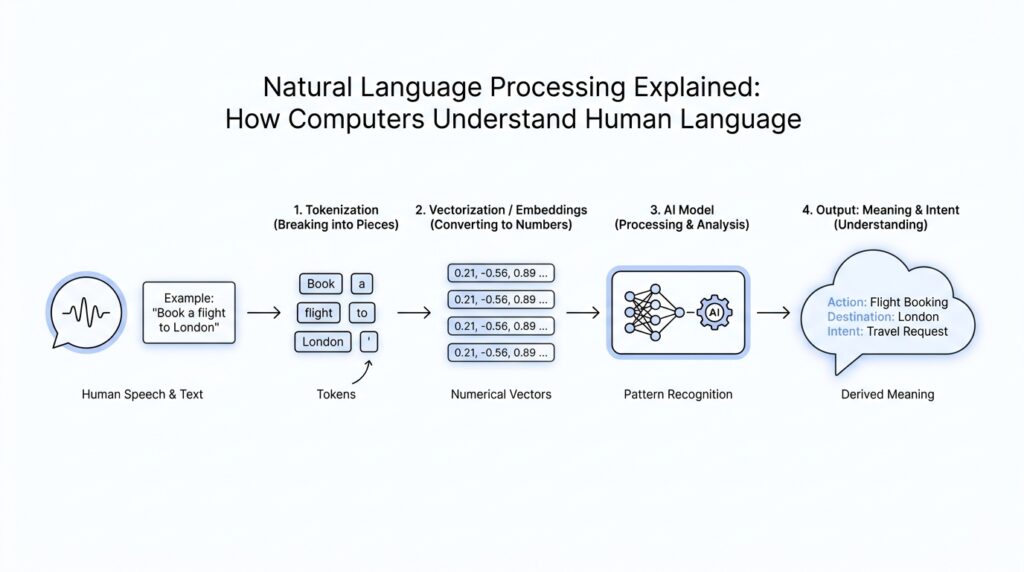
What NLP Actually Does
Imagine you type a messy, emotional sentence into a chatbot and get a calm, useful reply a second later. That little moment is where natural language processing, or NLP, is doing its quiet work. It does not read like a person does; instead, it turns human language into pieces a computer can handle, then looks for patterns, structure, and meaning. In practice, NLP lets software recognize, understand, and generate text and speech by combining language rules with machine learning and deep learning.
The first thing NLP usually does is break language into tokens, which are small units such as words or parts of words. Think of it like opening a drawer full of mixed screws, clips, and buttons and sorting everything into trays before you build anything. Without that step, the system has no clean way to measure or compare the pieces of your sentence. Computers do not work with raw paragraphs the way we do; they work with these smaller language units first.
Once the text is split apart, NLP starts labeling what each piece is doing. Part-of-speech tagging assigns roles like noun, verb, or adjective, while named entity recognition finds real-world things such as people, places, dates, and organizations. Dependency parsing goes a step further and shows how words relate to one another, like drawing lines between the important parts of a sentence. That is how a system can tell that “make” is a verb in one sentence and a noun in another.
After that, NLP tries to pull meaning out of the structure it has found. This is where tasks like sentiment analysis, key phrase detection, language detection, and topic discovery come into play. A review can be marked positive, negative, neutral, or mixed; a document can be scanned for the important phrases it keeps repeating; and a system can spot the dominant language or the entities people are talking about. If you have ever wondered, “How does NLP know whether a customer is happy or upset?”, this is the stage where that answer begins to appear.
This is also where NLP becomes useful in everyday products. Search engines use it to make your query more meaningful, chatbots use it to route your message to the right intent, and voice assistants use it to turn spoken language into actions. In other words, NLP helps software move from “I see text” to “I know what this text is probably about.” That shift from raw input to structured insight is what powers everything from customer support tools to document analysis systems.
So what does NLP actually do, in the simplest sense? It takes language that feels loose, noisy, and human, then turns it into something organized enough for a machine to work with. First it chops the sentence into pieces, then it names the pieces, then it interprets what those pieces mean together. Once we see that chain clearly, NLP stops feeling mysterious and starts looking like a careful translation process between human expression and computer logic.
Text Preprocessing Steps
Before a computer can make sense of language, we usually have to tidy the text first. That is the heart of text preprocessing: a set of preparation steps that turn messy, inconsistent writing into input a model can work with more reliably. If you have ever wondered, “Why does text preprocessing matter so much in NLP?”, the answer is that raw language is full of noise, and noise can blur the patterns a machine is trying to see. The goal is not to erase meaning. The goal is to remove distractions so the important parts stand out.
We often begin with cleaning, which means removing or fixing characters that do not help the task at hand. That might include extra spaces, broken formatting, stray symbols, or repeated punctuation from excited messages. Imagine sorting a toolbox before repairing a bike: you are not changing the bike, only clearing away clutter so the real work is easier. In NLP preprocessing, this first pass makes later steps more stable because the same idea stops appearing in several slightly different forms.
The next step is normalization, which means making different versions of the same text look more alike. A common example is lowercasing, where words like “Apple” and “apple” are treated the same unless case matters for the task. We may also standardize numbers, dates, or abbreviations so the model does not waste effort on meaningless variation. This is one of those text preprocessing steps that feels small but pays off quickly, because computers are very literal and do not automatically know that “NYC” and “New York City” might point to the same place.
From there, we usually face stop words, which are very common words like “the,” “is,” and “and.” These words are not useless in every situation, but they often carry less meaning than the content words around them. Removing stop words can help a model focus on the terms that do more of the heavy lifting, especially in search or topic classification. At the same time, we have to be careful, because in sentiment analysis a tiny word like “not” can completely change the meaning of a sentence. This is why good NLP preprocessing is never one-size-fits-all.
Another important choice is whether to stem or lemmatize words. Stemming is the rough-and-ready version; it trims words down to a base form, often by cutting off endings. Lemmatization is more precise; it turns a word into its dictionary form, or lemma, by using grammar and context. So “running,” “runs,” and “ran” may be reduced to one shared form, depending on the method. Stemming is faster, while lemmatization tends to be cleaner, and the right choice depends on whether speed or accuracy matters more for the task.
Then we handle punctuation, special characters, and sometimes emojis, because these can either help or distract. A question mark may matter in a support ticket, and an emoji can carry strong emotion in social media text, so we do not remove everything blindly. This is where preprocessing starts to feel more like judgment than housekeeping. We look at the problem in front of us and decide what should stay, what should go, and what should be converted into a more useful form. That is the quiet craft behind strong text preprocessing.
Once these pieces are in place, the text becomes easier to compare, count, and learn from. The model no longer has to treat every spelling variation, extra space, or awkward ending as a fresh puzzle. Instead, it can see cleaner patterns and spend its energy on meaning. In other words, NLP preprocessing acts like a translator’s notebook: it does not replace the message, but it helps the machine read it with far less confusion. With that foundation set, we can move into the next stage knowing the text is ready for deeper analysis.
Tokenization and Normalization
Now that the text is cleaner, we reach the next quiet decision point in NLP preprocessing: how do we break language into pieces, and how do we make those pieces easier to compare? This is where tokenization and normalization start doing their real work. If you have ever asked, “What is tokenization in NLP, and why does normalization matter?”, the short answer is that they help a computer turn messy language into a consistent set of units it can actually analyze. Tokenization creates the pieces, and normalization makes those pieces less slippery.
Tokenization is the process of splitting text into tokens, which are small language units a model can work with. Those tokens might be full words, parts of words, or even individual characters, depending on the job in front of us. Think of it like cutting a loaf of bread: some recipes want thick slices, some want cubes, and some need breadcrumbs. In the same way, tokenization in NLP is not one fixed method, because a search engine, a chatbot, and a spelling tool may all need different kinds of pieces.
That choice matters more than it first appears. A word-level tokenizer might turn the sentence “I’m re-reading the book” into clear, familiar chunks, while a subword tokenizer, which breaks words into smaller meaningful parts, may split “re-reading” into pieces that help the model handle new or uncommon words. Character-level tokenization goes even smaller and can be useful when the exact spelling matters, such as in usernames, codes, or noisy text. Each version changes what the system notices first, so tokenization becomes one of those early NLP preprocessing steps that quietly shapes everything that follows.
Normalization comes next, and it acts like a translator who removes distracting differences without changing the message’s core meaning. In plain terms, normalization means making text more consistent so the model does not treat harmless variation as something brand new. A common example is lowercasing, where “Apple” and “apple” can be treated the same if case is not important to the task. We might also normalize accents, standardize Unicode characters, or expand contractions like “don’t” into “do not” when that helps the model read more clearly.
But normalization is not a rule book we apply blindly. It is more like choosing the right lens for the story we want the machine to see. In sentiment analysis, “not happy” and “happy” must stay distinct, so we have to protect words that carry negation. In named entity recognition, a task that finds names of people, places, and organizations, case can matter a lot because “Apple” may point to a company while “apple” may point to fruit. Good normalization respects those differences instead of flattening them away.
This is why tokenization and normalization work best as a pair. Tokenization decides where the boundaries are, and normalization decides which variations should count as the same thing. If we tokenize before we normalize, we might split text in a way that preserves useful structure; if we normalize first, we might make later comparison easier. The order can change based on the task, which is why NLP preprocessing feels a little like preparing ingredients for a recipe: the steps are familiar, but the sequence affects the final result.
Once these two steps finish their job, the text becomes far easier for a model to count, compare, and learn from. Instead of seeing a jumble of near-duplicates, the system can recognize repeated patterns and focus on meaning. That is the real power of tokenization and normalization in NLP preprocessing: they turn language from a noisy stream into a well-organized set of signals. And once we have that structure in place, we are ready to let the model start learning from it.
Syntax and Meaning Analysis
By the time we reach syntax and meaning analysis in natural language processing, the text has already been cleaned and split into usable pieces. Now the question changes from “What words are here?” to “How do these words work together, and what do they mean as a whole?” This is where NLP starts feeling less like sorting labels and more like reading a sentence with purpose. If you have ever wondered, “How does a computer know what a sentence actually means?”, this is the stage where that answer begins to take shape.
Syntax analysis is the part that studies sentence structure, which means the grammar-like relationships between words. In plain language, it helps the system see who did what to whom, and which words depend on others for their role. Part-of-speech tagging, for example, marks words as nouns, verbs, adjectives, or other parts of speech, so the model can tell whether “record” is something you keep or something you play. In natural language processing, this structural map matters because meaning often hides inside the arrangement, not just the individual words.
Dependency parsing takes that structural map one step farther. It draws the links between words, showing which word is the main action and which words modify it, like a set of arrows connecting the moving parts of a sentence. Imagine a family tree, but for grammar: some words stand at the center, while others branch off to describe time, place, or object. That kind of syntax analysis helps a system understand that “the dog chased the cat” is not the same as “the cat chased the dog,” even though the words are almost identical.
Once the structure is clear, meaning analysis asks what the sentence is trying to express in the real world. This is a broader job called semantic analysis, which means studying meaning rather than grammar alone. Here, the model tries to connect words to ideas, intentions, and outcomes. A sentence may be grammatically perfect and still hide sarcasm, uncertainty, or a request, so syntax gives us the frame while semantics fills in the picture. In natural language processing, that shift from structure to meaning is what turns text from a pattern into something usable.
One important piece of this puzzle is named entity recognition, often shortened to NER, which means finding specific real-world things like people, places, dates, and organizations. This is useful because names carry special weight in meaning analysis. If a sentence says “Jordan met Apple in Paris,” the model needs to decide whether “Jordan” is a person or a place, and whether “Apple” is a company or a fruit. That sounds tiny, but these distinctions shape everything from search results to chatbots to document extraction.
Another challenge is word sense disambiguation, which means choosing the correct meaning of a word that has more than one possible sense. The word “bank,” for instance, can mean the side of a river or a financial institution, and syntax alone may not settle the question. The surrounding words provide clues, and meaning analysis weighs those clues against context. This is one of the places where natural language processing feels especially human, because we do this all the time without noticing how much background knowledge it requires.
Put together, syntax and meaning analysis let NLP move from reading words one by one to interpreting a sentence as a connected idea. Syntax tells us how the pieces fit, and semantics tells us what those pieces are trying to say. That pairing is what makes a sentence understandable to a machine in the first place, whether the system is classifying a message, answering a question, or extracting facts from a report. And once we understand that bridge between structure and meaning, the next step is seeing how models use it to learn from whole documents instead of single sentences.
Building NLP Models
Once the text is clean and tokenized, building NLP models becomes the moment where all those pieces have to learn how to speak numbers. If you’ve ever wondered, “What does it actually look like to build NLP models after the text is clean?”, the answer is that we first turn documents into numeric features and then teach a classifier or sequence model what those features mean. Classic pipelines often use CountVectorizer or TfidfVectorizer to convert raw documents into token-count or TF-IDF matrices, while TensorFlow’s TextVectorization layer can feed an Embedding layer that learns vectors for each word.
The older feature-based route is a lot like giving each document a card catalog entry. It turns language into structured input that a machine can compare, count, and score, which is why it remains a strong baseline for text classification and other natural language processing tasks. Once we move into neural NLP models, the story gets more fluid: an embedding layer stores one vector per word and converts token indices into dense numerical representations, and TensorFlow notes that words with similar meanings often end up with similar vectors after training. That shift from sparse features to learned embeddings is one of the biggest leaps in natural language processing.
From there, we choose a shape for the model. In TensorFlow examples, one common pattern is encoder → embedding → sequence layer such as a recurrent neural network, followed by dense layers that produce the final prediction. The output layer has to match the job: binary classification uses one output, while multi-class classification needs one output per label and a matching loss such as SparseCategoricalCrossentropy(from_logits=True). In other words, the last layer is the model’s answer sheet, so it has to be written in the same language as the labels.
Training is where the model starts making mistakes and learning from them. We usually split data into training, validation, and test sets, making sure the validation split does not overlap with the training data, and then we watch validation loss and accuracy while model.fit() runs through epochs. If the training score keeps improving while the validation score stalls or gets worse, the model is overfitting, which means it is memorizing the training examples instead of generalizing to new text. That is why tools like EarlyStopping matter: they let us stop at the point where learning is still useful.
Sometimes we do not start from zero at all. Fine-tuning means taking a large pretrained model and continuing training on a smaller task-specific dataset, which Hugging Face says takes far less compute, data, and time than pretraining from random weights. Transformer models such as BERT work especially well here because they build vector-space representations of language and are commonly pretrained on large corpora before being adapted to a task like sentiment analysis or text classification. For many NLP models, this is the practical shortcut that turns a powerful general model into a specialist.
The last piece is making sure the model behaves the same way in the real world that it did in training. TensorFlow recommends including TextVectorization inside the model when you want to serve raw strings, because that reduces training-serving skew and keeps preprocessing identical at train and test time. Once that pipeline is in place, the same model can take a fresh sentence, convert it into features, and return a prediction with far less friction. That is the quiet payoff of building NLP models well: the machine stops seeing random text and starts seeing a repeatable path from words to decisions.
Real-World NLP Applications
Now that we have seen how NLP turns language into something a machine can work with, the most interesting question is where that power shows up in everyday life. Natural language processing is already sitting behind many tools you use without thinking about it: a support bot that answers late at night, a search bar that understands a vague question, or an email app that tries to finish your sentence. What is natural language processing used for in everyday products? In practice, it helps software read, sort, respond to, and prioritize human language so people can move faster and feel less stuck.
One of the clearest places we meet NLP is customer support. When you type, “My order hasn’t arrived and I need help,” the system does more than scan for keywords. It uses text classification, which means sorting a message into a category, and intent detection, which means figuring out what you want the system to do. That is how a company can send your message to refunds, shipping, or a human agent instead of making you repeat yourself three times. In a busy support queue, that small bit of natural language processing can make the difference between a smooth conversation and a frustrating one.
Search is another place where NLP quietly does heavy lifting. A search engine has to guess what you mean, not only what you typed, and that is where query understanding comes in. If you search for “best laptop for video editing,” the system may look past the exact wording and focus on the intent behind it, then rank results that match the task rather than the phrase. This is why modern NLP feels a little like a helpful librarian: it does not just find words on a page, it tries to find the right answer to the question behind the words.
We also see NLP working in writing tools and office software. Grammar checkers, autocomplete, spam filters, and smart reply suggestions all rely on language models trained to notice patterns in text. When your email app suggests a short reply like “Sounds good” or “I’ll send it today,” it is using language prediction, which means estimating the most likely next words from context. That may sound small, but it saves time all day long, especially when you are writing the same kinds of messages again and again.
Healthcare, finance, and legal work use NLP in a more serious way. A clinic might use it to pull symptoms or medication names from a patient note, while a bank may scan messages for signs of fraud or urgent account problems. In these settings, the goal is often information extraction, which means finding specific facts inside large amounts of text. Because those fields deal with sensitive decisions, teams still keep humans in the loop, but natural language processing helps them find the important pieces much faster than reading every line by hand.
NLP also makes digital spaces more accessible. Speech-to-text tools turn spoken words into written text for people who cannot type easily, and text-to-speech tools read content aloud for people who prefer listening or need screen support. Translation tools use NLP too, helping people cross language barriers in real time. These applications matter because they do more than save time; they widen access, allowing more people to use the same information and tools in a way that works for them.
So when we talk about real-world NLP applications, we are really talking about a bridge between human language and useful action. The technology can route support requests, improve search, help people write, extract facts, and make software more accessible. That is the heart of NLP in practice: not a flashy trick, but a steady ability to turn messy language into something that helps people get things done.



