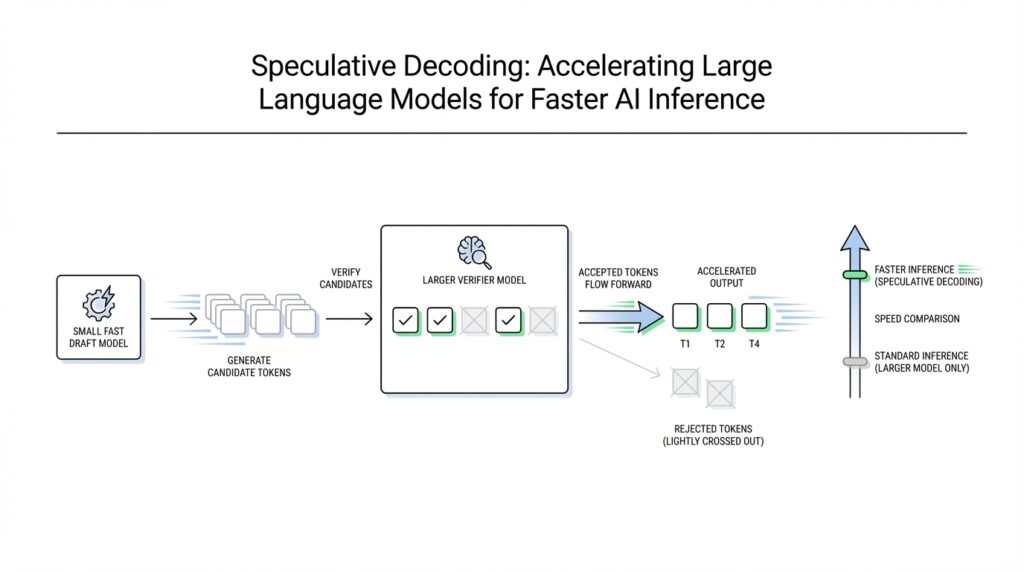
What Speculative Decoding Is
Imagine you are waiting for a large language model to finish a reply, and it feels a little like watching a careful person type one key at a time. Speculative decoding changes that rhythm. Instead of asking the big model to produce every token one by one, we let a smaller, faster draft model sketch several next tokens first, then we ask the larger target model to verify that sketch in one pass. In practice, speculative decoding is a draft-then-check strategy for language generation, and it was introduced to speed up transformer decoding without changing the model’s output behavior.
So how does speculative decoding work in plain language? Think of it like a friend reading ahead in a script while the lead actor confirms the lines. The draft model makes a short guess about what should come next, not because it is wiser, but because it is cheaper to run. Then the target model compares those guesses against its own probabilities and accepts the ones that fit, correcting the rest when needed. That is the heart of speculative decoding: one model explores quickly, and another model acts as the final editor.
The reason this helps is easy to miss at first. Autoregressive decoding, which means generating text one token at a time where each new token depends on the previous ones, can become painfully sequential. Speculative decoding tries to break that bottleneck by letting the smaller model propose a whole stretch of text at once, so the large model can verify multiple candidates together rather than starting from scratch for every token. The original speculative sampling work showed that this approach can generate multiple tokens from each transformer call while preserving the target model’s distribution through a modified rejection-sampling step.
That detail about preserving the target distribution matters a lot. Without it, speeding up generation could quietly change the style, accuracy, or randomness of the model’s answers. With speculative decoding, the goal is not to replace the large model’s judgment; it is to borrow speed from the smaller model while keeping the large model in charge of the final output. In other words, the draft model is allowed to be bold, but the target model has the final say.
You can picture the process as a small team working on a sentence together. The draft model is the quick note-taker, the target model is the careful reviewer, and speculative decoding is the workflow that lets both do what they do best. When the draft is accurate, the target model accepts several tokens at once, which means fewer slow generation steps and better throughput, or output per unit of time. When the draft is less accurate, the target model rejects the mismatched part and continues from the last accepted token, so the system stays on track even when the guess was imperfect.
This is why speculative decoding is such a practical idea for faster AI inference, which means the stage where a trained model is used to produce answers. You do not need to rebuild the large model from the ground up, and you do not need to sacrifice output quality in exchange for speed. Instead, you add a second model that acts like an accelerator, turning the long wait between tokens into a shorter, more efficient conversation. Once that picture clicks, we can move on to the next question: what decides how many draft tokens get proposed before the target model steps in?
Choosing a Draft Model
Building on this foundation, the real question becomes which draft model earns its place beside the larger target model. It is tempting to reach for the strongest small model you can find, but speculative decoding rewards a different kind of strength: low latency, decent alignment, and the ability to get out of the way quickly. Research on speculative decoding shows that performance depends heavily on the draft model’s latency, and that raw language-modeling skill does not line up as closely with throughput as you might expect. So when you ask, “How do I choose the right draft model?”, the answer starts with speed and fit, not prestige.
A good starting point is a draft model that comes from the same family, the same task, or at least the same style of data as the target model. Hugging Face’s Whisper example follows this logic by pairing a main model with a smaller assistant model, then recommending fine-tuning and distillation on the same dataset to improve alignment between the two. That is a useful mental model for text generation too: the more the draft model learns the target model’s habits, the more often speculative decoding can accept whole stretches of tokens instead of discarding them halfway through. Think of it like a rehearsal partner who knows the script well enough to keep pace, even if they are not the star of the show.
Here is where many people get tripped up: a larger draft model is not automatically a better draft model. If it spends too much time thinking, the system loses the very speedup speculative decoding is supposed to create. The paper on decoding speculative decoding found that draft-model latency matters more than general model capability, and it even motivated hardware-efficient draft models designed specifically for this job. In other words, the best assistant is often the one that is fast enough to make its guesses cheap, even if those guesses are a little less polished than a heavier alternative.
Acceptance rate is the quiet signal you want to watch next. If the target model keeps agreeing with the draft model, speculative decoding can accept more tokens per round and spend less time correcting mistakes; if the draft model drifts too far, the speed gains fade. That is why domain match matters so much. A draft model trained on prompts that resemble your real workload—whether that means code, chat, support tickets, or a specialized technical domain—will usually produce guesses that the target model is happier to verify, especially when the query distribution looks like the data the assistant learned from.
So the practical recipe is to test a few believable candidates, then compare them on your own prompts instead of relying on benchmark scores alone. Measure three things together: how fast the draft model runs, how often the target model accepts its tokens, and whether the end-to-end speculative decoding pipeline actually improves throughput. When those three numbers move in the same direction, you have likely found a strong pairing; when they fight each other, the draft model is probably too heavy or too far from the target’s distribution. Once that balance clicks, the next lever is how many tokens you let the draft model propose before the target model steps in.
Running Verification Passes
Building on this foundation, verification passes are where speculative decoding stops feeling like a guess and starts feeling like a careful check. The draft model has already sketched a few next tokens, and now the target model steps in to review that sketch in one parallel forward pass, rather than rereading the sentence token by token. That is the key move that keeps the large model in control while still letting several tokens move through at once, so you get speed without changing the output behavior. How do you keep that balance? You let the target model act like an editor reading a whole paragraph, not a word-at-a-time typist.
The mechanics are easier to picture if we treat the draft as a row of stepping stones. The target model checks them in order and looks for the first place where the draft and the verifier split, which the paper calls the bifurcation position. Everything before that point is accepted, and everything after it is discarded, so the system keeps only the prefix that still agrees with the larger model. Then the process repeats with the newly accepted tokens as the fresh starting point, which is why speculative decoding is an iterative draft-and-check loop rather than a one-shot shortcut.
This is where the intuition gets interesting, because verification is not always as strict as “match the top choice or lose.” In the earlier, vanilla form, the verifier accepted only tokens that matched the target model’s top-1 prediction, which guarantees identical greedy decoding but can throw away many good drafts. Spec-Verification relaxes that rule: instead of demanding exact top-1 agreement, it allows drafted tokens that fall within a top-k set and stay within a tolerable log-likelihood gap. In plain language, the verifier says, “This answer is close enough to what I would have chosen, so we can keep moving.”
That small change matters because acceptance rate is the hidden lever behind the speedup. When the verifier accepts more drafted tokens, each verification pass produces more useful output, which raises throughput and lowers the number of rounds needed to finish a response. The original paper reports that moderately loosening verification increases the mean accepted tokens and speed, but pushing it too far can hurt generation quality, with BLEU dropping once the rule becomes overly relaxed. So if you are wondering, “When should I loosen verification?” the answer is: only as far as your own quality checks will tolerate, because the best setting is the one that preserves the target model’s behavior while still letting the draft do real work.
In practice, this makes verification passes feel less like a gate and more like a negotiation. The draft model brings speed, the target model brings judgment, and the pass itself decides how much of the draft survives into the final answer. If the two models are well aligned, the verifier can keep accepting long prefixes and speculative decoding starts to feel remarkably smooth; if they drift apart, the verifier spends more time correcting than accelerating. That is why the next thing we usually tune is how many draft tokens to propose in the first place, because the length of the draft block and the strictness of the pass work together like two dials on the same machine.
Tuning Draft Length
Building on this foundation, the next dial to understand in speculative decoding is how many tokens the draft model should propose before the target model checks its work. That setting is called the draft length, and it can make the difference between a smooth speedup and a lot of wasted motion. If the block is too short, you do not give the draft model enough room to help. If it is too long, you ask the target model to clean up too many guesses at once, and the gains from faster inference can start to fade.
A helpful way to picture draft length is to imagine packing for a trip. One small bag means you keep walking back and forth to grab more items, which is slow. One giant suitcase sounds efficient, but it becomes awkward when half of what you packed does not fit the plan. Speculative decoding works the same way: the draft model should propose enough tokens to make each verification pass worthwhile, but not so many that the target model spends its time rejecting a long stretch of guesses. So when people ask, “How do you choose the right draft length?”, the real answer is that you are balancing overhead against the chance of rejection.
The key idea is that acceptance rate and draft length move together. As the draft block gets longer, the model has more chances to drift away from what the target model would have chosen, which usually lowers the number of tokens accepted per round. A shorter draft block often has a higher acceptance rate, because the draft model only has to stay aligned for a smaller stretch. But shorter blocks also mean more verification passes, and each pass has its own fixed cost. That is why the best setting is rarely the smallest or largest one; it is the point where accepted tokens per pass stay high enough to keep speculative decoding efficient.
This is where your workload starts to matter. If your prompts are predictable, your target model and draft model are closely matched, and the generation task is stable, you can often push draft length a little higher without losing much acceptance. If your prompts are messy, specialized, or highly creative, the draft can wander faster, and a shorter block may work better. In practice, code completion, customer support, and other structured tasks often tolerate longer draft lengths than open-ended brainstorming, because the next tokens are easier to guess from the local context. That same pattern is why many teams tune draft length separately for different request types instead of treating it like a universal constant.
There is also a hardware story hiding behind the numbers. Longer draft blocks reduce how often you call the target model, which can help throughput, but they also make each rejected segment more expensive. Shorter blocks create more frequent handoffs between the models, which may keep latency steadier for smaller requests, especially in interactive settings where the user notices every pause. The sweet spot depends on whether you care more about average throughput, tail latency, or a balanced mix of both. In other words, draft length is not only a model choice; it is also a product choice.
The safest way to tune it is to test a few candidate lengths on real prompts and watch three signals together: how many tokens the target model accepts, how much end-to-end latency changes, and whether output quality stays consistent. If you increase draft length and acceptance drops sharply, you have probably gone too far. If you shorten it and the system spends most of its time in verification passes, you may be leaving speed on the table. The most useful setting is the one where speculative decoding feels like a steady rhythm, not a tug-of-war, and that rhythm is what turns a clever algorithm into practical inference speed.
Measuring Speedup and Accuracy
Building on this foundation, the next question is the one that really matters in practice: how do you know speculative decoding is helping instead of merely moving work around? The safest answer is to measure the full pipeline, not the draft model alone. That means comparing end-to-end wall-clock latency and tokens per second against a normal autoregressive baseline, then checking whether the final answers still match the target model’s behavior. In the original speculative sampling paper, the authors reported a 2–2.5× decoding speedup while preserving sample quality, which is exactly the kind of comparison you want to make in your own tests.
Once you start measuring speedup, acceptance rate becomes the quiet number in the background that explains a lot of what you see. Acceptance rate tells you how many drafted tokens the target model keeps, and newer research continues to show that speedup is tightly bounded by that value. A draft model that gets many tokens accepted can turn one expensive verification pass into a long stretch of useful output, while a draft that misses often forces the target model to correct more often and reduces the benefit. So when you ask, “Why is speculative decoding faster on one workload but not another?”, acceptance rate is usually part of the answer.
Accuracy is the other half of the story, and here the goal is a little unusual: we do not want the speculative decoding path to invent its own behavior. Lossless speculative decoding preserves the target model’s distribution, so if you keep the verification rule exact, the output should behave like the baseline model apart from randomness and hardware numerics. That is why you should compare outputs on the same prompts, with the same decoding settings, and look for any drift in the final text, not just faster generation. If the answers change in a meaningful way, it usually means the verification rule was relaxed or the configuration has stepped away from the exact target distribution.
For many real tasks, accuracy needs a task-specific lens rather than a vague “looks good” judgment. If you are evaluating translation or summarization, metrics like BLEU and ROUGE give you a reference-based way to check whether quality stayed steady while speed improved. If you are working on coding or question answering, exact match, pass rates, or task success rates are often more useful because they reflect whether the answer is actually correct. A recent speculative decoding study reported speedups while preserving or improving BLEU and ROUGE, which is a good reminder that a faster system only counts as an improvement when the quality metrics stay healthy too.
So what should you record in a real experiment? We usually want the same prompt set, the same hardware, the same batch size, and the same sampling settings for both runs, then we log latency, throughput, acceptance rate, and the chosen quality metric together. That four-part picture is important because tokens per second can rise even when user-visible latency does not improve much, and a high acceptance rate can still be unhelpful if the draft model is too slow. In other words, speculative decoding only wins when the speedup is real at the system level and the accuracy stays aligned with the baseline you trust.
If you want a simple rule of thumb, use throughput to answer “Is it faster?”, use latency to answer “Does the user feel it?”, and use task quality to answer “Did we keep the model honest?”. That combination gives you a much clearer picture than any single number, and it prepares you for the next tuning choice: how aggressively you want to draft before the target model steps in again.
Common Implementation Pitfalls
Building on this foundation, the hardest part of speculative decoding is often not the idea itself but the plumbing around it. You may have a fast draft model and a careful target model, yet the system still feels disappointing because one small mismatch turns the whole pipeline into extra work. That is why common implementation pitfalls matter so much: they usually show up as lost speed, unstable quality, or results that look promising in a notebook but fade in a real serving stack.
One of the first traps is assuming the two models can be treated like interchangeable parts. They cannot. The draft model and target model need to agree on tokenizer behavior, special tokens, sampling settings, and stopping rules, or the acceptance step starts rejecting tokens for reasons that have nothing to do with model quality. Think of it like two musicians following the same song but reading different sheet music; even if each one plays well, the duet will sound off. In speculative decoding, that mismatch can quietly reduce the acceptance rate and erase the advantage you were hoping to create.
Another easy mistake is measuring the wrong thing. When people ask, “Why does speculative decoding feel faster in theory but not in production?”, the answer is often that they only looked at model time, not end-to-end serving time. The draft model may be cheap, but the target model still has to verify tokens, move data through memory, and coordinate with batching, scheduling, and network overhead. If you ignore those costs, you can mistake a local improvement for a real system gain, which is especially painful when the user experiences no visible latency reduction at all.
Memory management is another place where implementations stumble. The whole point of speculative decoding is to reuse work, but that reuse only helps if the key-value cache, which stores past attention states, is handled carefully. If cache updates are inefficient or the verifier forces repeated reallocations, you end up spending time shuffling memory instead of generating text. This is where the target model can become the bottleneck in disguise: the draft model may be quick, but the pipeline still slows down if the verification pass cannot move smoothly through the cached context.
There is also a tuning trap around draft length and acceptance rate. It is tempting to keep increasing the number of proposed tokens because longer drafts sound more efficient, but speculative decoding does not reward size for its own sake. If the draft model starts guessing too far ahead, the target model rejects more of the block, and the extra proposals become wasted effort. On the other hand, making the draft too short can leave speed on the table because you trigger verification too often. The sweet spot depends on your workload, and it usually appears only after testing real prompts rather than synthetic averages.
Quality regressions can be subtle, especially if you loosen verification too aggressively. A relaxed rule may improve throughput, but it can also shift the behavior of the final output in ways that are hard to notice at first. This is why teams should separate “looks fluent” from “preserves the target model’s behavior.” In practice, you want to know whether speculative decoding is still faithful to the target model, whether the acceptance rate is healthy, and whether the answers remain stable on the kinds of requests your users actually send. If those three signals do not move together, the implementation probably needs another pass.
The last pitfall is forgetting that hardware shapes the algorithm. A draft model that seems ideal on paper may run poorly on the actual accelerator, and a verification pass that looks cheap in code may become expensive because of bandwidth limits or poor kernel fusion. So how do you avoid that surprise? You profile the full path, compare a few realistic draft models, and test under the same batching and serving conditions you plan to use in production. That way, speculative decoding becomes a system optimization rather than a lab experiment, and you can see where the real bottleneck lives before it hides inside your target model stack.