tied to the supplied excerpts rather than to the model’s own general knowledge.
A strong grounded prompt also stays compact. Models have finite context, so if we overload the prompt with too many passages, we blur the signal and invite the model to average everything together instead of answering carefully. That is why production systems often pass only the top-ranked chunks into generation, then ask the model to synthesize from that smaller set. In OpenAI’s docs, prompt versioning and evals are part of the workflow for exactly this reason: we want to test whether a new prompt is more reliable before we trust it with users.
If you are wondering what this looks like in practice, imagine a calm guide standing between the question and the evidence. The guide points to the relevant page, ignores the tempting but unsupported rumor in the corner, and says “I can answer this only from what we have.” That is the real goal of prompt design for grounded answers: not cleverness for its own sake, but a response that feels careful, traceable, and quietly dependable.
Evaluation, Testing, and Monitoring
Once the prompt is in place, the hardest question arrives: how do we know the RAG system is actually helping instead of merely sounding confident? Evaluation, testing, and monitoring are the safety net here, because OpenAI’s guidance frames evals as a way to measure style and content criteria, recommends building them before shipping, and calls for continuous evaluation as the system changes. In a production RAG pipeline, that means we treat quality as something we can check, not something we hope for.
The best test set looks like your real users, not a polished demo. OpenAI recommends mixing production data, historical logs, human-curated examples, and synthetic edge cases, then expanding the dataset as blind spots appear. That matters because RAG failures often hide in messy questions, outdated policies, or prompts that look normal to us but confuse the retriever.
How do we know the answer is grounded in the retrieved evidence? We measure the retrieval layer and the generation layer separately. OpenAI’s docs suggest metrics like context recall and context precision for doc Q&A, while research on RAG evaluation highlights context relevance, answer faithfulness, and answer relevance as distinct dimensions; RAGAs also shows that these checks can be done without ground-truth human annotations. Put in plain language, we want to know whether the right context was found, whether the model used it honestly, and whether the final answer actually solves the user’s problem.
Automated scores are useful, but they should not become our only judge. OpenAI’s evaluation guidance warns against ignoring human feedback, and it recommends calibrating automated metrics against human evals so we can catch the cases where a metric looks healthy but a person would still say the answer feels off. Trace grading helps here because it scores the end-to-end trace, the log of decisions, tool calls, and reasoning steps, so we can see where a workflow broke instead of staring at a single final answer.
Testing also needs version discipline. When we change the prompt, swap models, adjust chunking, or tighten retrieval filters, we should rerun the same evals and compare results version by version. OpenAI’s prompt and dataset tools are built around that habit: prompts are versioned, datasets can drive multiple prompt variants, and saved graders let us spot regressions when a change helps one slice of traffic but hurts another. That is how RAG testing becomes less like a one-time check and more like a controlled experiment.
Monitoring begins when the system leaves the lab. OpenAI recommends continuous evaluation on every change, watching for new nondeterministic failures, and growing the eval set over time as fresh cases appear; its trace grading tools add a workflow-level view so we can benchmark changes and identify regressions across many examples. In practice, that turns live traffic into a feedback loop: when a query goes sideways, we can inspect the trace, see which chunk was selected, and decide whether the problem lives in retrieval, prompting, or generation.
This is the part where RAG systems stay healthy over months, not just days. Every weird user question, stale fact, or misleading retrieval should become a new test case, because the evaluation set is supposed to grow with the product. If we keep feeding those failures back into the dataset, the system gets a little sturdier each time, and monitoring stops feeling like alarms after the fact and starts feeling like an early-warning conversation between us and the model.
Scaling, Caching, and Reliability
When a production RAG system starts getting real traffic, the first problem is rarely intelligence; it is pressure. How do you keep a RAG system fast when every answer starts with a fresh search? The answer is to split work into what must happen now and what can safely wait. In practice, scaling gets easier when we reduce the number of requests we make, trim the number of tokens we send and generate, and remember that output generation is often the biggest latency cost of all.
Caching is the easiest place to feel that relief. OpenAI’s prompt caching works on exact prefix matches, which means the front of the prompt should stay stable while the variable parts move to the end. That is why system instructions, reusable examples, and tool schemas belong up front, while the user’s question and retrieved chunks come later. The benefit can be dramatic: OpenAI says prompt caching can cut latency by up to 80% and input token costs by up to 90%, and it activates for prompts of 1024 tokens or more.
That same idea helps us think about offline work too. Not every RAG task needs an immediate response, and those jobs are excellent candidates for batch processing. OpenAI’s Batch API is built for asynchronous jobs such as evaluations, classification, and embedding large content repositories, and it uses a separate pool of much higher rate limits with a 24-hour turnaround and 50% lower cost than synchronous requests. In other words, when the user does not need an answer this second, we can move the heavy lifting out of the live path and keep the interactive system lighter.
Reliability becomes more important as soon as traffic is no longer polite. Rate limits exist to protect the service and keep access fair, and OpenAI measures them in request and token budgets such as RPM and TPM. A practical response is to retry transient failures with random exponential backoff, which means waiting a little, then waiting longer if the error continues, rather than hammering the API in a tight loop. The docs also note that failed requests still count against the minute-level limit, so retries need to be patient, not aggressive.
The next layer of reliability is making the model easier for the rest of your system to trust. Structured Outputs helps by forcing responses to follow a JSON Schema, which reduces format drift and makes downstream parsing more predictable; the docs also note that explicit refusals become programmatically detectable. That matters in RAG because the answer is often only one step in a larger workflow, and a messy response can break a pipeline even when the content itself is good. When the model says, in effect, “I cannot produce a valid answer,” your application can handle that cleanly instead of guessing what the output meant.
Finally, reliability has to survive the next release, not just the current one. OpenAI’s evaluation guidance recommends continuous evaluation on every change, monitoring for new cases of nondeterminism, and growing the eval set over time, which is exactly the habit a production RAG system needs as documents, prompts, and retrieval logic evolve. That creates a quiet feedback loop: if caching improves latency, batching absorbs offline load, retries smooth over rate limits, and evals catch regressions early, the whole system becomes easier to trust under stress.