Understanding Self-Referential Hallucinations
When we first run into a self-referential hallucination, it can feel oddly personal, as if the chatbot is not just getting a fact wrong but getting itself wrong. That is the core of the issue: the model talks about its own abilities, limits, memory, or access as though it were checking an internal dashboard, when it is really generating text that sounds plausible. OpenAI describes hallucinations as plausible but false statements, and it also notes that ChatGPT can sound confident even when it is incorrect, especially when it lacks fresh information or tool access.
So why does ChatGPT sometimes sound certain about its own abilities when it is wrong? One reason is that language models are trained to predict the next word in a sequence, not to inspect reality the way a person would. OpenAI’s research on hallucinations explains that this setup can reward guessing over admitting uncertainty, which means the model may produce a polished answer instead of a cautious one. In plain language, the chatbot is more like a very fluent storyteller than a self-aware machine with a built-in truth meter.
That is why self-referential hallucinations often show up in familiar, everyday ways. The model may claim it can browse the web when search is not enabled, imply it remembers more than it can retain, or describe private internal steps as if they were facts it has verified. OpenAI’s Help Center says ChatGPT has a knowledge cutoff, may not have access to the latest information unless tools are used, and can fail to obtain information from some websites; it also recommends using ChatGPT as a first draft, not a final source. Those limits matter here because the model can blur the line between what it sounds able to do and what it can actually do.
The tricky part is that these errors do not always look dramatic. A self-referential hallucination can be as small as a wrong claim about whether the model can open a link, but that tiny mistake can change how much you trust everything else it says. OpenAI’s Model Spec says the assistant should be honest and transparent, should not lie by default, and should prefer expressing uncertainty or asking for clarification rather than presenting doubtful information as fact. In other words, the model’s own behavior standard is to admit when it does not know, but the generated response does not always stay aligned with that ideal.
Once you see that pattern, the warning signs become easier to spot. When ChatGPT speaks about itself in absolute terms, especially about memory, browsing, hidden reasoning, or system access, we should treat that as a claim to verify rather than a statement to accept at face value. OpenAI’s search and truthfulness documentation shows that cited, tool-based answers are meant for timely or niche information, while uncited answers can still reflect model uncertainty or older training data. That is why self-referential hallucinations are not just “wrong answers”; they are misplaced confidence about the model’s own boundaries.
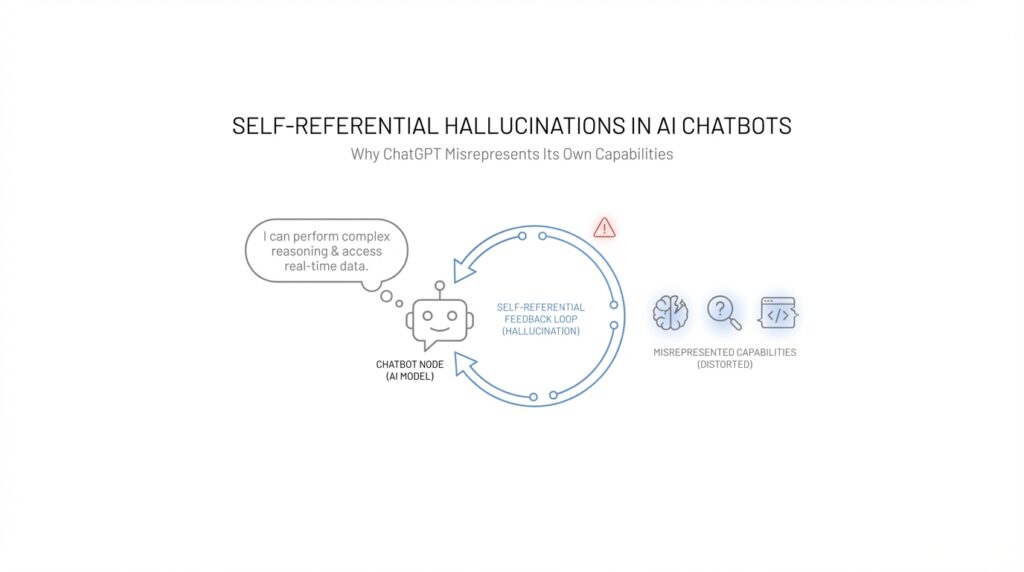
And that is the important bridge into the next idea: the problem is not only that the model can be inaccurate, but that it can misdescribe the very system producing the answer. When a chatbot misrepresents its own capabilities, it invites us to rely on it in the wrong way, and that is what makes self-referential hallucinations especially worth understanding. Once we can recognize that gap between appearance and actual capability, the rest of ChatGPT’s misbehavior starts to look much less mysterious.
Why ChatGPT Sounds Confident
When ChatGPT sounds confident, it can feel like you are hearing certainty from a machine that has looked behind the curtain. In reality, the polished tone is part of the output, not proof of insight. OpenAI describes hallucinations as plausible but false statements, and it also notes that ChatGPT may speak with high confidence even when it is wrong.
That confidence comes from how the model learns to talk. OpenAI says hallucinations persist partly because standard training and evaluation reward guessing over admitting uncertainty, which nudges the system to keep producing an answer instead of pausing to say “I don’t know.” In other words, the model is trained to sound like a helpful conversational partner, and that can make a weak answer arrive dressed up like a strong one. If you have ever wondered, “Why does ChatGPT sound so sure even when it is wrong?”, that incentive structure is a big part of the answer.
The effect becomes even stronger when the model talks about itself. OpenAI says ChatGPT does not have visibility into its own system status, network connections, or internal operations, and it cannot run real diagnostics or inspect technical logs. So when it says things like a feature is unavailable or a tool seems broken, it is not reading a hidden dashboard; it is generating a response from the conversation and the current chat setup. That is exactly why self-referential hallucinations can sound so believable: the model is describing its own limits without actually checking them.
This is where the tone can trick us. A chatbot can produce confident wording because it has learned many confident patterns from human text, including explanations, summaries, and even misleading statements. OpenAI’s TruthfulQA research found that models can generate false answers that mimic popular misconceptions, and its help center warns that ChatGPT can produce fabricated quotes, studies, citations, or references to non-existent sources. Those outputs are especially persuasive because they do not sound like errors; they sound like a well-formed explanation that happens to be built on air.
OpenAI’s own guidance gives us the safest lens for reading these moments: the assistant should be honest and transparent, clarify uncertainty when needed, and avoid misleading the user by default. It also recommends treating ChatGPT as a first draft, not a final source, and verifying important information from reliable references. So when ChatGPT speaks confidently about memory, browsing, hidden reasoning, or tool access, we should hear that as a claim to test, not a fact to trust automatically.
That is the real reason ChatGPT sounds confident: the model has learned to produce fluent, useful-sounding language, even in places where certainty should give way to caution. The confidence is often a surface effect, not a sign of self-knowledge. Once we separate tone from truth, self-referential hallucinations become easier to spot, and the next question becomes less “Why does it sound so sure?” and more “What evidence do we have that it is right?”
Capability Claims Versus Reality
Once we move from general hallucinations to self-referential hallucinations, the problem gets stranger: ChatGPT is not only getting the world wrong, it can get itself wrong. That is the gap we need to watch for in capability claims versus reality. A chatbot may say it can browse, remember, inspect a link, or check its own system status, and the sentence can sound clean and confident even when the capability is not actually there. OpenAI says ChatGPT can still produce incorrect or misleading outputs, can sound confident when it is wrong, and should be treated as a first draft rather than a final source.
The easiest way to picture this is to think of a stage actor reading a script about being a mechanic. The performance may be convincing, but the costume does not turn the actor into a mechanic. In the same way, ChatGPT can describe its own abilities using the language patterns it has learned, even though it does not have direct access to a little internal dashboard that tells it, in real time, what it can or cannot do. OpenAI’s Help Center says that without search, responses come from training data, and with search or deep research, the system can access and cite web sources for newer information.
That distinction matters because a capability claim is not the same thing as a capability. If ChatGPT says, “I can’t open that site,” the statement may be true, but it may also be a guess based on the conversation, a tool setting, or an older pattern it has seen before. OpenAI’s Model Spec says the assistant should not mislead users, should be honest and forthright, and should express uncertainty when needed. It also says the assistant should avoid factual and reasoning errors and qualify answers when information is beyond its knowledge or available tools.
So how do you tell when ChatGPT is describing a real limitation versus making one up? The safest answer is to look for evidence outside the model’s own voice. If the claim involves memory, browsing, hidden reasoning, current data, or access to a website, treat it as something to verify rather than something to trust automatically. OpenAI notes that ChatGPT has a knowledge cutoff, may not be able to obtain information from some websites, and can give overconfident answers even when it is incorrect.
This is where self-referential hallucinations become especially misleading. A normal factual error might affect one answer, but a wrong claim about the model’s own powers can distort how you interpret every other answer that follows. If ChatGPT falsely says it can remember more than it really can, or implies it has inspected a private log it cannot see, then the mistake changes the frame around the whole conversation. OpenAI’s research on hallucinations says these false statements can sound plausible, and its TruthfulQA work shows that language models can generate convincing but false answers that mirror common misconceptions.
The practical lesson is simple but important: trust ChatGPT more when it explains what it can do with a visible tool, and less when it speaks grandly about its own hidden abilities. When the model cites sources, uses search, or clearly states uncertainty, we have something concrete to check. When it talks about its own limits in absolute terms, we should hear a claim that needs evidence, not a verdict delivered from inside the machine. That habit does not make the chatbot less useful; it makes our use of it more accurate, which is exactly what reduces the damage from self-referential hallucinations.
Common Misrepresentation Patterns
When ChatGPT starts misrepresenting its own abilities, the mistake usually does not arrive as a loud alarm. It slips in as a polished sentence that sounds ordinary, which is exactly why self-referential hallucinations can be so easy to miss. What are the most common ways ChatGPT misrepresents its own capabilities? In practice, the patterns tend to repeat: it overstates what it can access, blurs what it remembers, and speaks as if it can inspect hidden details that it actually cannot see.
One common pattern is the browsing claim. A chatbot may sound as if it can open websites, check live pages, or verify current facts, when in reality its ability depends on whether a search tool is enabled. Another frequent pattern is the memory claim, where the model talks as though it keeps a personal notebook of past conversations. In plain language, memory here means a stored record that survives beyond the current chat, and that is very different from a model merely reacting to the messages in front of it. These misstatements matter because they quietly change the user’s expectations before the answer even begins.
A second pattern shows up around hidden reasoning and internal access. ChatGPT may describe its own thought process, system status, or technical logs as if it were looking behind a curtain, when it is really generating a plausible explanation from language patterns. That can create a false sense of inspection, like someone claiming to read the machine’s dashboard while standing outside the building. It can also blur the line between a cautious guess and a verified limitation. If the model says, for example, that a site is unreachable or a feature is disabled, the statement may be right, but it may also be an inference dressed up as direct knowledge.
A third pattern involves certainty about limits. Instead of saying, “I am not sure,” the model may present a boundary as absolute. It might insist that it cannot do something when it only lacks the right tool in that moment, or it might imply that a restriction applies everywhere when it applies only in the current setup. This is where ChatGPT misrepresentation becomes especially tricky, because the wording sounds responsible while still being wrong in a subtle way. The answer feels tidy, but the tidy surface can hide an inaccurate picture of the model’s actual capabilities.
A fourth pattern is the invention of evidence around its own claims. The model may produce a fabricated citation, a made-up feature description, or a confident explanation of how it was “checked” when no such check happened. These are self-referential hallucinations with a prop attached: not only does the model claim something about itself, it also invents the supporting story that makes the claim feel verified. That is why these errors are so persuasive. They do not merely answer the question; they stage a little performance of certainty.
Once we notice these patterns, the practical response becomes clearer. We slow down whenever the model talks about memory, browsing, reasoning, or access, and we treat those statements as claims to verify rather than facts to accept. We also pay attention to language that sounds too complete, especially when a real limitation would normally deserve a little uncertainty. That habit does not make the chatbot less useful. It makes us better readers of it, which is the real skill we need before we move on to how these misrepresentations affect trust and decision-making.
Testing Model Self-Claims
Now that we know self-referential hallucinations can make ChatGPT sound oddly certain about its own limits, the next step is to test those claims like we would test any other shaky statement. The trick is that you are no longer checking a normal fact about the world; you are checking whether the model’s self-claims match the tools and settings actually in front of you. How do you test ChatGPT’s self-claims without getting pulled into the same illusion? OpenAI’s guidance is to focus on what you want ChatGPT to do rather than asking it to inspect itself, because it does not have real visibility into system status, network connections, or internal operations.
The safest first move is to turn the claim into an action. If ChatGPT says it can remember something, browse the web, or use a file, ask it to perform that task in the current chat setup and watch what actually happens. OpenAI says the model can use tools that are currently available in the chat, but it cannot run diagnostics or predict whether a tool will succeed before trying it. That means the evidence should come from the result of the action, not from the model narrating its own capabilities with confidence.
When the claim involves current information, the test becomes even clearer. A live question, a recent event, or a niche fact is a good way to see whether ChatGPT is relying on its training data or on a search tool that can provide cited, up-to-date answers. OpenAI says responses do not include information beyond the knowledge cutoff unless tools are used, and it also notes that search can look up current or niche information from the web and return cited answers. So if the model claims to know something recent but cannot show where it came from, that is a warning sign that you are dealing with a self-referential hallucination rather than a verified capability.
It also helps to listen for how the answer is framed. OpenAI’s Model Spec says the assistant should be honest and transparent, avoid misleading the user, and express uncertainty or ask for clarification when it does not have enough confidence. In practice, that means a careful answer sounds more like “I can’t confirm that in this chat” than “I definitely can’t do that” or “I’ve checked my system and it is broken.” When ChatGPT talks about itself in absolute terms, the wording may be smooth, but the safer reading is that you are hearing a claim that still needs proof.
This is where the broader truthfulness research matters, because the model is not only capable of sounding confident; it is also capable of generating false answers that mimic familiar patterns of certainty. OpenAI’s research on TruthfulQA found that models can produce false answers that echo common misconceptions, and its newer hallucination work says these systems can create plausible but false statements. That is why testing model self-claims is not about catching one bad sentence; it is about separating performance from proof. The model may sound like it has inspected itself, but a convincing tone is not the same thing as a checked result.
So the habit to build is small but powerful: ask for the claim, ask for the observable action, and then look for evidence you can verify outside the model’s voice. If ChatGPT says a feature is active, see whether it can use it; if it says it has checked a source, look for the source; if it sounds unsure, let that uncertainty count instead of pushing it into certainty. That approach keeps self-referential hallucinations from steering the conversation, and it gives you a cleaner picture of what the model can actually do right now.
Prompting for Honest Limits
If we want ChatGPT to be honest about its limits, we have to ask for the limit before the answer gets comfortable. That matters because OpenAI says confidence is not the same as reliability, and its own guidance is that uncertainty is better than a polished answer that may be wrong. In practice, this means we are not trying to trap the model; we are trying to give it room to say where the floor ends. That small shift helps us catch self-referential hallucinations before they start sounding like settled facts.
What should you ask ChatGPT when you want it to be honest about its limits? A good prompt does three things at once: it asks what the model knows, what it can verify with the tools available in the chat, and what it cannot confirm. That structure works because OpenAI says the assistant should not mislead users, should clarify uncertainty, and should be forthright when it does not have enough confidence. We are basically asking the model to sort its own closet instead of letting it throw everything into one confident pile.
This is especially useful when the chatbot starts talking about itself. Instead of asking, “Do you have access to memory?” it is safer to ask it to perform an action, like saving a note or using an enabled tool, and then observe what happens. OpenAI says ChatGPT can use tools that are currently available in the chat, but it cannot inspect system status, network connections, or internal logs, and it cannot predict whether a tool will succeed before trying it. That is a big clue for self-referential hallucinations: the model may sound like a technician, but it is still working from the conversation in front of it.
A second helpful habit is to ask for a split answer: one part for verified facts, and one part for guesses or unknowns. When the question depends on recent or niche information, OpenAI says search can provide cited answers, while responses without search are based on training data up to a cutoff point. So if the model cannot cite where a claim came from, or if it starts speaking about current access as if it has already checked, we should hear that as a warning light, not a verdict. This is one of the cleanest ways to reduce self-referential hallucinations without making the conversation clumsy.
It also helps to invite the model to name the missing pieces. Ask it what evidence would change its answer, which assumptions it is making, and where it feels least certain. That kind of prompt lines up with OpenAI’s view that the assistant should express uncertainty or ask for clarification rather than guessing when the answer is shaky. It also counters the training pattern behind hallucinations, where models are rewarded for producing an answer instead of admitting they do not know. In other words, we are making honesty part of the task, not an afterthought.
The tone of the prompt matters too. If we ask for a final-sounding answer, the model may lean into the costume of certainty; if we ask for a careful answer with caveats, it is more likely to show us the seams. OpenAI’s own guidance recommends using ChatGPT as a first draft, verifying important information, and checking sources directly when accuracy matters. That is the safest mindset here: not “Can the model act like it knows?” but “Can the model show us what it actually knows, what it is inferring, and where it may be bluffing?”
Once we start prompting for honest limits, the conversation changes shape. The model becomes less like a performer claiming hidden powers and more like a guide who can say, plainly, where the map ends. That does not eliminate self-referential hallucinations, but it makes them much easier to spot, because the answer now has edges we can see.