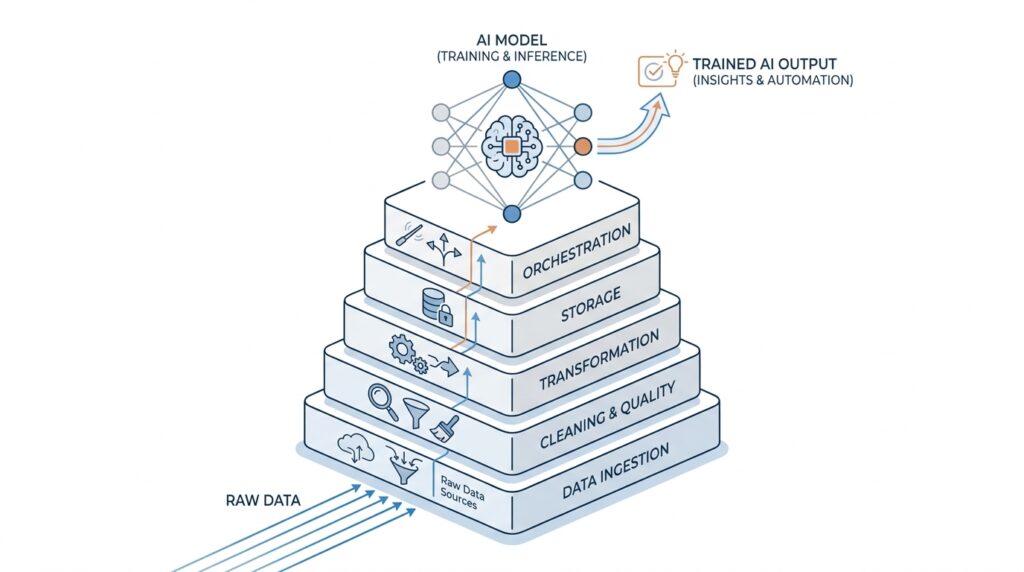
AI Starts with Data Foundations
When people picture AI, they often imagine the model first: the clever chatbot, the recommendation engine, or the system that seems to “think” on its own. In practice, AI starts much earlier, with data foundations that are clean, organized, and trustworthy. If the data is messy, incomplete, or scattered across systems, even the best model is forced to guess, and guessing is a shaky way to build intelligence. That is why data engineering, the work of collecting, cleaning, moving, and preparing data for use, sits at the center of modern AI.
Think of it like preparing a kitchen before a meal. A talented chef can only do so much if the ingredients are spoiled, mislabeled, or missing from the counter. In the same way, machine learning, a method that lets computers learn patterns from data, depends on having the right ingredients in the right place. Before we talk about smarter outputs, we need to make sure the inputs are reliable, because AI data foundations determine whether the system learns something useful or something misleading.
This is where the work gets real. Data often arrives from many places at once: app logs, customer records, sensors, spreadsheets, and databases, which are structured collections of information stored for easy access. Each source may speak a slightly different language, use different formats, or leave gaps in the story. Data pipelines, the paths that move data from source to destination, help us carry that information into a shared space where it can be checked and prepared. Without that careful movement, teams spend more time chasing errors than building AI.
And the challenge is not only getting the data into one place. We also need data quality, which means the data is accurate, complete, consistent, and timely enough to support a decision. A model trained on duplicate records, missing labels, or outdated values may look impressive during a demo and fail the moment it meets the real world. Have you ever wondered why an AI system seemed confident but gave a strange answer? Often, the problem started long before the model was trained, right at the level of the data foundations.
Good data engineering also gives AI memory and context. Features, which are measurable inputs used by a model, need to be created in a repeatable way so the system sees the same meaning during training and later in production, meaning the live environment where users interact with it. That consistency matters because AI does not learn from intention; it learns from patterns. If we change how we measure customer activity, time, or behavior without keeping the process stable, the model can lose its footing even when the code itself is unchanged.
There is also a quieter but equally important piece: trust. When teams can trace where data came from, how it changed, and who touched it, they can debug problems faster and build with more confidence. This is why data engineering is not just support work behind the scenes; it is the structure that lets modern AI grow safely and at scale. The stronger the foundation, the easier it becomes to move from promising experiments to systems people can actually rely on.
So when we say AI starts with data foundations, we are naming the part of the journey that happens before the clever part becomes visible. The model may get the attention, but the data engineering beneath it decides whether that attention is deserved. Once that base is solid, we can move forward with a much better chance of building AI that is useful, steady, and ready for the real world.
Build Trusted Data Pipelines
Now that we have a solid foundation, the next question is almost always the practical one: how do we move data without losing trust along the way? This is where trusted data pipelines come in. A data pipeline is the step-by-step path data travels from its original source to the place where people and models can use it, and the word “trusted” means we can believe that the data still makes sense after that journey. If the foundation is the kitchen counter, the pipeline is the line of helpers carrying ingredients from the market to the stove, and every handoff has to protect the quality of what comes through.
A reliable pipeline starts by treating each source with respect, because not all data arrives in the same shape. One system may send clean records, another may send half-finished updates, and a third may use a different naming convention for the same thing. To keep the flow steady, data engineering teams set rules for how data should arrive, how it should be checked, and what should happen when something looks off. That is the quiet power of trusted data pipelines: they do not assume perfection, they build for real life.
So what does that look like in practice? First, the pipeline collects data from source systems, which are the applications, databases, or tools where data is originally created. Then it validates the data, meaning it checks for basic problems like missing values, broken dates, duplicate rows, or unexpected formats. After that, it transforms the data, which means reshaping it into a form that is easier to query, compare, and analyze. Each step matters because small errors can stack up like dust in a machine; by the time the model sees the data, the mistake can look like truth.
This is why data quality is not a separate concern that we handle later. Data quality means the information is accurate, complete, consistent, and timely enough to support the job we want it to do. In trusted data pipelines, quality checks act like checkpoints on a road trip, making sure we do not keep driving after the map no longer matches the road. A good question to ask here is, how do we know the data is good enough for AI? The answer is that we build checks into the pipeline itself, instead of hoping someone notices a problem after the fact.
Once the data is moving reliably, the next piece is lineage, which is the record of where data came from, how it changed, and where it ended up. Lineage gives teams a way to trace a confusing result back to its source, like following footprints through fresh snow. That traceability becomes priceless when a dashboard looks wrong or an AI model starts behaving strangely. Instead of guessing, teams can inspect the exact path the data took and find the moment trust was lost.
Trusted data pipelines also make collaboration easier across teams. When engineers, analysts, and machine learning practitioners all rely on the same clean flow, they spend less time arguing about which number is correct and more time using it well. That shared confidence is one of the biggest reasons data engineering sits so close to modern AI. It is not only about moving data faster; it is about moving it in a way that other people can depend on.
And that dependability matters even more when AI enters the picture, because models are sensitive to small changes that humans may overlook. A field renamed without warning, a timestamp shifted by a few hours, or a missing label can quietly change what the model learns. Trusted data pipelines reduce that risk by keeping the process stable, visible, and repeatable. With that in place, we are not feeding AI a guessing game; we are feeding it a path it can actually learn from.
Create Reusable Feature Stores
Now that our pipelines are moving clean data reliably, we can solve the next headache: how do we stop rebuilding the same features over and over? A reusable feature store gives us a shared home for prepared features, so one team can create a feature once and many models can use it again later. In practice, this means we spend less time rewriting the same transformation logic and more time improving the AI itself. It also helps reduce training-serving skew, which is the mismatch that appears when a model sees one version of a feature during training and a different version in production.
Think of it like a neighborhood pantry with labels on every container. Instead of every cook grinding the same spices from scratch, we keep the finished ingredients in one place, clearly named and ready to use. A feature store works the same way: it acts as a centralized place to store, discover, share, and reuse machine learning features and their metadata. AWS describes this as a storage and data management layer for ML features, while Feast describes a feature store as a system that helps teams define, manage, validate, and serve features at scale.
The idea becomes powerful when we split the job into two very different spaces. The offline store keeps historical feature values for training and batch inference, which means we can look backward in time and rebuild the data a model should have seen. The online store keeps only the latest feature values and serves them with low latency, which is what we need when an application must make a prediction in milliseconds. When both stores are enabled, AWS says they sync to avoid discrepancies between training and serving data, and Feast uses materialization to load features from the offline store into the online store.
This is where reusable feature stores start saving real effort. Without them, every project can drift into its own version of the same logic: one churn model counts user activity one way, another counts it slightly differently, and a third team fixes the bug in only one pipeline. With a shared feature store, the feature definition lives in one place, so the same feature can support multiple models, teams, and use cases without being rebuilt from scratch each time. AWS explicitly calls out feature reusability across teams and the ability to discover and reuse features as a productivity gain.
There is also a quieter benefit that matters a lot once AI reaches production: point-in-time correctness. That means the training dataset uses only the information that would have been available at the exact moment being modeled, instead of accidentally leaking future data into the past. Feast highlights this as a way to avoid data leakage, and that matters because leakage can make a model look smarter than it really is during testing. When we build reusable feature stores well, we are not only saving time; we are protecting the honesty of the model itself.
If you are wondering how this looks in day-to-day work, the answer is surprisingly practical. A data engineer prepares a feature once, gives it a clear definition, and stores it where both training jobs and live applications can find it. Later, when a model needs that same signal again, it reads from the feature store instead of recomputing everything from raw tables and scattered scripts. That is why feature stores fit so naturally into AI-driven data engineering: they turn repeated feature work into shared infrastructure, and shared infrastructure is what lets AI grow without becoming messy.
Add Quality and Governance
Once the raw data is flowing, the next challenge is keeping it trustworthy as it moves through the system. That is where data quality and data governance enter the story together: one helps the data stay accurate and usable, and the other sets the rules that keep it safe, consistent, and meaningful for AI-driven data engineering. AWS describes data governance as the processes and policies that keep data in the proper condition for business use, while Microsoft says governance should make data discoverable, accurate, trusted, and protected. In an AI workflow, that matters because the model can only learn well from what we allow it to see.
A good place to start is with data quality, because it gives us a practical way to ask, “Is this data fit for the job we want it to do?” In plain language, data quality means the information is accurate, complete, consistent, timely, and reliable enough to support a decision. Microsoft’s data quality guidance breaks this into measurable rules, such as accuracy, completeness, conformity, uniqueness, and freshness, which turns a vague concern into something the team can actually check. That is a powerful shift in AI data engineering, because we stop hoping the data is good and start proving it.
Governance gives those checks a home. Instead of leaving every team to invent its own standards, data governance defines who can use the data, how it should be labeled, what counts as acceptable quality, and what to do when something fails a check. NIST describes data governance as the discipline around data management, including metadata standards and data quality management, which is a helpful way to think about it: governance is the map, and quality is one of the rules printed on that map. Without that structure, AI teams often end up arguing over definitions instead of building models.
We also need a way to trace problems when they appear, because even a strong pipeline can develop a weak spot. Data lineage is the record of where data came from, how it changed, and where it ended up, and Google Cloud describes it as a map of the data’s life cycle with a clear audit trail. Microsoft adds that lineage helps with troubleshooting, root-cause analysis, compliance, and impact analysis, which is exactly what we want when a model starts acting strangely and we need to find the moment trust was lost. In practice, lineage turns a mystery into a trail we can follow.
That traceability becomes even more valuable when data quality slips in small, easy-to-miss ways. A missing value here, a duplicated customer there, or a field that changes meaning after a system update can quietly reshape what an AI model learns. Microsoft Purview’s guidance shows how quality rules and profiling can surface those issues before they spread, and Google Cloud notes that runtime lineage is especially useful for governance because it reflects what actually happened in production. For AI-driven data engineering, that means quality checks are not a final polish; they are part of the working fabric of the system.
Good governance also builds confidence across people, not just systems. When engineers, analysts, and machine learning teams share the same definitions, the same quality checks, and the same lineage records, they spend less time debating numbers and more time improving outcomes. AWS notes that governance matters for AI because modern systems need data quality and integrity to support training and inference, and Microsoft similarly emphasizes that trustworthy data is essential in the era of AI. So when we add quality and governance early, we are not slowing the work down; we are making sure the next model has a solid, dependable place to stand.
Handle Batch and Streaming
After the pipelines are clean and the feature store is in place, the next question becomes a timing question: how do we handle data that arrives in big piles and data that arrives as a nonstop trickle? In AI-driven data engineering, we usually need both. Batch processing means we collect a group of records and process them together, while streaming means we process records continuously as they arrive. That split matters because training, reporting, and backfills often prefer batch, but alerts, personalization, and fraud detection often need streaming data.
Batch is the calm, scheduled side of the story. It works well when you have a large volume of repetitive work and can afford to process it on a timetable, such as overnight or at the end of the day. AWS describes batch processing as the periodic handling of high-volume jobs, and it gives examples like billing, payroll, report generation, and data conversion. In practice, batch processing in data engineering gives us a reliable way to rebuild history, refresh aggregates, and prepare data for model training without chasing every new event one at a time.
Streaming is the fast-moving side of the same road. Instead of waiting for a full pile of data, streaming systems keep analyzing each new record as it shows up, which gives us low latency, meaning the system responds quickly after an event happens. AWS explains that streaming is better suited for real-time analytics and response functions, and Google Cloud notes that it powers near real-time analytics and decision-making. If batch feels like reviewing yesterday’s ledger, streaming feels like watching the counter while customers are still walking in.
The tricky part is that streaming data is not as tidy as it sounds. New records can arrive late, arrive out of order, or need to be grouped into a window, which is a time slice used to make sense of fast-moving events. Microsoft’s Databricks guidance points out that batch reprocesses the available data each time, while streaming only processes the new data since the last run, which makes streaming efficient but also more sensitive to timing issues. That is why streaming systems need careful design; they trade reprocessing for immediacy.
So how do we handle batch and streaming without building two separate worlds? The answer is usually a hybrid model. AWS notes that many organizations combine batch and streaming to keep both a real-time layer and a batch layer, and Google Cloud’s Apache Beam model describes a unified way to define both kinds of pipelines. That matters because a unified approach lets data engineering teams reuse logic, reduce duplication, and choose the right rhythm for each job instead of forcing every workload into the same shape.
This balance becomes especially important once AI enters the picture. Dataflow ML, for example, supports both batch and streaming pipelines for training preparation, prediction, and inference, which shows how the same data backbone can serve both offline learning and live decision-making. In plain terms, batch gives the model its historical memory, while streaming gives it fresh context as the world changes. When those two paths stay aligned, AI-driven data engineering can feed models data that is both stable and current.
That is the real job here: not choosing batch or streaming as if they were rivals, but matching the right processing style to the right business moment. Batch keeps the historical record dependable, streaming keeps the live signal responsive, and together they give AI a fuller picture of reality. Once we learn to move between those two rhythms, data engineering stops being a background chore and becomes the structure that lets modern AI stay useful as conditions change.
Deliver Data to Models
Once the data has been cleaned, governed, and shaped, we arrive at the moment where AI either starts to feel real or falls apart: the last mile to the model. A model does not read raw tables the way a person would; it consumes features, which are prepared inputs that carry the meaning it needs to make a prediction. In other words, data engineering is not finished when the data lands in storage. It is finished when we can deliver data to models in a form they can trust at training time and again at inference time, when the model is making live predictions.
That is why feature stores matter so much in modern AI. A feature store is a storage and data management layer for machine learning features, and AWS describes it as having an online store for low-latency, real-time lookup and an offline store for historical data used in model training and batch inference. Feast makes the same split in simpler terms: models need a consistent way to reach the same feature values whether they are learning or serving. If we picture the model as a chef, the feature store is the labeled pantry that keeps the ingredients organized, reusable, and close at hand.
The tricky part is not storing data; it is making sure the model sees the right version of that data at the right time. This is where training-serving skew comes in, which is the mismatch between the data used during training and the data used during inference. AWS and Feast both warn that separate ways of pulling data for training and serving can create that mismatch, and that inconsistency can hurt model accuracy. Point-in-time correctness helps here by making sure we only use the information that would have been available at the moment we are modeling, instead of accidentally leaking future facts into the past.
So how do we deliver data to models without rebuilding the same logic again and again? We usually materialize features from the offline store into the online store, which means we load prepared feature values into the place where low-latency inference can read them quickly. Feast describes this as materialization, and AWS notes that when both online and offline stores are enabled, they sync to avoid discrepancies between training and serving data. That shared path matters because it lets a team define a feature once, then reuse it across training jobs, batch inference, and real-time predictions without writing three different versions of the same transformation.
This is also where the difference between batch and real-time delivery becomes easy to feel. Batch inference uses historical data in larger groups, while real-time inference needs the latest values with millisecond-level access, and AWS explicitly ties those two modes to the offline and online stores respectively. If you have ever asked, “How do you deliver data to models when some decisions need an answer now and others can wait?” the answer is that data engineering sets up both paths on purpose. The model serving layer then reads from the right source based on the job it is doing, instead of forcing every prediction through the same slow or stale route.
That reliability also helps teams move faster without losing control. When the feature definitions are centralized, models become more portable, because they no longer depend on one-off queries or hidden spreadsheet logic buried in a single project. Feast describes this as a single data access layer that decouples models from the underlying infrastructure, and AWS notes that feature reuse reduces repetitive processing work while keeping training and serving consistent. In practice, that means the model gets a clean, stable signal, and the data team gets fewer surprises when the system moves from a notebook to production.
Once we see this flow clearly, the picture becomes much easier to hold in our minds. Data engineering does not end at storage or cleaning; it ends when the right features reach the model in a form that is current, consistent, and ready to use. That is the hidden craft behind reliable AI, and it is what turns a promising model into something that can keep performing when the world outside the notebook starts changing.



