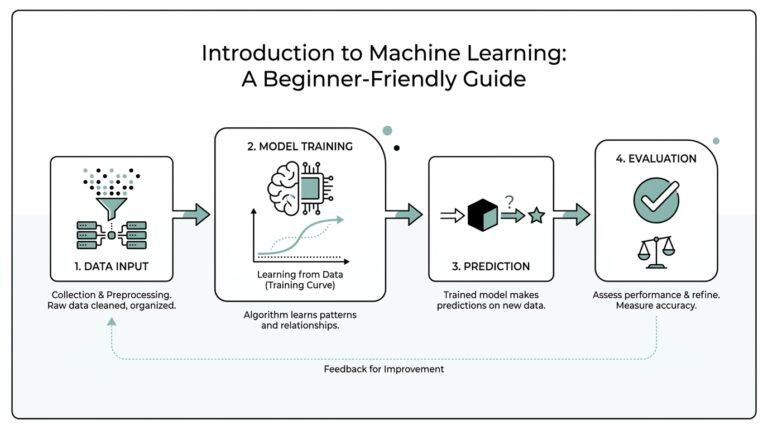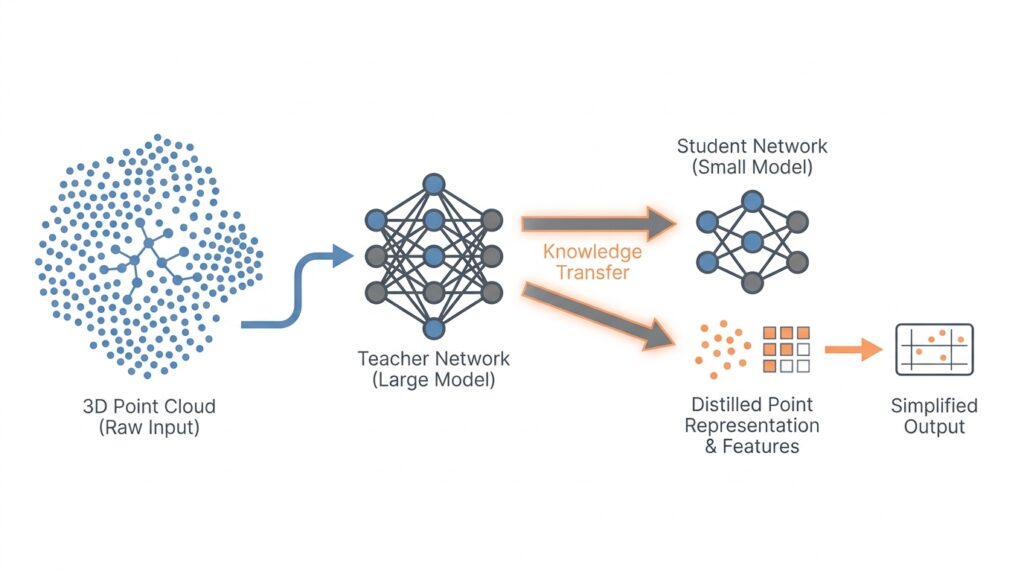
Point Cloud Distillation Basics
Picture the first time we ask a compact model to read a 3D scene: it has to make sense of a cloud of points floating in space, and those points can be massive, unstructured, and noisy. That is where knowledge distillation enters the story. Instead of teaching the smaller model only with the final answer, we let a larger teacher model pass along its softer, richer judgment through point cloud distillation, so the student learns not only what to predict but also how sure the teacher felt along the way. In the original distillation setup, the teacher’s class probabilities become soft targets, and the student is trained to match them, often alongside the true labels.
The tricky part is that 3D point clouds do not behave like images. Images live on a tidy grid of pixels, while point clouds are irregularly and sparsely distributed, and they often lose the kind of neighborhood structure that makes image methods comfortable. That means a recipe that works beautifully for 2D vision can stumble here, because point cloud models must recover local geometry from scattered points instead of leaning on a regular layout. So when we talk about point cloud distillation, we are really talking about copying knowledge in a way that respects shape, neighborhood, and spatial structure.
What, exactly, gets copied? A good way to think about it is that the teacher hands over its answer key and its margin notes. The answer key is the hard label, the one correct class or output. The margin notes are the soft targets, which come from the teacher’s output probabilities after applying a temperature, a knob that makes the distribution softer so the student can see which alternatives the teacher considered plausible. The same paper also shows that matching logits—the raw scores before softmax, the function that turns scores into probabilities—can be treated as a special case of distillation. In practice, this mixture helps the student absorb more structure than hard labels alone can provide.
Once we move into real 3D tasks, point cloud distillation starts to look less like a single trick and more like a family of teaching strategies. For semantic segmentation, where every point needs a label, researchers have used multi-to-single knowledge distillation to help the student handle classes that appear rarely or only on a few points. For 3D object detection, structured methods such as PointDistiller focus on local geometric structure and on points or voxels that matter more for the prediction. A voxel is just a small cube in 3D space, so weighting voxels differently is a way of telling the student, “pay close attention here.”
If you are wondering, “How do I start point cloud distillation without getting lost?” the safest path is to begin with the teacher’s strengths and then decide which kind of knowledge the student truly needs. Sometimes that means soft class probabilities; sometimes it means intermediate features, local relations, or geometry-aware signals. It also means keeping the student honest with the true labels, because the best results in distillation usually come from balancing soft and hard supervision instead of relying on only one. That balance is the heart of point cloud distillation basics: we are not shrinking a model blindly, we are packaging its judgment into a smaller body that can still see the shape of the world.
Point Cloud Challenges
Once we start using point cloud distillation in real projects, the clean classroom version meets a messier world. The teacher may have learned from a dense, polished scene, but the student often has to work with fewer points, uneven sampling, or noisy scans from the real world. That is where the challenge begins: the knowledge we want to transfer is not stored in a neat line of pixels, so the student has to learn from a shape that may be incomplete, sparse, or slightly distorted.
The biggest difficulty is that point clouds do not give us an obvious order to follow. A point cloud is a set of 3D points, not a grid, so there is no natural “left to right” or “top to bottom” arrangement like there is in an image. This matters because distillation works best when the teacher and student can agree on what to compare, yet two point clouds can describe the same object with points in different positions, densities, or sampling patterns. So when people ask, “Why is point cloud distillation harder than image distillation?”, the answer often starts with this lack of structure.
Local geometry creates another layer of difficulty. Local geometry means the small-scale shape around a point, like the curve of a chair leg or the edge of a car roof, and those tiny details often carry the meaning the model needs. If the student sees too few points in that region, it may miss the pattern entirely, even if the teacher recognized it clearly. In point cloud distillation, this makes feature matching tricky, because the student is not only copying a class decision but also trying to absorb the teacher’s sense of shape, neighborhood, and spatial relation.
The problem gets even more delicate when the scene includes clutter, occlusion, or class imbalance. Occlusion means part of an object is hidden from view, and class imbalance means some categories appear far more often than others, such as walls and floors compared with rare objects like signs or poles. A teacher can still produce useful soft targets, but the student may over-focus on the easy, common structures and under-learn the rare ones. That is why point cloud distillation often needs more than one kind of guidance, especially in segmentation and detection tasks where every missed detail can change the result.
Another challenge is deciding what the teacher should pass along. Soft class probabilities are helpful, but in point clouds they often do not tell the whole story, because two shapes can share similar labels while differing in local structure. Intermediate features, attention maps, and voxel-level cues can help, but each one adds a new design choice and a new chance for mismatch. A voxel, remember, is a small cube in 3D space, and aligning those cubes between teacher and student is not always straightforward when the two models organize space differently.
This is why many successful methods treat point cloud distillation as an alignment problem as much as a learning problem. The teacher and student must agree on where to look, what to compare, and how strongly to care about each region. If their internal representations are too different, the student may imitate noise instead of useful structure. If the supervision is too weak, the student misses the teacher’s richer judgment. The art lies in choosing a bridge that is strong enough to carry knowledge but flexible enough to fit the geometry of the data.
So the real lesson is not that point cloud distillation is fragile, but that it asks us to respect the shape of the data at every step. We need to think about sampling, sparsity, neighborhoods, and class balance before we think about shrinking a model. When those pieces line up, point cloud distillation becomes less like copying a verdict and more like learning how to read a three-dimensional scene with the teacher’s eyes.
Teacher-Student Architecture
When we move from distillation basics into the teacher-student architecture, the story becomes more concrete: one model sees the scene first, and the other learns by watching. The teacher is the larger, more capable network, while the student is the smaller network we want to deploy more efficiently. In point cloud distillation, this setup matters because the teacher-student architecture gives us a clear way to transfer not only answers, but also the teacher’s sense of shape, spacing, and local structure.
How does a teacher-student architecture help a student model understand a 3D scene? The easiest way to picture it is as a seasoned guide walking beside a newcomer through a cluttered room. The teacher has already learned where the important surfaces, edges, and object parts tend to appear, so during training it can point the student toward useful patterns instead of forcing the student to discover everything alone. That shared walk is the whole point of the teacher-student architecture: the student still does the thinking, but it gets better directions along the way.
In practice, the teacher usually stays fixed while the student keeps learning. That means the teacher does not change its knowledge during distillation; it acts like a stable reference point, much like a map you keep unfolding while you explore. The student, by contrast, updates its weights, which are the internal numbers a neural network uses to make decisions. This separation is important because it prevents the target from moving around, and it gives point cloud distillation a reliable source of guidance.
The next question is what, exactly, passes between the two models. Sometimes the teacher sends softened predictions at the output layer, which show not only the final class but also how strongly it considered nearby alternatives. Other times, the teacher shares intermediate features, which are internal representations that capture patterns at different depths of the network. In point cloud distillation, those intermediate features are especially valuable because they can carry geometric clues about local neighborhoods, making the teacher-student architecture more expressive than output matching alone.
This becomes even more useful when the teacher and student do not look at the scene in exactly the same way. A teacher may process denser points, richer channels, or a larger receptive field, which is the area of the input it can “see” at once. The student may use fewer points or a lighter backbone, which is the main feature-extraction part of the model. The teacher-student architecture creates a bridge between these two views, letting the student borrow a richer understanding without needing to carry the teacher’s full cost at inference time.
Of course, the bridge has to be designed carefully. If we connect the wrong layers, the student may receive signals that are too abstract, too detailed, or too mismatched to use well. That is why many point cloud distillation methods align corresponding stages of the two networks, so early layers can focus on local geometry while later layers can focus on higher-level object meaning. In other words, the teacher-student architecture works best when each part of the teacher talks to a student layer that is ready to listen.
A practical way to think about this architecture is that it teaches in layers, the same way a helpful person might first show you the room, then the furniture, and only afterward the hidden details that matter. The student does not need to copy the teacher perfectly; it needs to inherit the teacher’s habits of attention. That is why the teacher-student architecture is so effective for point cloud distillation: it turns a difficult 3D recognition task into a guided apprenticeship, where the student learns to notice the structure that makes the scene intelligible.
As we keep going, this architectural idea gives us a foundation for the more specialized methods that follow, because every good distillation strategy still depends on the same central relationship: one model leads, and the other learns how to see.
Distillation Loss Design
When the teacher-student setup is in place, the real work begins in the loss function, because that is where the teacher’s advice turns into something the student can actually learn from. A loss is the number we try to make smaller during training, and in point cloud distillation it often acts like a careful recipe rather than a single instruction. We usually mix the ordinary task loss, which checks the student against the true label, with a distillation loss, which checks how closely the student follows the teacher’s softened judgment.
That balance matters because a student model should not become a carbon copy of the teacher’s mistakes or blind spots. The task loss keeps it grounded in reality, while the distillation loss gives it a second set of eyes that can reveal which classes, shapes, or local patterns the teacher considered important. If you have ever wondered, “How do we design a distillation loss for point clouds without overcomplicating it?”, the safest answer is to start with this two-part idea: one term for truth, one term for guidance.
The most familiar version uses soft targets, which are the teacher’s output probabilities after a temperature is applied. Temperature is a tuning knob that spreads the probabilities out so the student can see more than the top answer; it makes the teacher’s uncertainty visible instead of hiding it. The student then tries to match that softened distribution, often with Kullback–Leibler divergence, a measure of how far one probability distribution is from another. In plain language, that loss asks, “Does the student’s belief about the scene look like the teacher’s belief?”
In point cloud distillation, though, output matching is often only the beginning. Point clouds carry shape through scattered 3D coordinates, so the loss often needs to respect geometry, not just class scores. That is why many designs add feature matching, which means comparing internal activations, the hidden representations a network builds while it thinks. These features can preserve local structure, helping the student notice the same neighborhood patterns, edges, and surfaces that the teacher used to make its decision.
Once we move from global predictions to local structure, the loss design starts to feel like tuning a set of dials. Some methods weigh important points more heavily, such as boundary points, foreground points, or voxels, which are small cubes used to divide 3D space into manageable regions. Others compare pairwise relations, asking whether nearby points in the teacher remain nearby in the student’s internal world. A point cloud distillation loss becomes stronger when it rewards both the answer and the arrangement behind the answer, because 3D understanding depends on both.
That raises a practical question: how do we choose the right mix? The honest answer is that the best loss usually depends on what the student is missing. If the student struggles with class confusion, soft-target matching can help. If it misses fine structures, geometry-aware feature loss may matter more. If it forgets rare objects in a busy scene, reweighting the loss toward those hard examples can keep them from disappearing into the background. The design is less like following a fixed formula and more like listening for what the student cannot yet see.
We also have to keep the different terms from fighting each other. A distillation loss that is too strong can pull the student away from the ground truth, while one that is too weak can turn teacher guidance into background noise. That is why researchers often introduce weighting coefficients, which are numbers that control how much each loss term matters. In practice, these weights act like the volume knobs on a stereo system: the goal is not to make one source louder than the other, but to hear both clearly enough to understand the full song.
The most useful way to think about point cloud distillation loss is that it translates knowledge into shape-aware pressure. It tells the student not only what class to predict, but also which parts of the scene deserve attention and which internal patterns are worth preserving. Once that idea clicks, the next step becomes more intuitive: we can start asking how to tailor that pressure for segmentation, detection, or other 3D tasks without losing the teacher’s spatial wisdom.
Cross-Modal Knowledge Transfer
Cross-modal knowledge transfer adds a new voice to the lesson. Instead of asking the teacher and student to speak only in 3D, we let knowledge travel from another modality, such as an image, text caption, multi-view render, or depth map, into the point cloud model. That matters because a point cloud often captures shape, while another modality may capture color, language, or a cleaner view of the same object. In cross-modal knowledge transfer, the student does not copy a second world blindly; it learns how different views of the same scene can sharpen each other.
This is a natural next step after the loss design we just explored. If a point cloud is a scattered sketch of a chair, an image can feel like the colored version of that sketch, and language can feel like the name tag someone pinned to it. Each source carries a different kind of clue, so the real question becomes: how do we use cross-modal knowledge transfer for point clouds without confusing the student? The answer is to treat the extra modality as a guide, not a replacement, and to look for shared meaning rather than identical form.
The first bridge we often build is between paired data, which means two or more modalities describe the same scene at the same time. A camera image and a point cloud from the same room, for example, can be aligned so the teacher’s rich visual features help the student understand edges, parts, and object boundaries. This is useful because images are usually dense and easy to process, while point clouds are sparse and irregular. So cross-modal knowledge transfer can let the student borrow the teacher’s easier-to-see structure while still learning to reason in 3D.
A common way to make that bridge work is through feature alignment. A feature is an internal representation a model builds while it processes data, and alignment means nudging two representations to describe the same thing in compatible ways. In plain language, we ask the student’s 3D features to sit near the teacher’s image or text features when both point to the same object or region. That can happen at the whole-scene level, at the object level, or even at the local patch level, where a patch is a small neighborhood of points or pixels. Cross-modal knowledge transfer becomes most helpful when the student can tell which parts of the other modality matter for its own 3D task.
Still, the fit is not always neat. Images and point clouds do not organize space the same way, and language does not organize space at all, so the models need a shared space, which is a learned representation where different modalities can be compared. Think of it like giving everyone in a group a common map legend. Once the legend is shared, the student can use image cues to recognize a sofa’s outline, or use a caption like “red traffic cone” to focus on a small but important object that might otherwise disappear in the point cloud noise. This is where cross-modal knowledge transfer feels especially powerful, because it rescues detail that a single modality may miss.
The hardest part is keeping the transfer grounded. If the image is blurry, the caption is vague, or the viewpoints do not match, the student can inherit the wrong clue and learn a shortcut instead of a true pattern. That is why successful methods often combine cross-modal guidance with the original 3D supervision, so the point cloud still has to answer to the task itself. What is cross-modal knowledge transfer in 3D point cloud distillation, then? It is a careful borrowing process: we borrow extra context, extra semantics, and extra confidence, but we let the 3D data stay in charge of the final decision.
When this works well, the payoff is easy to feel. The student becomes less dependent on sparse geometry alone and more able to recognize objects that are partially hidden, rare, or visually ambiguous. In practical terms, cross-modal knowledge transfer helps the model see the scene the way a person might: not through one sense, but through several hints that agree with each other. That richer apprenticeship is what makes the 3D learner sturdier, especially when the point cloud by itself leaves a few gaps in the story.
Efficient Detection and Segmentation
When we shift from learning what a scene contains to building a model that can work in the real world, efficiency becomes the next big question. A large teacher can afford to inspect a 3D scene with patience, but a student model for point cloud distillation has to do the same job with less memory, fewer operations, and much less time. That is especially important in 3D object detection and semantic segmentation, where the model may need to respond inside a robot, a car, or a handheld device. The point of distillation here is not only to preserve accuracy, but to help the student spend its effort where it matters most.
The difference between the two tasks is easy to picture once we slow down for a moment. 3D object detection asks, “Where is the object, and how big is it?”, while semantic segmentation asks, “What class does each point belong to?” Detection usually works with candidate regions or boxes, and segmentation works with point-by-point labels, so both tasks can become expensive very quickly. When we use knowledge distillation for point clouds, we are often trying to compress those decisions into a smaller network that can still read the scene clearly. That is why efficient detection and segmentation are less about shrinking the model blindly and more about teaching it to avoid wasted work.
In detection, the teacher can act like a patient editor who circles the important parts of a page. The teacher’s richer predictions can show the student which locations are likely to contain objects, which areas are background, and which boundaries deserve extra attention. In practice, this means the student does not need to chase every point with equal urgency; it can focus on the regions that matter for boxes, centers, and objectness, which is the model’s estimate of whether something is actually present. For point cloud distillation, that kind of guidance reduces the need for the student to brute-force its way through empty space.
That same idea becomes even more valuable in segmentation, where every point needs a decision. A teacher trained on a fuller representation can reveal subtle class transitions, like the edge between a chair seat and the floor or the line between a car body and the road. The student can then learn to preserve those boundaries without carrying a heavy decoder, which is the part of the network that turns internal features into final labels. If you have ever wondered, “How does point cloud distillation help semantic segmentation run faster?”, the answer is that it lets the student inherit boundary awareness and class structure without copying the teacher’s full size.
Efficiency also comes from deciding which signals deserve the most training attention. Not every point in a scene carries the same value, and not every prediction error matters equally, so distillation can emphasize foreground points, rare classes, or uncertain regions instead of treating the whole cloud as a flat field. That selective pressure is especially helpful when the scene is crowded, because the student might otherwise waste capacity on easy background surfaces and overlook small but important objects. In other words, efficient detection and segmentation depend on teaching the student to look like an attentive reader, not a frantic one.
This is where the teacher-student relationship starts to feel practical rather than abstract. The teacher does not hand over every internal detail; it hands over the parts that help the student make better boxes, cleaner masks, and sharper boundaries with fewer computations. A smaller backbone, fewer sampled points, or a lighter feature extractor can then work because the student has already learned where to concentrate. In that sense, point cloud distillation turns efficiency into a guided habit: the student learns to recognize the scene with less repetition, less noise, and far less wasted motion.
What we get, then, is a model that is not only smaller, but more focused. It knows which regions of the cloud deserve careful reasoning and which ones can pass by quickly, and that is exactly the kind of discipline real-time 3D systems need. Once that habit is in place, the next design choices become much easier to understand, because the student is no longer trying to see everything at once—it is learning how to see the right things first.