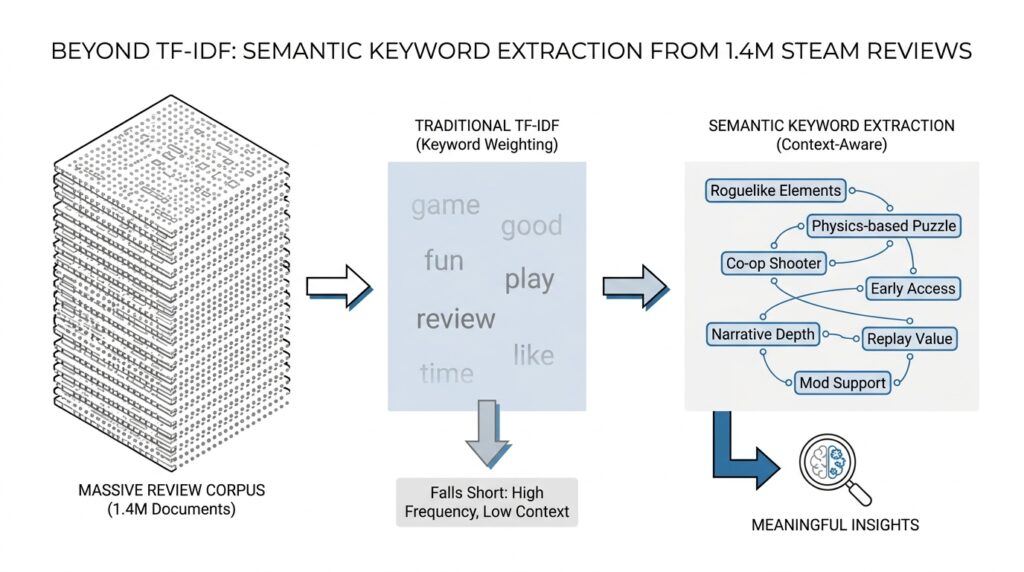
Why TF-IDF Misses Context
TF-IDF, or term frequency–inverse document frequency, looks powerful at first because it turns text into a neat scorecard of words. But that neatness comes with a cost: in the usual bag-of-words setup, the model treats a document like a pile of tokens, so word order, phrasing, and most of the sentence structure disappear. Scikit-learn’s documentation says a collection of unigrams cannot capture phrases or multi-word expressions and effectively ignores word-order dependence, and Le and Mikolov similarly note that bag-of-words features lose ordering and ignore semantics.
That blind spot matters the moment we ask what a review actually means. If you read a line like “not bad at all,” the model does not hear the little turn that changes the feeling of the sentence; it only sees words and weights, not the reversal created by nearby context. That is an inference from TF-IDF’s order blindness, and it explains why TF-IDF misses context when reviews rely on negation, contrast, or sarcasm.
TF-IDF also decides importance by rarity, which is helpful but incomplete. The inverse document frequency, or IDF, boosts terms that appear in fewer documents and downweights terms that show up everywhere, because document-level rarity often separates useful signals from background noise. But rarity is not the same as meaning: a word can be rare because it is informative, or rare because it is a typo, a joke, or a one-off quirk in a review.
This is why people often reach for n-grams, meaning short word sequences such as “very good” or “frame rate.” They bring back a little local order because the model can treat a two-word phrase as its own feature, which helps keyword extraction catch patterns that single words would miss. Even then, scikit-learn warns that bag of words and bag of n-grams still destroy most of the document’s inner structure and much of the meaning carried by it, so the gain is real but limited.
You can feel the limitation most clearly when a review’s tone depends on how words work together. A repeated word can look important to TF-IDF because frequency rises, but the model still cannot tell whether the repetition signals frustration, emphasis, or a playful quote. In that sense, TF-IDF is great at spotting surface-level importance, yet weak at reading intent, and that is exactly where context starts to matter.
So when we use TF-IDF on 1.4 million Steam game reviews, we should treat its output like a useful sketch rather than a full portrait. It can tell us which terms stand out in one review against the wider collection, but it cannot tell us whether those terms are praise, complaint, irony, or a sharp contrast with the words around them. That gap is the reason we need a representation that can carry nearby words, phrases, and broader sentence structure along with the keywords themselves.
Prepare the Review Corpus
Before we can extract meaningful keywords from 1.4 million Steam game reviews, we need to turn that messy stream of player thoughts into a review corpus, which is just a structured collection of text we can analyze. This is the point where raw comments stop feeling like a pile of screenshots and start behaving like a library. What do we actually keep, what do we trim away, and what should stay untouched because it carries meaning? Those are the questions that shape the rest of the pipeline.
The first task is to collect the reviews in a consistent format, because keyword extraction works best when every entry looks like it belongs in the same conversation. A review corpus usually includes the review text itself, but it can also include useful metadata, meaning extra information such as game title, review date, recommended or not recommended label, and playtime. That extra context matters because the same phrase can mean something different in a short casual complaint than it does in a long detailed critique. If we preserve that structure early, we give ourselves options later instead of locking the data into one narrow shape.
Next, we clean the text without scrubbing away its personality. Cleaning means removing obvious noise like broken entries, duplicate records, HTML fragments, and formatting leftovers, while keeping the words that reveal tone and intent. This is a delicate step, because reviews are not polished essays; they are little bursts of player emotion, and punctuation, repeated letters, and even slang can carry meaning. If someone writes “soooo slow” or drops a string of exclamation marks, the messiness is part of the message, not a mistake to erase.
From there, we normalize the corpus so that different writing styles start speaking the same language. Normalization means converting text into a more consistent form, such as lowercasing words, standardizing contractions, and deciding how to handle numbers, emojis, and symbols. We also need to think carefully about tokenization, which means splitting text into smaller units called tokens, usually words or short phrases. Should we keep “don’t” together, or split it into “do” and “n’t”? Should “frame rate” stay as a phrase? These choices shape how much context survives the journey.
This is also where we protect important signals that TF-IDF alone tends to flatten. Negation words like “not,” contrast words like “but,” and short intensifiers like “very” may seem small, yet they can completely change how a review reads. If we remove them too aggressively, we risk turning “not worth it” into something that looks much friendlier than it really is. So the review corpus has to be prepared with a light touch: clean enough to be usable, but not so aggressive that we sand away the meaning we are trying to capture.
Once the text is in a stable form, we can decide how to segment it for analysis. In plain language, segmentation means breaking the corpus into pieces that make sense for the task, such as one review per document, or one review plus its metadata as a single record. That choice sounds administrative, but it changes the story the model can tell. If we keep each review separate, we can compare wording across players; if we group by game, we can uncover shared themes around performance, difficulty, or story quality.
A good corpus also keeps the path back to the source clear. That means every cleaned review should still link to its original record, so we can inspect examples later and see why a keyword appeared important. When we eventually ask, “Why did this term matter here?” we want to answer with evidence, not guesswork. This traceability turns keyword extraction from a black box into a process we can trust and explain.
By the time the review corpus is ready, we have done more than tidy text. We have built the foundation that lets richer representations do their work, because now the data carries context instead of losing it at the door. That is the quiet but crucial step that makes the next stage possible: reading Steam reviews as connected language, not isolated word counts.
Use Embedding-Based Keywords
Now the question changes from what words appear often? to which words actually feel like the review? That is where embedding-based keywords enter the story. An embedding is a numeric representation of text that places similar meanings near each other in vector space, and Sentence Transformers is built to produce those embeddings and compare them with similarity measures such as cosine similarity. In practice, that means we are no longer staring at isolated word counts; we are asking whether a phrase and a review point in the same semantic direction.
If TF-IDF gave us a rough sketch, embeddings give us a map with neighborhoods. The reason this helps is that a good embedding keeps related phrases close even when they do not share the same surface words, which is exactly the kind of gap that shows up in Steam reviews. A player might say “lags in boss fights,” while another writes “stutters during combat,” and an embedding-based method can treat those as neighbors because the meaning is similar even though the wording is different. That semantic grouping is what makes embedding-based keywords feel more human than raw term weights.
So how do we extract keywords from embeddings? We start by turning the review into a document embedding and each candidate word or phrase into its own embedding, then we compare them and keep the candidates that sit closest to the document. KeyBERT follows this pattern: it uses BERT-style embeddings and cosine similarity to find sub-phrases in a document that are most similar to the document itself, and its API explicitly computes document and candidate embeddings before ranking keywords or keyphrases. In other words, the review becomes the center of the room, and the best keywords are the phrases that stand nearest to it.
This is a helpful shift for Steam reviews because many of the strongest signals live in small phrases, not single tokens. Words like “frame rate,” “pay to win,” “early access,” and “loading times” carry more meaning as phrases than as separate pieces, and embedding-based keyword extraction is built to preserve that kind of expression. KeyBERT’s design also lets us control candidate phrase length through n-grams, which are short word sequences, so we can search for one-word terms, two-word phrases, or longer chunks depending on how specific we want the keywords to be. The key idea is that we let the embedding decide which candidates actually match the review’s meaning, rather than trusting frequency alone.
That matters because reviews often talk in clusters of meaning. A complaint about “crashes after update,” “broken save files,” and “can’t launch anymore” may never repeat the exact same wording, yet the shared meaning is obvious to a reader. Embedding-based keywords help us surface that shared complaint theme, which makes the output more useful for downstream analysis like topic grouping, sentiment breakdown, or comparing one game against another. Sentence Transformers is explicitly positioned for tasks such as semantic search, clustering, classification, and paraphrase mining, so using it for keyword extraction fits naturally into that broader semantic toolkit.
There is still one careful step here: we should treat the keyword list as a ranked interpretation, not a perfect truth. Two phrases can be close in embedding space for slightly different reasons, and that means the top results still deserve a human glance, especially when a review is sarcastic, messy, or unusually short. But compared with raw frequency, embedding-based keywords give us a much better chance of keeping the reviewer’s intent intact, which is the whole point of moving beyond TF-IDF.
Once we start thinking in embeddings, the rest of the pipeline opens up in a more flexible way. We can rank phrases by semantic closeness, compare reviews by meaning, and even reuse the same representation for grouping similar complaints across the corpus. That gives us a keyword extraction process that feels less like counting scraps and more like listening for themes, which is exactly the kind of shift we need before we move into the next stage.
Cluster Reviews by Themes
With the keywords in hand, we can finally step back and ask a bigger question: what stories are these 1.4 million Steam reviews telling together? This is where review clustering starts to matter. Instead of treating each review as a lone voice, we begin grouping similar voices into shared themes, so a pile of individual comments starts to look like a map of recurring player concerns and praise.
If you have ever sorted a messy desk into stacks, you already understand the basic idea. A cluster is a group of items that are more alike to each other than to the rest of the collection, and a theme is the common idea that gives that group its shape, such as performance issues, difficulty spikes, monetization complaints, or story appreciation. What does it mean to cluster Steam reviews by themes? It means we are looking for reviews that point in the same semantic direction, even if they use different words to say it.
The useful part here is that we are no longer clustering raw text like a bag of words. We are clustering embeddings, which means each review becomes a point in a meaning-rich space where nearby points tend to express similar ideas. Once the reviews live in that space, an algorithm such as k-means can gather them around shared centers, like placing pins on a board and circling the densest neighborhoods. That makes clustering reviews feel less like counting language and more like arranging related experiences side by side.
This is especially helpful for Steam reviews because players rarely use the exact same phrasing. One person might complain about “constant stutter,” another about “frame drops,” and a third about “the game running like a slideshow,” yet all three are talking about the same rough experience. When we cluster reviews by themes, those variations stop working against us and start working together, because the model can recognize the shared meaning behind the wording. That is a major advantage over TF-IDF, which would often separate those comments by vocabulary instead of uniting them by intent.
Of course, clustering is not magic, and the first pass usually needs a human reading of the results. A cluster is only as useful as the label we give it, so after grouping the reviews, we inspect the most representative examples and ask what they have in common. That is how a cluster of “crashes,” “won’t launch,” and “save file corrupted” becomes a clear stability theme, while another cluster of “grindy,” “too hard,” and “unfair bosses” reveals a difficulty theme. The work here is part detective story and part editing pass, because we are translating machine groupings into language that people can actually use.
There is also a practical choice hidden in the setup: how many groups should we create? Too few clusters, and unrelated complaints get mashed together until the theme becomes vague. Too many clusters, and the same idea splits into tiny fragments that are hard to interpret. The right balance usually comes from testing a few settings, reading the results, and choosing the point where the themes are specific enough to be useful but broad enough to tell a coherent story.
Once that balance is right, the payoff becomes clear. Clustering reviews by themes lets us summarize huge review sets, compare games by the kinds of feedback they attract, and spot repeated pain points without reading every single comment one by one. It also gives the earlier keyword extraction work a larger job to do, because the keywords now help explain why each cluster exists and what kind of language keeps pulling reviews into it. From here, we can move from isolated phrases to whole patterns of player experience, which is the real shift that makes the analysis feel alive.
Validate Against Sample Reviews
Once the keyword list is in front of us, the real work begins: we read it against actual reviews and ask whether it still feels alive. Embedding-based keyword extraction works by comparing document embeddings with candidate word or phrase embeddings and ranking them by cosine similarity, which is why systems like KeyBERT can surface phrases that look semantically close to a review even when they do not repeat its exact wording. That is powerful, but it also means we should check a few sample reviews to make sure the top-ranked phrases still match what a human reader would understand. Does this keyword still make sense when we read the full review around it? That one question keeps us grounded.
The easiest way to do that check is to build a small validation set from the Steam review corpus before we trust any large-scale summary. We want a mix of short and long reviews, positive and negative ones, and examples from different themes we already saw in the clustering step, because keyword extraction can look excellent in one corner of the data and weak in another. If a phrase keeps showing up in representative reviews for the same reason, that is a good sign. If it appears only because the model latched onto a repeated but shallow term, the sample reviews will expose that quickly. This is not about proving the model perfect; it is about making sure our Steam game reviews keyword extraction is serving meaning rather than echoing noise.
As we inspect each sample, we are looking for a simple pattern: do the keywords summarize the review, or do they only decorate it? KeyBERT’s default behavior is to extract sub-phrases that are most similar to the document itself, and it can also work with longer n-grams, which means the output often contains useful phrases rather than isolated words. That is helpful, but it also creates a natural test case for humans: if the phrase feels too broad, too generic, or oddly specific in a way the review never supports, we know the ranking needs adjustment. In practice, this is where sample reviews become our compass.
We should pay special attention to edge cases, because those are the places where keyword extraction usually starts to wobble. A sarcastic review can sound positive on the surface while meaning the opposite, a very short review can overemphasize one phrase, and a messy review can repeat a word so often that frequency pretends to be importance. The sample reviews tell us whether our representation is catching the intent or only the surface pattern. If a phrase like “great game” keeps appearing in genuinely negative reviews, that is our cue to look deeper and perhaps tighten the candidate selection or rethink how we interpret the scores.
This is also the moment to separate useful keywords from merely common ones. A term can be semantically close to a document and still be too broad to help us later, especially if it appears everywhere in the corpus. When that happens, we do not throw the method away; we refine it by checking whether the phrase helps us distinguish one kind of review from another. That distinction matters because the goal is not a pretty word cloud. The goal is to extract meaningful keywords from Steam reviews that still carry enough context to explain why players felt the way they did.
A good sample review check usually ends with a small, practical question rather than a grand theory: if we showed this keyword list to another reader, would they recognize the review? If the answer is yes, we are in good shape. If the answer is no, we have learned something valuable about the model, the corpus, or both. And that learning pays off immediately, because every round of validation makes the next batch of keywords sharper, more faithful, and easier to trust.
Automate the Extraction Pipeline
At this point, the notebook can’t stay a notebook for long. Once we know the settings work on a few sample reviews, the real challenge is turning that careful keyword extraction pipeline into something that can walk through 1.4 million Steam reviews without losing its footing. How do we automate the extraction pipeline without flattening the context we worked so hard to preserve? The answer is to make each step repeatable: prepare the text the same way every time, generate embeddings in batches, and rank candidate phrases with the same rules across the whole corpus. KeyBERT is built for this kind of flow, and Sentence Transformers is designed to produce embeddings at scale, including batch-based and multi-process encoding.
What we are really building is a small factory line for meaning. One stage cleans and normalizes each review, another stage turns the review into a document embedding, and a third stage compares that document to candidate words or phrases before ranking the best matches. KeyBERT’s extract_embeddings step makes that structure explicit: it builds document embeddings and candidate word or phrase embeddings from the same input, and it expects the same keyphrase_ngram_range, stop_words, min_df, or vectorizer settings when you later call extract_keywords. That consistency matters because the pipeline stays aligned from one review to the next instead of changing shape halfway through.
Once the steps are clear, we can start thinking in batches instead of one review at a time. Sentence Transformers documents that batch_size can significantly improve encoding speed, and it also supports processing text in chunks with a batch size inside each chunk; it even provides multi-process encoding for running across several CPUs or GPUs. In practical terms, that means we can hand the model a stack of reviews, let it embed them in manageable pieces, and keep the machine busy instead of waiting on one comment after another. That is the quiet trick that makes embedding-based keywords viable at Steam scale.
The next move is to reuse work wherever we can. Instead of re-encoding the same corpus every time we tweak the top-n keyword count or phrase length, we can save the document embeddings and the candidate embeddings, then feed them back into the ranking step while we experiment. KeyBERT’s documentation explicitly shows this pattern: generate embeddings once, then pass them into keyword extraction to speed up tuning. For a huge Steam review set, that kind of reuse turns the pipeline from a slow one-off script into something we can refine without starting over each time.
We also want the pipeline to handle messy reviews with a steady hand. Some entries will be blank, some will be duplicates, and some will be so short that they barely contain a full thought. This is where the earlier text preparation work pays off, because scikit-learn’s CountVectorizer gives us control over tokenization, stop words, and n-gram ranges, while KeyBERT lets us choose candidate phrase lengths through its keyword settings. That means we can keep meaningful phrases like “frame rate” or “early access” in play while ignoring noise that would otherwise crowd the output.
What we end up with is not a single magical function, but a reliable routine: take a review, normalize it, embed it, compare it against candidate phrases, and store the ranked keywords in a format we can inspect later. That rhythm is what makes embedding-based keywords feel trustworthy, because every review goes through the same path and every result can be traced back to the same settings. In other words, the pipeline stops being a pile of ad hoc experiments and becomes a repeatable way to read Steam reviews at scale, one theme at a time.



