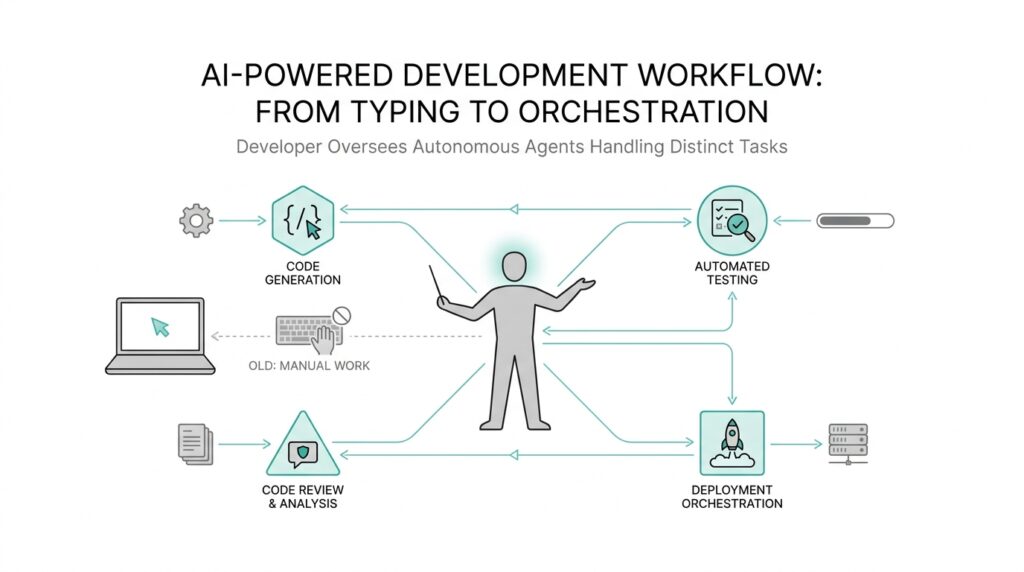
Why Agent Teams Matter
Imagine you are in the middle of a feature, and one AI tool gives you a decent answer, but not the whole path forward. One agent can write code, another can check edge cases, and a third can look for bugs before they reach production. That is where AI agent teams start to matter, because they turn a single helpful assistant into a small working crew. For developers, the shift is not only about speed; it is about learning how to direct a group of specialized helpers toward one outcome.
What makes AI agent teams different from a single chatbot? The answer is coordination. An agent is a software worker that can take actions toward a goal, while orchestration means guiding several of those workers so they do not overlap, contradict each other, or miss important steps. Think of it like a kitchen: one cook chops vegetables, another handles the stove, and a third checks the plating. The meal gets done faster and with fewer mistakes because each person has a role, and that same pattern is why AI agent teams are so powerful.
This matters because real development work rarely comes in neat, one-question chunks. You might need to understand a bug, inspect logs, compare an API response, update code, and then verify the fix. A single agent can try to do all of that, but it can also lose focus or overlook something small. With AI agent teams, we can split the job into pieces, letting one agent investigate, another propose changes, and another review the result like a cautious teammate who asks, “Did we test the tricky path?”
That division of labor is the real advantage. A coding agent can stay close to the implementation, a testing agent can think about failure cases, and a research agent can gather context from documentation or existing code patterns. When these agents work together, developers get more than a faster draft; they get a fuller process. In practice, AI agent teams can reduce the back-and-forth that usually happens when one tool tries to be expert at everything.
The other reason AI agent teams matter is reliability. A lone agent may sound confident even when it is wrong, which is unsettling if you are depending on it for real work. Multiple agents give us a chance to cross-check the output from different angles, much like asking a second or third pair of eyes to review a design. That does not make the system perfect, but it does make the workflow sturdier, especially when the task touches security, testing, or production behavior.
For developers, this changes the job in a subtle but important way. Instead of writing every line alone, you begin to think like a conductor who sets the tempo, assigns the sections, and listens for where the harmony breaks. Orchestration becomes a skill: you decide which agent should do what, when they should hand work off, and how to tell whether the result is good enough to trust. Over time, that makes the developer less of a solo coder and more of a coordinator of intelligent labor.
If you are wondering whether this is too abstract, the answer usually becomes clear the first time you watch an AI agent team handle a messy task end to end. One agent finds the clue, another turns it into code, and another catches what the first two missed. That collaboration is why AI agent teams are not just a nicer interface; they are a new way to build software, where the value comes from how well the agents work together.
Developer Role Shift
The most visible change with AI agent teams is not that developers write less code; it is that they start spending more time deciding how the code gets made. That is the real developer role shift, and it can feel strange at first because the familiar rhythm of opening an editor and working line by line begins to give way to something more like directing a small crew. Instead of being the person who holds every task in their head, you become the person who frames the goal, breaks the work apart, and keeps the pieces moving in the same direction. If you have ever wondered, how does a developer actually work with AI agent teams in practice?, the answer begins here: by moving from solitary execution to thoughtful orchestration.
This shift changes the shape of your day in a very practical way. A solo coder often jumps between discovery, implementation, testing, and cleanup, carrying each concern from start to finish. An orchestrator does still understand the code, but they also learn to assign work based on strengths, like sending one agent to inspect logs, another to draft a fix, and another to check whether the fix breaks something else. That does not make the developer less technical; it makes them more strategic. The skill becomes knowing which problem belongs to which helper, and in what order the helpers should speak so the whole system keeps its balance.
That is where AI agent teams start to feel less like a novelty and more like a new working style. The developer role shift is partly about trust, because you are no longer the only source of judgment in the loop. You still need to verify the result, but now you are also comparing outputs, spotting gaps, and deciding whether the team has covered enough ground. Think of it like planning a road trip: one person can drive, but someone else might check the weather, another might map the route, and another might watch for detours. The journey is smoother because each person handles a different kind of attention, and AI agent teams bring that same division of labor into software work.
Over time, this changes what good developers are praised for. They are not only valued for typing quickly or knowing syntax from memory. They are valued for designing the workflow, asking the right questions, and catching where an agent might confidently rush past an important detail. In that sense, orchestration becomes a professional strength all its own. A developer who can coordinate agents well can move through messy tasks with more structure, because they know when to ask for research, when to ask for implementation, and when to ask for review. That is a subtle but powerful upgrade, especially on work that needs both speed and care.
The deeper lesson is that the developer is still central, but the job around that center is expanding. You are no longer just the builder at the keyboard; you are the guide who keeps the build from drifting, the editor who trims bad assumptions, and the coordinator who makes sure every specialist contributes at the right moment. That is why the rise of AI agent teams matters so much: it does not remove the developer from the process, but it does elevate the developer into a role that looks more like orchestration, judgment, and steady direction. And once that shift starts to make sense, the next question becomes how to design the workflow itself so these agents work together without getting in each other’s way.
Break Work Into Agents
Once you start thinking like an orchestrator, the next question is very practical: how do you break work into agents without turning the process into noise? This is where AI agent teams become useful in a very concrete way. Instead of asking one agent to do everything, we give each agent a narrow job, a clear finish line, and a sensible order to work in. That small change can make a messy task feel much more manageable, because the work stops being one giant blur and becomes a set of smaller, understandable moves.
The easiest way to picture this is to imagine a relay race. One runner starts with the problem, another carries it through the middle, and a third finishes with a final check. In an AI agent team, one agent might gather context, another might draft a solution, and a third might review the result for mistakes or side effects. What are AI agent teams if not a way to let each helper do the kind of thinking it does best? That is the heart of breaking work into agents: we match the shape of the task to the strengths of the worker.
At first, this may feel more complicated than asking one chatbot for an answer, and that concern is healthy. A single agent can seem simpler because you only have one conversation to manage, but simplicity can hide confusion when the task gets bigger. When we split work into agents, we reduce the chance that one model will rush from diagnosis to solution without enough checking in between. One agent can read logs, another can trace the code path, and another can test the fix against the original bug. The handoff between them creates a natural pause, and that pause often catches mistakes before they spread.
The trick is to define each agent by purpose, not by vague ambition. A research agent gathers facts from documentation or code history, a coding agent turns the plan into implementation, and a review agent looks for missing cases, broken assumptions, or risky changes. Each role should answer one clear question, and each question should move the project forward in a visible way. That is how AI agent teams stay useful instead of becoming a pile of overlapping opinions. When roles are clean, the output from one agent becomes the input for the next, like stepping stones across a stream.
This also changes how we think about the order of work. Sometimes the best sequence is investigate, then propose, then verify. Other times we need a quick scan first, then a deeper analysis, then a final polish. The point is not to rigidly divide every task the same way, but to shape the workflow around the actual problem in front of us. How do you break work into agents in real life? You start by asking which parts need separate attention, which parts can happen in parallel, and which parts must wait for another agent’s result before they can begin.
That kind of planning pays off because it keeps each agent from wandering outside its lane. If one agent is responsible for finding the root cause, it should not also be asked to make design decisions, write the patch, and judge the test coverage all at once. Narrow tasks create clearer outputs, and clearer outputs are easier for the next agent to use. In practice, this means AI agent teams work best when we treat them like specialists in a workshop rather than like interchangeable generalists. The better we separate the work, the less each agent has to guess.
Once this pattern clicks, the benefit becomes easy to feel. We stop hoping one agent will magically solve everything, and we start building a small pipeline of focused helpers that can carry a task from confusion to completion. That is the real power of breaking work into agents: it gives the developer a way to direct attention with precision, keep quality checks in the loop, and make AI agent teams feel less like experiments and more like a reliable way to ship work.
Set Guardrails and Reviews
Once we start giving AI agent teams real work, the next challenge changes shape. The problem is no longer only speed; it is drift, where a helpful agent slowly wanders outside the task, invents assumptions, or makes a change that looks right but breaks the bigger picture. That is why guardrails and reviews matter so much. Guardrails are the rules and limits that keep an agent inside a safe lane, and reviews are the checkpoints where we pause and inspect the work before we trust it. How do you keep AI agent teams from drifting off course? We give them boundaries first, then we check their output with care.
Think of guardrails like the painted lines on a road at night. They do not drive the car for you, but they stop you from veering into trouble when visibility gets poor. In AI agent teams, those lines might be a clear scope, a list of allowed files, a required test to run, or a reminder not to change business logic without explanation. The point is not to make the agent timid; the point is to make its movement predictable. When the boundaries are clear, orchestration becomes easier because every agent knows where its job begins and ends.
The simplest guardrail is a well-written task prompt. A prompt is the instruction we give an AI agent, and a good one names the goal, the limits, and the expected result in plain language. If we ask for a bug fix, we can also tell the agent to preserve existing behavior, explain any risky change, and stop if the evidence is unclear. That kind of framing sounds small, but it changes the whole conversation. AI agent teams work best when we treat instructions like a contract: specific enough to guide action, but narrow enough to prevent guesswork.
Reviews add the next layer of protection, and this is where the workflow starts to feel mature. A review is a deliberate check by another agent or by a human developer to see whether the work actually matches the goal. One agent might write the patch, but another agent can read it with fresh eyes and ask, “Does this handle the edge case?” or “Did we change something we did not mean to change?” That second look catches the sort of mistake that confident first drafts often miss, especially in AI agent teams where each helper may sound certain before it is fully sure.
This is also where acceptance criteria become useful. Acceptance criteria are the conditions that tell us whether the work is done well enough to ship, and they give the review a measurable target instead of a vague feeling. For example, a fix might need to pass tests, preserve an existing API (application programming interface, the contract other software uses to talk to your code), and leave no warnings in the logs. When those checks are written down early, the review stops being a guessing game. We can compare the agent’s output against the standard instead of relying on intuition alone.
Human review still matters, even when the agents seem capable. A developer can notice product context, user impact, or subtle tradeoffs that a model may miss, and that perspective is often what saves a project from a technically correct but practically awkward change. The strongest AI agent teams do not try to remove people from the loop; they give people better leverage. We let agents handle the first pass, then we use reviews to confirm, correct, or redirect before the result reaches production.
That combination of guardrails and reviews turns orchestration from an experiment into a habit. The agents can move faster because they are not guessing as much, and the developer can trust the workflow because it has built-in checkpoints. In practice, that means fewer surprises, cleaner handoffs, and more confidence when the work finally leaves the team’s hands. Once that rhythm starts to feel natural, we can begin shaping the deeper question of how these teams make decisions together.
Measure Speed and Quality
When we start using AI agent teams, the first temptation is to ask whether they feel faster. That question matters, but it is only half the story. If we want to know whether the workflow is actually working, we need to measure speed and quality together, because a team that moves quickly but leaves a trail of fixes behind it is not really helping us. The useful question is not, “Did the agents finish?” but, “Did they finish quickly enough, and did the result hold up?”
Speed, in this setting, means more than how fast a model types. It includes the time it takes to go from a problem to a useful draft, the time between agent handoffs, and the total cycle time, which is the full span from request to finished result. That matters because AI agent teams often save time in small, invisible places: one agent gathers context while another prepares a patch, and a third reviews the work without making the first two start over. When we measure speed this way, we see where orchestration really helps and where it quietly adds friction.
Quality deserves equal attention, because a fast answer that needs heavy repair is still expensive. In practice, quality means the work is correct, complete, and safe enough for the next step. We can watch for simple signs such as test pass rate, review findings, and the amount of rework needed after the first pass. If an agent team produces code that looks polished but repeatedly misses edge cases, then the quality signal is telling us something important, even if the output arrived quickly.
So how do you measure speed and quality without turning the process into a spreadsheet puzzle? The trick is to compare the work before and after the agents enter the picture. You can look at how long a task used to take, how many handoffs it needed, how many review comments it generated, and how often the final result had to be redone. That gives you a practical baseline. Once you have that baseline, AI agent teams stop feeling like a vague productivity boost and start looking like a system you can observe, improve, and trust.
It also helps to measure at the right level. If you only track raw output speed, you might miss the extra time spent cleaning up mistakes later. If you only track quality, you might miss a workflow that is technically safe but too slow to be useful. A balanced view might include time to first useful result, number of defects caught before release, and how often a human has to step in to repair the agent’s assumptions. Those numbers tell a fuller story than any single metric alone, especially when several agents are sharing the work.
This is where orchestration becomes more than a management idea. As the developer, you are not only asking agents to do tasks; you are tuning the system so the team delivers both momentum and reliability. If one agent consistently slows down the process, we can see it. If another agent improves review quality but adds too much waiting, we can see that too. That feedback loop is what turns AI agent teams into a real workflow instead of a clever demo, and it gives us a way to ask a very human question: are we getting better results, or only busier ones?
The best part is that measurement does not have to feel cold or mechanical. It can feel like learning the rhythm of a new band, where we notice which players speed things up, which ones keep the tune steady, and where the timing slips. Once we can measure speed and quality side by side, we get a clearer picture of when to add another agent, when to simplify a handoff, and when to let a human review take the lead. From there, the next challenge is less about counting results and more about deciding how the agents should choose their own next move.