Understand the Generated Intent
Before we inspect line one for bugs, we need to answer a quieter question: what was this AI-generated code trying to do in the first place? That matters because code review is not only about spotting mistakes; it is about checking whether the implementation matches the intended job. When you review AI-generated code like a senior software engineer, you start by reading for intent the way you would read a note left on a machine before opening the cover.
This first pass is about building a mental model, not judging quality yet. We look at the names, the structure, the comments, and the surrounding context to understand the shape of the solution. Is the code trying to transform data, protect an edge case, connect two services, or automate a repetitive task? The answer guides everything that comes next, because a piece of AI-generated code can be technically correct and still be wrong for the problem it was asked to solve.
A helpful question at this stage is, “What is this AI-generated code trying to accomplish?” That question keeps us from getting distracted by style before meaning. If the function is long, we ask whether the length reflects a complex requirement or whether the model wandered into overbuilding. If the code is short, we ask whether it is elegant or whether it quietly skipped an important rule. In other words, we are comparing the code’s behavior with the job it was meant to perform.
To do that well, we need to reconstruct the original intent from clues. The prompt, the variable names, the input and output types, and even the order of operations all tell a story. For example, if we see a parser that trims whitespace, normalizes casing, and rejects malformed input, we can infer that correctness and robustness mattered more than speed. If we see a helper that uses several nested branches and repeated checks, we may be looking at a model trying to satisfy a detailed set of constraints rather than writing the cleanest possible path.
This is where code review becomes more human than mechanical. AI-generated code often mirrors the wording of its instructions, so the code may be precise in one place and strangely vague in another. A senior reviewer asks whether those gaps are harmless or dangerous. Did the model infer a default that the product actually needs to make explicit? Did it assume a happy path while the real system expects messy inputs? Did it create an abstraction because the prompt hinted at reuse, or because it misunderstood the domain? That line of questioning helps us separate deliberate design from accidental output.
Understanding intent also protects us from fixing the wrong thing. If we only chase obvious issues, we may polish a function that was built on the wrong assumption. Imagine repairing a bridge without checking whether it was supposed to cross the river at all; the structure can look solid and still lead nowhere. In AI code review, that means we ask whether the code matches the feature, the workflow, and the business rule before we debate micro-optimizations or refactoring choices. This is one of the most important habits in reviewing AI-generated code because it keeps us aligned with the problem, not just the syntax.
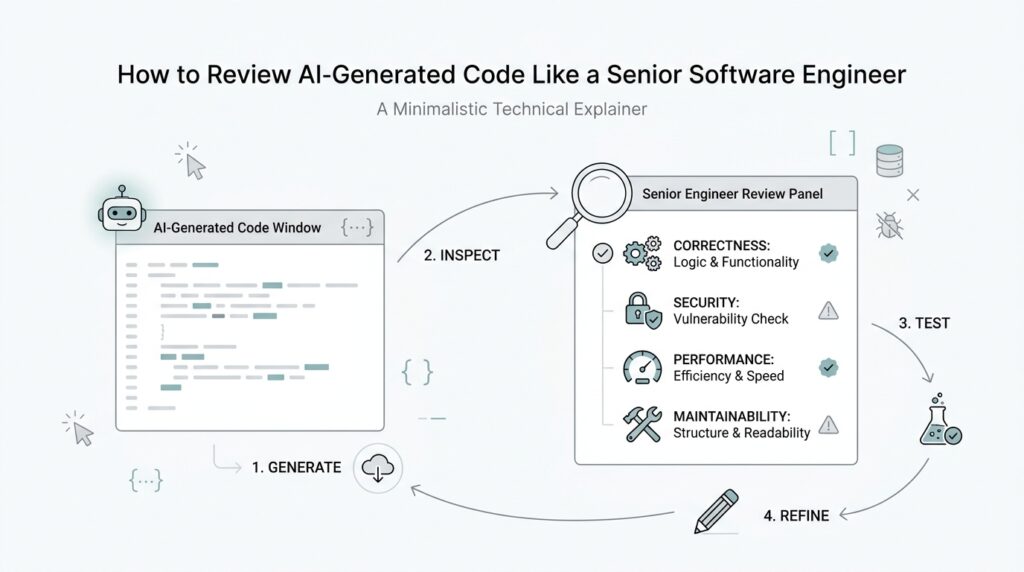
Once we have that intent in view, the rest of the review gets much sharper. We can judge whether the implementation is faithful, whether it overreaches, and whether it leaves dangerous assumptions hidden in plain sight. That shared understanding becomes the foundation for every later check, from correctness to maintainability, and it is what turns code review into thoughtful engineering rather than a search for surface-level flaws.
Check Architecture and Design
Now that we know what the AI-generated code was trying to do, the next question is whether it chose the right shape to do it. This is where code review moves from reading individual lines to checking the whole building plan. A function can look tidy on its own and still sit inside a design that is awkward, fragile, or hard to grow, which is why architecture and design matter so much in AI-generated code review.
When we look at architecture, we are asking how the parts fit together. Think of it like entering a house after reading the floor plan: you want to know whether the kitchen is near the dining room, whether the stairs make sense, and whether the layout supports the way people actually live. In software, that means checking whether responsibilities are separated well, whether modules depend on each other in sensible ways, and whether the code follows the system’s existing patterns instead of inventing a new little universe. If the AI-generated code creates a new service, helper, or abstraction, we ask whether that structure earns its place or just adds another hallway to a house that was already hard to navigate.
A senior reviewer also checks whether the design matches the scale of the problem. AI-generated code often reaches for patterns that look polished on the surface, but the wrong pattern can make a small task feel heavy and a large task feel brittle. If the code is handling a simple workflow, do we really need multiple layers of indirection, or are we paying an architecture tax for no gain? If the code is expected to grow, does the current design leave room for that growth, or will every new feature require surgery in three different places? These are the kinds of questions that turn code review into architectural judgment instead of style preference.
Another useful lens is consistency with the rest of the system. Good architecture rarely lives in isolation; it has to cooperate with the codebase around it. That means we look for patterns that match existing naming, data flow, error handling, and state management, because AI-generated code can be fluent in one file and out of step in the next. When the new code ignores the project’s usual structure, the mismatch becomes a clue: maybe the model misunderstood the boundaries of the system, or maybe it solved the immediate prompt without respecting the larger design. Either way, the review catches a problem that would be easy to miss if we only tested the happy path.
We also want to see whether the design hides important decisions in the wrong place. A healthy system makes its choices where people can find them later. If the AI-generated code quietly hard-codes behavior, duplicates business rules, or spreads the same logic across several helpers, then the design is making future maintenance harder than it needs to be. In code review, we ask whether the code keeps one job in one place, whether it exposes clear boundaries, and whether the next developer will be able to change it without tracing a maze. That is a big part of reviewing AI-generated code like a senior software engineer, because elegant output can still conceal messy architecture.
We should also watch for missing seams, which are the places where a system can grow, swap parts, or absorb change. Good design leaves room for tests, for configuration, and for future rules that we cannot see yet. If the code assumes one data source, one format, or one execution path without any way to adapt, it may work today and fail the moment reality shifts. So when we review AI-generated code, we are not only asking, “Does this run?” We are asking, “Will this survive the next version of the product, the next edge case, and the next person who has to touch it?”
This is why architecture and design review feels a little like checking the foundation before admiring the paint. We are looking for fit, balance, and room to evolve, because those qualities decide whether the code remains useful after the first merge. Once that shape looks sound, we can move on with more confidence to the finer-grained questions of correctness, maintainability, and the hidden tradeoffs inside the implementation.
Review Edge Cases and Errors
A design can look solid right up until reality brings in the messy cases, and that is where AI-generated code review earns its keep. This is the moment we stop admiring the happy path and start asking what happens at the edges: when the list is empty, when the network drops, when the user clicks twice, or when the input arrives in a shape nobody expected. In code review, edge cases are the unusual situations that sit at the boundaries of normal behavior, and they often reveal whether the code was written for a demo or for a real system.
So how do we review AI-generated code for edge cases without getting lost in every hypothetical? We begin by tracing the inputs and outputs like a small story. If a function accepts a name, a file, or an API response, we ask what happens when that value is missing, blank, zero, too large, duplicated, or malformed. AI-generated code often assumes a neat world, so a senior reviewer checks whether the code still behaves when the world gets messy.
This is also where we look for gaps between the prompt and the implementation. The model may handle the most obvious path correctly, then quietly skip the weird but important ones, like a form submission with an empty field or a data record with an unexpected type. If the code says it validates input, we should verify that every branch gets the same care, not just the first one we happened to read. A good code review asks, “What would break if this assumption were false?” and then follows that thread until the answer feels real.
Error handling deserves the same attention, because a system is not only judged by what it does when things go right. Error handling means the way software detects, reports, and recovers from problems, and AI-generated code can be especially fragile here. Sometimes it swallows an exception and keeps going as if nothing happened, which can hide a real failure behind a false success. Other times it raises an error without enough context, leaving the next developer to play detective in the logs.
When we review error handling, we want to know what the user sees, what the logs record, and whether the system can recover safely. If a database write fails halfway through, does the code leave behind partial state? If a request times out, does it retry, back off, or fail fast with a clear message? These questions matter because AI-generated code can produce the appearance of control while missing the practical details that keep production systems stable.
The tricky part is that edge cases do not always announce themselves as dramatic failures. Sometimes they show up as small mismatches: a date at the end of the month, a permission that is missing, a duplicate record, a rate limit, or a file that is present but unreadable. Those situations sound rare until you work in a real product, where they arrive more often than we expect. Good AI-generated code review looks for these cracks early, because the code that handles them well usually reflects careful thinking everywhere else too.
A helpful habit is to walk the code through one failure at a time and imagine the full chain reaction. If this value is null, what branch runs next? If this call fails, what gets cleaned up? If this operation is repeated, does it stay safe or create a new problem? That kind of code review keeps us close to reality, and it gives us a clearer picture of whether the AI-generated code is resilient or merely optimistic.
By the time we finish this pass, we are not just checking for bugs. We are checking whether the code can survive the rough edges of actual use, which is one of the clearest signs of strong software engineering. Once those cases feel covered, we can move forward with more confidence knowing the implementation has been tested where it is most likely to bend.
Validate Test Coverage
Once we have traced the rough edges, the next question is whether the tests actually walk those paths. This is where test coverage matters in AI-generated code review: it tells us not only whether the code runs, but whether anyone has bothered to prove that it behaves under pressure. What does test coverage really tell you when the code came from an AI model? In plain language, it shows us how much of the code a test suite touches, but the senior-level question is whether it touches the right parts.
That distinction matters because a high percentage can be misleading. A test can visit a line of code without checking anything meaningful, the way a guest can walk through a house without noticing the broken window. In code review, we want more than motion; we want evidence. If the AI-generated code adds branches, helpers, or fallback logic, we look for tests that exercise each important path and confirm the expected outcome, not just the fact that the function returned something.
A good place to start is with the most important behavior, the kind users would notice if it failed. If the code transforms input, we want tests for ordinary values, empty values, malformed values, and boundary values, which are the smallest and largest cases the code can handle. If the code talks to another service, we want tests that prove it reacts correctly when that service succeeds, times out, or sends back an unexpected response. In an AI-generated code review, this is where we separate “tested” from “trusted.”
We also need to ask what kind of tests are present, because different tests tell us different stories. A unit test checks one small piece of code in isolation, while an integration test checks how several parts work together. A regression test protects against a bug that already happened once, so it does not sneak back later. If the AI-generated code includes only unit tests, that may be enough for a pure helper function, but it may leave bigger workflow problems invisible. If it includes only broad integration tests, the suite may miss the precise branch where the bug actually lives.
This is why test coverage is not just a number in a dashboard. We want to see whether the tests reflect the real shape of the code and the real risks in the system. If a function contains a long error-handling branch, we should expect a test for that branch, not only for the happy path. If the code contains a tricky condition, such as “if the input is present but incomplete,” the test suite should prove that the branch does what the product needs. Senior reviewers use those clues to judge whether the AI-generated code was truly understood or merely exercised on the surface.
Another useful question is whether the tests are specific enough to fail for the right reason. A vague test can pass even when the code is wrong, which creates a false sense of safety. Strong AI-generated code review looks for assertions, which are the checks inside a test that compare expected behavior with actual behavior, and we want those assertions to be clear and meaningful. If a test only confirms that a function returned without crashing, it may miss the more important question of whether the return value was correct.
We should also look for gaps between the code and the tests around change. If the implementation introduced a new branch, new data shape, or new dependency, did the tests evolve with it? AI-generated code often writes the implementation first and leaves the surrounding safety net thin, so this is one of the easiest places to catch a weakness. Good test coverage grows with the code; it does not trail far behind like an afterthought.
In the end, validating test coverage is about confidence, not vanity metrics. We are asking whether the tests tell the same story as the code, whether they cover the paths that matter, and whether they would alert us if the implementation drifted tomorrow. That habit makes AI-generated code review stronger because it turns tests into a real safety net instead of decorative paperwork. Once the suite proves the important behavior, we can trust the code a little more and move on knowing the risk is smaller than it first looked.
Audit Security Risks
Security is where the stakes stop feeling theoretical. After we have checked intent, design, edge cases, and tests, we turn to the harder question: could this AI-generated code expose people, data, or systems in a way we will regret later? That is the heart of auditing security risks in AI-generated code review. A feature can behave correctly and still leak information, trust the wrong input, or hand an attacker a shortcut through the system. When we review with a security lens, we are not looking for paranoia; we are looking for quiet mistakes that become expensive in production.
The first place we look is trust. In security, a trusted input is data we believe is safe, while an untrusted input is anything a user, service, or file can influence. AI-generated code often treats input as friendlier than reality allows, so we check whether it validates what comes in before using it. What happens if a password, filename, email address, or query string contains unexpected characters? If the code passes that data straight into a database, shell command, or HTML page, we may be opening the door to injection, which is when harmful text gets interpreted as code instead of content.
This is also where we inspect output, because security does not end when data leaves the function. If the code displays user content, writes logs, or returns an error message, we ask whether it might reveal secrets by accident. Secrets are sensitive values like API keys, session tokens, and private credentials, and AI-generated code sometimes copies them into places they should never go. A careful reviewer checks for hard-coded secrets, overly chatty logs, and debug messages that could expose internal details. In AI-generated code review, these leaks are easy to miss because they often look like harmless convenience.
Authentication and authorization deserve separate attention, even though they sound similar. Authentication means proving who someone is, while authorization means deciding what that person is allowed to do. AI-generated code may check one but forget the other, especially in routes, admin tools, or helper functions that assume a higher privilege than the caller actually has. So we ask a simple but powerful question: who is allowed to do this, and does the code enforce that answer every time? If the logic depends on the caller being well-behaved, we should treat that as a security risk, not a shortcut.
From there, we look at dependencies, which are the outside libraries and packages the code relies on. A dependency is like a borrowed tool: useful, but only if we know where it came from and how safely it works. AI-generated code may choose popular packages without considering whether they are necessary, maintained, or trustworthy. We also check whether the code pulls in features it does not use, because every extra dependency expands the attack surface, meaning the number of places an attacker might try to exploit. A leaner design often gives us a safer one.
Data handling is another place where security risks hide in plain sight. If the code stores files, moves records, or builds URLs, we want to know whether it protects sensitive data at rest and in transit. Data at rest means data saved on disk or in a database, while data in transit means data moving across a network. AI-generated code can forget to encrypt, redact, or separate sensitive values from ordinary ones, especially when the prompt focused on speed rather than protection. The reviewer’s job is to ask whether the code treats private information like private information.
We also want to think like an attacker for a moment. That does not mean becoming suspicious of everything; it means asking how someone might misuse a feature in an unexpected way. Could repeated requests overwhelm the service? Could a crafted path reach the wrong file? Could a permissive fallback expose a more powerful operation than intended? These are the kinds of questions that make security review feel less abstract and more concrete. If you are wondering how to review AI-generated code for security risks, this is the mindset that pays off: assume the code will be tested by creative people, not cooperative ones.
The best security audit leaves us with a clearer map of where the code is strong and where it needs guardrails. We have checked whether inputs are trusted too early, whether outputs reveal too much, whether permissions are enforced, and whether dependencies or data flows widen the risk. That kind of AI-generated code review does more than block obvious mistakes; it helps us shape code that can survive real use without turning convenience into exposure. Once those risks are visible, we can move forward with a much steadier sense of what the code is actually safe to do.
Assess Readability and Maintainability
After we have checked the code’s intent, design, edge cases, tests, and security, the next question is almost disarmingly practical: can another human live with this code? Readability and maintainability are where AI-generated code either earns trust or starts creating quiet friction. If you have ever opened a file and felt your shoulders tense up, you already know the problem we are trying to avoid. Good AI-generated code review asks whether the code can be understood today and changed safely next month.
Readability is the code’s first conversation with the next person who touches it. It is the difference between a street with clear signs and a maze of alleyways that all look the same. When we review readability, we look at names, structure, and flow, because those are the clues that let a reader follow the logic without stopping every few lines. If a variable name says what it stores, if a function name says what it does, and if the order of steps feels natural, the code begins to explain itself. That matters in AI-generated code review because even correct code can waste time if it forces everyone to decode it.
A useful test is to read the code aloud in plain language. Do the sentences sound like something a teammate would say, or do they sound like a machine assembling phrases from fragments? When AI-generated code is hard to read, it often reveals itself through dense nesting, vague names, or tiny helpers that hide more than they clarify. A senior reviewer notices when a function is trying to do five jobs at once, because that is the moment readability starts slipping into maintainability trouble. How do you assess readability and maintainability in AI-generated code? You start by asking whether the path from top to bottom feels like a guided walk or a scavenger hunt.
Maintainability is what happens after the first reader gets through the file. It asks whether the code will still be pleasant to change when the requirements shift, the product grows, or the original author is unavailable. AI-generated code can look polished on day one and still be expensive to maintain if it repeats logic, couples unrelated concerns, or hides business rules in a way that is hard to update. We are not only checking whether the code works now; we are checking whether future changes will feel like adding a new room or tearing down a wall.
One of the clearest maintainability signals is how much duplication the code creates. Duplication means the same rule, condition, or transformation appears in several places, which makes future changes risky because every copy has to stay in sync. If we see repeated blocks, we ask whether they belong in one shared place or whether the repetition is accidental drift from the model. In AI-generated code review, this is a common trap: the code may look straightforward, but every extra copy quietly increases the chance of inconsistency later.
We also look for boundaries that feel easy to cross. A maintainable file usually separates decision-making from detail, and it keeps configuration, business logic, and formatting from mixing together like ingredients in the wrong bowl. When those lines blur, the next developer has to trace the code just to make a small change, and that slows everyone down. Good readability supports maintainability here because clear structure makes future refactoring less frightening.
Comments deserve a careful read too, but not because more comments are always better. The best comments explain why something exists, especially when the code contains a rule or tradeoff that would otherwise look strange. If a comment merely repeats what the line already says, it adds noise instead of clarity. In AI-generated code, that kind of filler can hide the places where a real explanation is actually needed, so we want comments to illuminate the tricky parts rather than decorate the obvious ones.
We should also ask whether the code invites safe change. Can we rename a field without rewriting half the file? Can we add one new case without disturbing the rest? Can we move a piece into a smaller function without changing behavior? Those questions matter because maintainability is really about reducing fear. When a codebase is readable, the next step feels manageable; when it is not, even a small edit can feel like stepping onto thin ice.
By the time we finish this pass, we are looking for code that reads cleanly, changes predictably, and leaves a clear trail for the next person. That is the heart of AI-generated code review at this stage: not perfect prose, but code that a real team can understand, extend, and trust without fighting it every time the product evolves.



