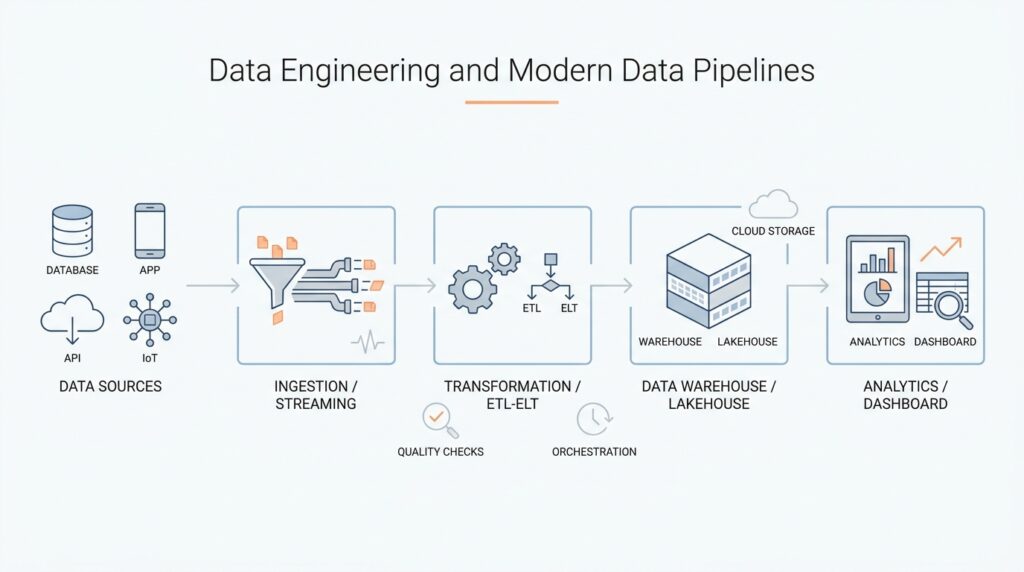
Define Pipeline Goals
Before we sketch a single table, job schedule, or transformation, we need to answer the question that quietly decides whether a data pipeline becomes useful or painful: what is it supposed to achieve? In data engineering, pipeline goals are the outcomes you want the system to deliver, such as fresher reports, cleaner data, faster decisions, or lower operating cost. Without that shared destination, even a well-built pipeline can feel like a machine running hard in the wrong direction.
This is where many teams get tangled. They start with tools, sources, and code, but the real starting point is the business need sitting behind the work. Are we trying to move data every minute, every hour, or once a day? Do people need trustworthy numbers for dashboards, or do they need near-real-time alerts when something changes? When you ask, “What should this data pipeline actually do?”, you are not being vague; you are doing the most important planning step in the whole journey.
A good goal feels concrete enough that everyone can picture success. If the pipeline feeds a sales dashboard, the goal might be that the numbers refresh by 8 a.m. with less than five minutes of delay. If it supports fraud detection, the goal might be to deliver events quickly enough to catch suspicious activity before damage spreads. If it powers monthly finance reporting, the goal might be accuracy and completeness above speed. These choices matter because modern data pipelines are always balancing trade-offs, and pipeline goals tell us which trade-offs to favor.
Think of it like packing for a trip. If you do not know whether you are heading to a beach, a business meeting, or a mountain trail, you will pack the wrong bag. Data engineering works the same way. A pipeline built for rapid streaming needs different decisions than a batch pipeline built for overnight reporting, and the goal tells us which path to take. It also helps us decide what not to optimize, which is often just as valuable as deciding what to improve.
Clarity around pipeline goals also protects the people who depend on the output. A data pipeline can move information beautifully and still fail if no one knows how fresh the data must be, what quality checks matter, or what happens when a source system goes offline. By naming those expectations early, we give the pipeline a definition of success that includes reliability, freshness, completeness, and cost, not just technical elegance. That kind of clarity keeps data engineering grounded in real use instead of abstract mechanics.
As we define those goals, it helps to separate the must-haves from the nice-to-haves. A must-have is the line the pipeline cannot cross, like “no missing customer records” or “updates must arrive before the morning meeting.” A nice-to-have is an improvement that would help, but would not break the use case if it slipped, such as shaving a few minutes off processing time. This distinction gives us a practical way to make decisions when resources, time, or compute power are limited.
Pipeline goals also act like a contract between the team building the system and the people using it. When the contract is clear, we can measure whether the data pipeline is doing its job instead of guessing from complaints or dashboard confusion. That shared target becomes the north star for choices about architecture, testing, monitoring, and alerting. Once we know the goal, the next step is to translate it into the specific requirements that will shape the pipeline itself.
Ingest Batch and Streaming Data
Now that we know the destination, the next question is how the data should travel to get there. This is where data ingestion enters the story: it is the process of bringing data from source systems into the pipeline so we can store, clean, and use it. The two most common paths are batch data ingestion, which moves data in groups, and streaming data ingestion, which moves data continuously as events happen. Choosing between them is not a technical preference contest; it is a practical decision shaped by the goals we defined earlier.
Batch ingestion feels a bit like carrying groceries home in a few strong bags instead of one item at a time. We wait until enough data has accumulated, then move it together on a schedule, such as every hour or every night. This approach works well when freshness can lag a little, the source system is easier to read in chunks, or we want to reduce cost by processing fewer, larger jobs. If your sales report only needs to be ready by breakfast, batch processing often gives us the right balance of speed, simplicity, and reliability.
Streaming ingestion tells a different story. Here, data flows in continuously, one event at a time or in very small slices, like a live feed rather than a daily delivery truck. An event is a single happening in a system, such as a purchase, a click, or a sensor reading. Streaming is useful when the pipeline must react quickly, such as flagging fraud, updating a live dashboard, or triggering an alert the moment something unusual appears. If you have ever wondered, “What is the difference between batch and streaming data ingestion?” the answer is really about timing: batch waits and groups, while streaming keeps moving.
The choice becomes clearer when we think about latency, which means the delay between data being created and data being available to use. Batch ingestion usually has higher latency because it waits for a window to close before work begins. Streaming ingestion lowers latency because it brings data forward almost immediately. That lower delay is powerful, but it also asks more from the system, because the pipeline must handle a constant trickle of records instead of a tidy bundle.
That constant flow introduces a few new ideas, and they are easier to understand than they first sound. A streaming pipeline often needs checkpointing, which is a way to save progress so the system can recover after a failure without starting over from scratch. It may also need backpressure, which means slowing the incoming flow when downstream systems cannot keep up. These safeguards help us protect data quality and reliability, which matter just as much as speed when we are building a data pipeline that people depend on.
Batch systems have their own strengths, especially when the data volume is large and the business can tolerate a delay. They are often easier to test, easier to replay, and cheaper to operate because they work in planned windows instead of running all the time. That makes batch data ingestion a strong fit for monthly finance reports, historical analysis, and large-scale warehouse loads. In other words, batch gives us a calm, predictable rhythm that many teams can support without needing a real-time platform.
In practice, many modern pipelines use both approaches together. A team might stream critical customer events into a live dashboard while also loading the same data into batch storage for deeper analysis later. This hybrid design lets us match the transport method to the job, rather than forcing every requirement into one shape. It is a little like using both a bicycle and a truck: one is better for quick trips, and the other is better for hauling a full load.
As we make that choice, the earlier pipeline goals keep doing their quiet work in the background. If the goal is instant action, streaming ingestion earns its complexity. If the goal is dependable reporting with controlled cost, batch data ingestion may be the wiser path. Once we understand how data enters the system, we are ready to look at what happens next: how we organize that incoming flow so it stays usable, trustworthy, and ready for transformation.
Transform with ELT Layers
Once the data has arrived, the real work begins quietly in the background. This is where ELT layers help us turn a noisy stream of incoming records into something people can trust and use. ELT stands for extract, load, transform, which means we bring the data in first, store it in a central system, and then shape it there. If you have ever wondered, “What are ELT layers and why do they matter?”, the short answer is that they give raw data a safe path from messy source to useful insight.
The first layer is usually the raw layer, sometimes called the landing zone. This is the place where data arrives in its original form, before we try to clean, rename, or combine anything. Think of it like unloading boxes into a foyer before you decide where each item belongs. That pause matters because it gives us a record of what came in, when it arrived, and what the source system actually sent, which is invaluable when something looks off later.
From there, we move into the clean layer, where transformation starts to make the data easier to work with. Here, we remove obvious duplicates, fix inconsistent formats, standardize dates, and apply basic rules so records look and behave the same way. This is the part of ELT layers that feels a little like sorting laundry: whites with whites, colors with colors, and everything checked before it goes farther. The goal is not to make the data perfect yet; the goal is to make it reliable enough for deeper shaping.
The next step is the curated layer, which is where the data becomes aligned with the way the business actually thinks. A curated layer is a carefully organized version of the data designed for analysis, reporting, or downstream applications. Instead of keeping every field exactly as the source system produced it, we choose the columns, relationships, and calculations that answer real questions. In a data engineering workflow, this is often where raw event data turns into familiar objects like customer summaries, daily revenue totals, or product performance tables.
This layered approach works well because it separates concerns. The raw layer protects the original data, the clean layer improves quality, and the curated layer shapes the final output for use. When those jobs live in separate ELT layers, teams can debug problems faster because they can see where something changed. If a number looks wrong in a dashboard, we do not have to guess whether the source was broken, the cleaning rule failed, or the business logic needs adjustment.
The structure also makes collaboration easier. Analysts can explore the curated layer without needing to understand every source quirk, while engineers can improve transformation logic without disturbing the original load process. That division is one reason ELT layers have become so common in modern data pipelines: they create a clearer handoff between ingestion and analysis. They also support a more natural growth path, since new tables and rules can be added without rebuilding the entire system from scratch.
Not every layer needs to be fancy, and that is part of the appeal. Some teams use three named zones, while others keep the ideas but bundle them into fewer physical tables or schemas. The important thing is the sequence: land first, refine next, and only then publish data for broad use. When we treat transformation as a layered journey instead of a single giant script, we make the pipeline easier to understand, easier to test, and easier to change as business needs evolve.
In practice, the best ELT layers act like a set of checkpoints on a trail. Each stop gives us a chance to inspect progress before we move onward, which reduces surprises and makes the whole data pipeline more dependable. That is why strong ELT design is less about extra machinery and more about creating a clear path from ingestion to insight. Once that path is in place, we can start thinking about the rules, checks, and models that keep each layer honest and useful.
Orchestrate Workflow Dependencies
Once the raw, clean, and curated layers are in place, the next challenge is making them move in the right order. This is where workflow dependencies come in: they are the rules that say one step must finish before another can begin. In data pipeline orchestration, those rules keep the whole system from acting like a room full of people talking at once. Instead, each task gets its cue, and the pipeline progresses in a sequence that matches how the data actually needs to flow.
If you have ever asked, “How do we make sure the clean layer never starts before the raw layer finishes?”, you are already thinking like an orchestrator. A workflow is the full path of tasks, and a dependency is the link between two tasks that tells us who waits and who goes first. We often draw that structure as a DAG, which stands for directed acyclic graph; in plain language, it is a map of steps with arrows showing direction and no loops that send us back in circles. That map matters because it turns a loose collection of jobs into a data pipeline orchestration plan we can trust.
The easiest way to picture it is to imagine a kitchen during dinner service. The vegetables must be washed before they are chopped, chopped before they are cooked, and cooked before they are plated. In the same way, a warehouse load might need ingestion to finish before transformation starts, and transformation to finish before reporting updates. When we orchestrate workflow dependencies well, we are not adding bureaucracy; we are giving each task a clear place in the story so the work feels orderly instead of fragile.
This becomes especially important when tasks run at different speeds. Some steps are quick, while others take longer because they process more data or depend on slower source systems. Orchestrating workflow dependencies helps us avoid race conditions, which are timing problems that happen when one task reaches for data before another task has finished preparing it. A workflow manager can hold a downstream task until its upstream task succeeds, which means the pipeline waits for the right moment instead of guessing.
That waiting also gives us room to handle failure in a controlled way. A retry is another attempt after a task fails, and it often saves us from temporary issues like a network hiccup or a brief source outage. A timeout is the maximum amount of time we are willing to wait before we call a task stalled, and an alert is the signal that tells a person to look closer. When we orchestrate workflow dependencies with these safeguards, we make the pipeline resilient without pretending every system will behave perfectly.
Good orchestration also depends on knowing which tasks can run together and which must stay in order. Some jobs are independent, so we can process them at the same time and save time overall. Others depend on shared results, so we keep them in sequence to protect correctness. This balance is one of the quiet strengths of data pipeline orchestration: it lets us speed up the parts that can move freely while preserving the structure that the data needs.
As the workflow grows, these dependency rules become more than a technical detail; they become a communication tool. Engineers can see which task feeds which layer, analysts can understand why a dashboard waits for a refresh, and operators can trace where a delay started. That clarity is especially helpful when a pipeline includes both batch and streaming pieces, because the orchestration layer can coordinate tasks that run on schedules with tasks that respond to incoming events. In other words, workflow dependencies help the whole system stay readable even as it becomes more sophisticated.
The real payoff is confidence. When we orchestrate workflow dependencies thoughtfully, we can say with a straight face that the curated table only updates after the clean data is ready, the clean data only appears after ingestion succeeds, and any failure leaves behind a trail we can inspect. That is what turns a chain of jobs into dependable data pipeline orchestration, and it sets us up to think next about the checks that keep those jobs from drifting out of shape.
Add Quality and Validation Checks
Once the workflow is moving in the right order, we still need one more layer of protection: data quality checks and validation checks. This is the moment where we ask whether the data is not only arriving, but arriving in a shape we can trust. A data pipeline can be perfectly scheduled and still deliver bad answers if a source changes silently, a column goes missing, or duplicate records sneak in overnight. That is why quality and validation checks sit so close to the heart of data engineering.
The easiest way to think about these checks is to picture a border crossing. The data is allowed to enter, but it has to show its papers before it can move deeper into the system. A validation check is a rule that confirms the data matches what we expect, while a data quality check looks at whether the data is fit for use in the real world. Those ideas sound similar at first, but they play different roles: validation asks, “Is this allowed?”, while quality asks, “Can we rely on this?”
So what does that look like inside a modern data pipeline? We usually start with schema checks, which verify that the structure of the data matches the agreed layout. A schema is the blueprint for a table or file: it names the columns, their types, and sometimes their required format. If a customer ID suddenly arrives as text instead of a number, or if a source system drops a field that downstream models depend on, a schema check can stop the problem early instead of letting it spread.
From there, we add checks that look at the contents themselves. Null checks confirm whether important fields are missing, uniqueness checks make sure a record appears only once when it should, and range checks test whether values stay inside sensible limits. These are the kinds of data quality checks that catch everyday surprises, like an order total of negative fifty dollars or a timestamp that lands in the year 2099. They are small guardrails, but together they keep the pipeline from drifting into nonsense.
This is also where freshness checks matter, especially in pipelines that support dashboards or alerts. Freshness means how recently the data was updated, and a freshness validation checks whether the latest load arrived on time. If a source system stalls or a scheduled job fails quietly, the tables may still look complete while actually being stale. That is a tricky failure because it does not always break the job itself, but it can still break the business decision built on top of it.
When people ask, “How do you add validation checks to a data pipeline?”, the answer is usually to place them at more than one point in the journey. Some checks belong right after ingestion, where they can catch broken input before it spreads. Others belong after transformation, where they confirm the cleaned and curated layers still match the business rules we care about. Thinking in layers keeps us from treating quality as a single gate; instead, we build a series of checkpoints that protect the whole path.
As the pipeline grows, we also need to decide what happens when a check fails. A hard failure can stop bad data from moving forward, which is useful when correctness matters more than speed. In other cases, we may send the record to a quarantine area, which is a safe holding space for data that needs review instead of immediate use. That gives teams a chance to inspect the problem without losing the original evidence, which is often the fastest route to a fix.
Good validation checks do more than protect numbers; they also make the pipeline easier to understand and operate. When a rule fails, the message should tell us what broke, where it broke, and why it matters, so the next person does not have to become a detective before they can act. That clarity is what turns data quality checks from a vague idea into a practical habit, and it is how we keep the data pipeline honest as new sources, transformations, and business needs keep arriving.
Monitor, Secure, and Govern
The moment our checks are in place, the pipeline still needs someone watching the door, guarding the room, and keeping the rules clear. That is where monitoring, security, and governance enter the story, because a data pipeline is only as dependable as the system around it. You may have wondered, “How do we keep a data pipeline healthy after it goes live?” The answer starts with visibility, then adds protection, then ends with shared responsibility.
Monitoring is our way of listening for trouble before users feel it. In plain language, monitoring means collecting signals about how the pipeline is behaving, such as run time, failure rate, data volume, and freshness. If a daily load that normally takes ten minutes suddenly takes an hour, monitoring helps us notice the slowdown while there is still time to act. This matters because a data pipeline can look fine on the surface while quietly drifting out of shape underneath.
A good monitoring setup tells a story, not just a number. We want to see when a job started, when it ended, whether it succeeded, and whether the output still looks normal compared with recent runs. That often includes logging, which is the practice of recording events in a readable trail, and alerting, which is the act of sending a message when something needs attention. Together, they help teams move from guessing to knowing, which is a huge shift when a pipeline supports dashboards, reports, or automated decisions.
But monitoring alone cannot protect sensitive information, so we also need security. Security means preventing the wrong people, systems, or processes from seeing or changing data. In a data engineering setting, that often includes authentication, which confirms who someone is, and authorization, which controls what they are allowed to do. It may also include encryption, which scrambles data so it is unreadable without the proper key, both when data is stored and when it moves between systems.
This is where the everyday picture helps. Monitoring is like the dashboard on a car, showing speed and engine warnings, while security is like the locks, keys, and seatbelts that keep the trip safe. Without security, even a well-run data pipeline can become a liability if customer records, financial data, or internal metrics leak into the wrong hands. Without monitoring, we may not notice that access has changed, a job is failing, or a pattern of suspicious activity is building quietly in the background.
Governance is the part that keeps everyone using the same map. Data governance means the policies, roles, and habits that define who owns data, how it should be used, and what standards it must meet. In practice, governance can include naming conventions, retention rules, approval steps, and definitions for important fields like “customer” or “active account.” It may sound bureaucratic at first, but it actually reduces confusion, because people spend less time arguing over meanings and more time using the data.
This is especially important in a modern data pipeline, where one table can feed many reports, models, and teams at once. If no one agrees on where a metric comes from or who can change it, trust starts to slip. Governance gives us a common language so a sales dashboard, a finance report, and a machine learning model can all rely on the same underlying truth. That kind of alignment turns data engineering from a collection of isolated jobs into a system people can depend on.
The strongest pipelines treat these three ideas as one habit rather than three separate chores. Monitoring tells us what is happening, security decides who may participate, and governance explains how the whole system should behave over time. When those pieces work together, the data pipeline becomes easier to operate, safer to share, and more trustworthy for everyone who depends on it. From there, we are ready to connect these controls back to the day-to-day practices that keep the pipeline running smoothly as new data, new users, and new risks keep arriving.