Transaction Log Basics
When you first meet a transaction log, it can feel oddly small for something so important. The database does not rush to rewrite table and index files for every insert or update; instead, it first appends a compact record of the change to a log. PostgreSQL calls this write-ahead logging, or WAL, and MySQL’s InnoDB calls the same kind of structure a redo log: a sequential record of changes that can be replayed later. That small shift in workflow is one of the biggest reasons databases can keep write performance steady under load.
The sequence matters, and it is easy to picture once you slow it down. A transaction creates log records, the database writes them in order, and only then does it treat the change as safely committed. Because the log is append-only, the engine can write it more predictably than it can rewrite scattered pages all over the data files. Think of it like writing items in a notebook before reorganizing a filing cabinet: the notebook is faster to update, and the cabinet can wait.
That same notebook is what saves the day after a crash. If the server stops in the middle of work, the transaction log becomes the recovery guide, and the engine replays records for changes that were logged but not yet copied into the main data files. In PostgreSQL, WAL exists so the system can recover from the log after a failure, and MySQL’s redo log serves the same purpose for incomplete transactions. So the log is not only a performance trick; it is also the safety net that lets the database move expensive work out of the critical path.
The rest of the picture lives in memory, where recently changed pages wait their turn. Those pages are often called dirty pages, which means their contents have changed but the database has not yet written them back to disk. Checkpoints help the system decide when to flush those pages gradually instead of all at once, so the log can keep accepting new work while the slower data-file updates happen in the background. This separation between fast logging and slower page writes is a core part of how transaction log basics support durability and throughput at the same time.
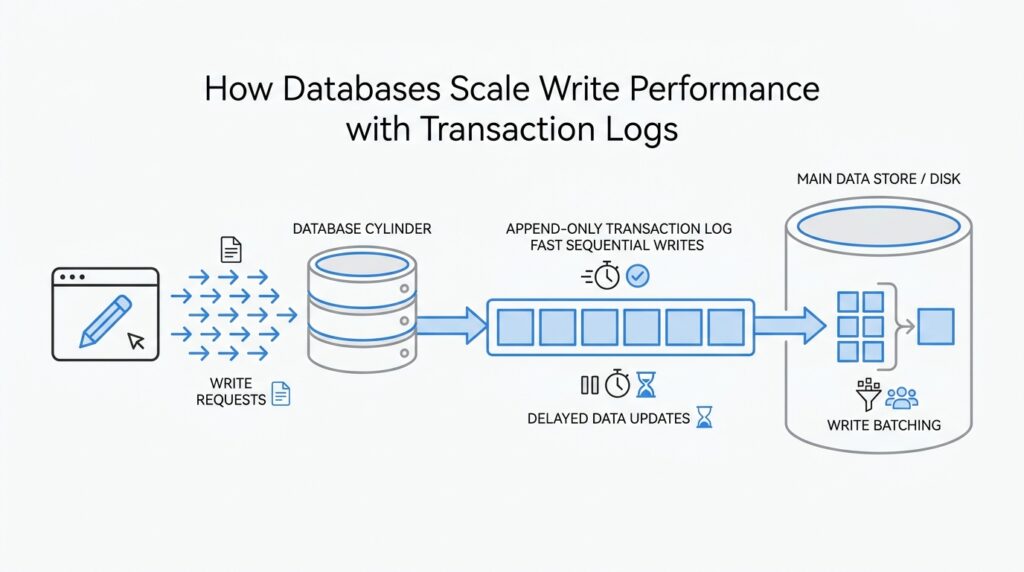
Why does a transaction log help write performance? Because the engine can acknowledge a transaction after a small sequential log write instead of waiting for every related table and index page to be rewritten immediately. That reduces random I/O, which is the kind of disk work that tends to become painful as traffic rises. The log does not erase the cost of persistence; it reorganizes that cost into a smoother, more manageable path.
Once you picture the transaction log as the database’s fast lane, the next pieces of the story start to line up. The real scaling story is about how engines batch those log writes, delay heavier page updates, and keep the main storage structures from becoming the bottleneck. That is the foundation we will build on next.
Append-Only Write Path
Now that we have the log in view, the next question is how the database actually uses it to keep writes moving. The answer is an append-only write path: instead of hunting through existing data files and changing them in place, the engine writes new log records at the end of the log in order. That small choice matters more than it first appears, because sequential appends are far easier for storage systems to handle than scattered rewrites across many pages. When people ask, “Why does a database write faster with a transaction log?” this is the first part of the answer.
Think of it like adding lines to a notebook during a busy meeting. If you always write at the bottom of the page, you can keep moving without stopping to erase old notes or rearrange the whole page. A database follows a similar rhythm with the append-only write path: it records the change first, in the order it arrives, and leaves the heavier housekeeping for later. That ordering gives the engine a calmer, more predictable way to accept a steady stream of inserts, updates, and deletes.
The real advantage shows up under pressure. Random I/O, which means reading or writing data in many different places on disk, tends to slow systems down as traffic grows. Sequential appends, by contrast, are smoother because the storage device can keep moving forward instead of jumping around. In practice, the append-only write path helps the database turn a messy collection of user changes into a tidy stream of log entries, which is a much better fit for high write performance.
This is also where the database protects the rest of its storage from churn. If every update had to rewrite a table page and several index pages right away, the engine would spend much of its time reshuffling old data instead of accepting new work. With append-only writes, the log absorbs the urgent part of the transaction first, and the data files can catch up in the background. That separation is one reason the transaction log supports write performance without asking the main storage layout to do everything at once.
As the system keeps appending, it can also group nearby work together. Batching multiple log records into a single flush reduces the number of times the database has to wait on the storage device, and that waiting is where throughput often slips. The engine is not pretending the cost disappears; it is bundling the cost into larger, more efficient trips. That is a quieter, more scalable way to write than forcing each change to travel alone.
There is another subtle benefit here: the append-only write path preserves a clean history of what happened and when. Because each change lands after the one before it, the database gets a natural ordering that helps with recovery, replication, and replay. The log becomes both the fast lane for incoming writes and the trail the system can follow later if it needs to rebuild state. In other words, the same design that speeds up write performance also gives the engine a reliable story to tell after a failure.
All of this is why append-only behavior is such a central idea in transaction logging. It lets the database accept work quickly, keep storage operations sequential, and postpone expensive page updates until the timing is better. Once you see that pattern, the next step becomes easier to understand: the database is not avoiding work, it is scheduling that work so writes stay fast even when the workload gets busy.
Group Commit Optimization
Imagine a database at rush hour, with lots of small transactions arriving almost at the same moment. If every one of them had to stop the world, force its log records to disk, and wait alone for the hardware to answer, the line would grow quickly. Group commit is the trick that keeps that line moving: the database pauses for a tiny moment so several transactions can share one log flush, which means one expensive trip to storage can serve many commits. Why does group commit help writes? Because it turns many small waits into one larger, shared wait.
That shared wait matters because a flush is the slow part of the journey. A flush means the database forces WAL, or write-ahead log records, out of memory and onto permanent storage so the commit can be considered durable. PostgreSQL describes this as a group commit leader briefly sleeping after it acquires the WAL flush lock, while the other sessions queue up behind it and ride along on the same flush. Even when commit_delay is zero, PostgreSQL notes that some group commit can still happen naturally when multiple sessions reach the flush point during an ongoing flush.
This is where the trade-off becomes visible. Group commit optimization does not make storage faster; it makes the database use storage more efficiently. The cost is a little extra latency for an individual transaction, because the engine may wait briefly for a neighbor to arrive, but the reward is better throughput under load. PostgreSQL’s documentation is explicit about this balance: commit_delay can improve group commit throughput, but it can also add up to that same delay to each WAL flush. That is why the setting only helps when there is enough activity for other transactions to join the batch.
PostgreSQL makes the idea feel almost like a convoy. The first transaction ready to flush becomes the leader, and commit_siblings acts like a minimum crowd size: if too few other transactions are active, the database skips the pause because there is little chance of forming a useful group. In plain language, the engine is asking, “Is anyone else close enough to join me?” If the answer is yes, it waits a little and tries to amortize the cost of the flush across several commits. If the answer is no, it moves on immediately instead of wasting time.
MySQL uses the same basic rhythm, even though the implementation details look different. Its binary log documentation says that binary logging happens in commit order, and the commit path is designed around an ordered flush and commit of outstanding transactions, which is the heart of binary log group commit. InnoDB’s redo log also follows the same broad pattern of appending changes as they happen, then replaying incomplete work during recovery, so the storage engine can keep accepting writes without rewriting table pages immediately. The common idea is simple: gather nearby work, flush once, and let many transactions benefit from that single pass.
That is the deeper lesson here. Group commit is not a special feature reserved for extreme systems; it is one of the quiet scheduling tricks that lets transaction logs scale write performance without turning every commit into a separate disk event. When the workload is light, the database keeps moving. When the workload gets busy, the engine starts bundling commits together so the transaction log can stay fast, sequential, and predictable. Once you see that pattern, the next step is easier to understand: the database is not avoiding durability, it is choosing the best moment to pay for it.
Checkpoints and Log Cleanup
Once the transaction log has been doing its quiet, steady work, a new worry appears: what stops it from growing forever? That is where checkpoints and log cleanup step in. A checkpoint gives the database a fresh milestone where the main data files are brought up to date with the log, so the engine can later retire log records it no longer needs. In PostgreSQL, a checkpoint flushes dirty data pages and writes a checkpoint record, and after that point older WAL segments can be recycled or removed; in MySQL InnoDB, redo log data is appended as changes occur and the oldest data is truncated as the checkpoint advances.
You can think of a checkpoint as the moment when the database says, “We have caught the filing cabinet up to this page in the notebook.” That does not mean every page in memory gets written all at once in a dramatic burst, because the engine tries to spread the work out and keep the write path smooth. PostgreSQL documents that checkpoint activity is throttled so the I/O load begins at checkpoint start and finishes before the next one is due, which helps reduce performance swings. MySQL describes the same broad idea from the redo-log side: as the checkpoint progresses, older redo data becomes eligible to fall out of the active working set.
The part that often feels tricky is that log cleanup is not the same thing as deleting history at random. The database only reclaims log space after it has enough proof that the corresponding changes are already safe in the data files. PostgreSQL says that once a checkpoint establishes the redo point, log segments before that point are no longer needed and can be recycled or removed; InnoDB describes checkpoint progress the same way, with the oldest redo data being truncated as the system moves forward. In plain language, the engine keeps the recent past close at hand and sends the older past to storage when it is no longer needed for recovery.
So what does log cleanup buy us in everyday terms? It keeps the active transaction log small enough to manage, which matters because recovery has to scan only what is still relevant. PostgreSQL’s documentation ties checkpoints to crash recovery by saying the latest checkpoint tells recovery where to begin redo, and MySQL likewise starts recovery from the latest checkpoint LSN, the log position that marks the recovery starting line. That means checkpoints are doing two jobs at once: they protect durability and they trim away log sections that no longer need to stay hot.
This is also why checkpoints can feel like a trade-off rather than a free win. If the database waits too long, the log grows and recovery can take longer; if it checkpoints too aggressively, it spends too much time pushing dirty pages to disk. PostgreSQL explicitly notes that checkpoint I/O can be significant, which is why it is paced, and MySQL’s redo log capacity settings similarly influence how aggressively dirty pages are flushed and how much space the redo log occupies. In other words, log cleanup is really a balancing act: enough cleanup to keep recovery and storage sane, but not so much that write performance starts to stumble.
What happens to the transaction log after a checkpoint? It becomes less like a growing diary and more like a well-managed shelf, where older volumes can be moved aside once the current chapter is safely on the page. That is the rhythm to keep in mind as we move forward: the database writes fast because the log absorbs the urgent work, and checkpoints keep that log from turning into an endless backlog.
Isolate Logs on Storage
At this point, the story changes from “what is the log?” to “where should it live?” When the transaction log sits on the same storage as table and index files, commit-time flushes and checkpoint flushes have to share the same I/O path. PostgreSQL’s WAL docs say only the WAL file needs to be flushed to commit, and checkpoints later flush dirty data pages; MySQL’s redo log follows the same pattern of appending changes and truncating old data as checkpoints advance. The important idea is that the log is the urgent path while the data files are the slower background path.
That is why isolating logs on storage can help write performance. This is an inference from the write pattern: if the log and the data files compete on one device, a burst of page flushes can interfere with the small sequential writes the log depends on, and the reverse can happen too. By giving the transaction log its own volume, you reduce that cross-talk and make WAL flushes more predictable. PostgreSQL also notes that journaling overhead can reduce performance when file-system data has to be flushed to disk, which is another way of saying that fewer shared flushes usually means less friction.
The practical picture is easy to imagine. The log becomes the cashier lane, and table files become the shopping carts waiting in the parking lot. The cashier lane works best when it does not have to wait for carts to move around it, so the database keeps WAL writes short and sequential while checkpoint work moves larger dirty-page batches later. MySQL’s redo-log documentation makes the same trade-off visible: redo is appended as modifications occur, and checkpoint progress changes how much pressure lands on the storage layer.
If you’re asking, “Does isolating logs on storage make commits instant?” the answer is no, but it does make them steadier. PostgreSQL says multiple transactions can share a single log fsync, and MySQL describes commit-order redo behavior that centers on ordered flushing, so the main win is reduced contention rather than magical speed. When the log has its own lane, your commit latency is less likely to spike just because a checkpoint or page flush is busy elsewhere. That is the difference between a smooth road and a road with one bottlenecked bridge.
There is still a balancing act. If the log device is too small, too slow, or poorly protected, you have only moved the bottleneck instead of removing it, and the database still needs durable storage because WAL is what makes crash recovery possible. PostgreSQL’s WAL and checkpoint docs tie durability to flushing the log and recording the checkpoint position, while MySQL’s redo log docs show that capacity directly affects how aggressively dirty pages are flushed. So the goal is not to hide the log from the rest of the system; it is to give it enough room and independence to do its job without dragging the whole write path behind it.



