NLP Fundamentals and Core Tasks
When you first meet NLP, it can feel like watching someone sort a stack of handwritten notes in a dim room. What is NLP doing when it reads a sentence? At its core, natural language processing is a branch of computer science and AI that uses machine learning to help computers understand and work with human language. That sounds big, but the first move is humble: turn messy text into pieces a model can handle, then teach it how those pieces relate to one another.
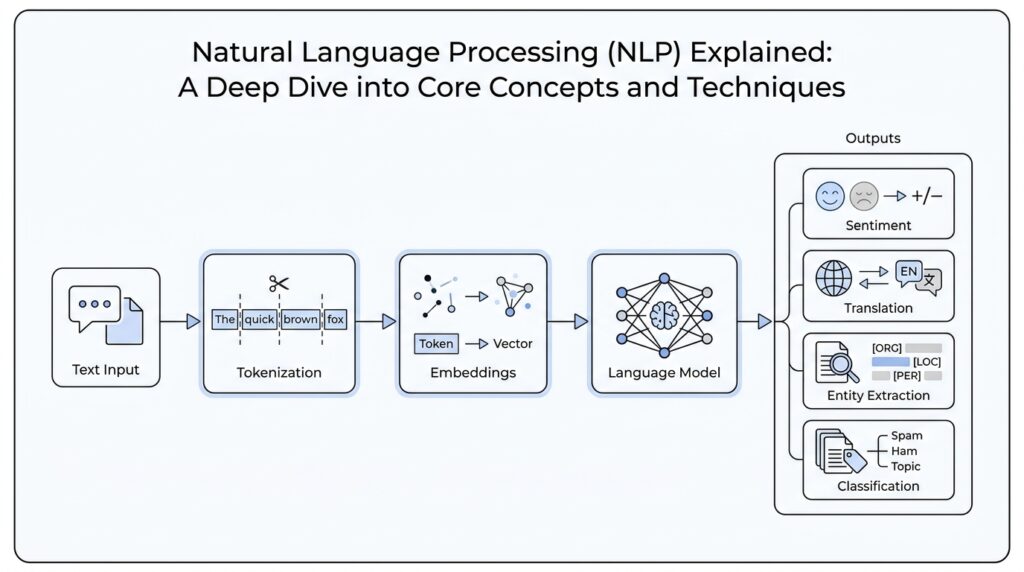
The first real step is tokenization, which means splitting raw text into meaningful segments called tokens. A token can be a word, a punctuation mark, or even a subword piece, depending on the system, and it becomes the basic unit the model can count, compare, and learn from. You can think of it like laying out puzzle pieces before we decide what picture they form. In an NLP pipeline, tokenization comes first, and later components receive that tokenized document instead of trying to make sense of an untouched block of text.
Once the text is broken apart, part-of-speech tagging steps in to assign each token a grammatical role, such as noun, verb, adjective, or adverb. This matters because language is slippery: the same word can behave differently depending on context, so the model needs clues about how each word is being used. Lemmatization adds another layer by reducing words to a base form, which helps connect reading, read, and reads as variations of the same idea. Dependency parsing then draws the grammar map, showing which word is the head and which words depend on it, like strings tied to a central knot.
From there, named entity recognition, or NER, looks for spans of text that refer to people, places, organizations, and similar proper names. If POS tagging is labeling the parts in a sentence, NER is circling the characters who deserve a name tag. This task powers information extraction, because once a system can spot names, dates, and places, it can start turning free-form text into structured facts that are easier to search and analyze. The tricky part is that NER must find the boundaries of each entity and decide what kind of thing it is, which is harder than tagging one word at a time.
Another major family of NLP tasks asks a simpler question with a lot riding on the answer: what bucket does this text belong in? Text classification assigns predefined labels to text, which can mean spam detection, topic sorting, intent detection, or sentiment analysis, where the system judges whether the tone is positive, negative, or neutral. Machine translation takes a different path and maps text across languages. If you are wondering, “How does NLP decide what a sentence is about?” this is usually where the answer lives: by combining tokenization, tagging, entity detection, and classification, we turn raw language into something searchable, sortable, and useful. That foundation is what lets us move from reading text to interpreting it.
Text Preprocessing and Cleaning
Before a model can do anything clever, we have to give it text that is tidy enough to trust. That is where text preprocessing and text cleaning come in: they turn raw language into something a computer can read without getting distracted by noise. If tokenization in the previous section felt like laying out the puzzle pieces, this stage is the moment we wipe the pieces clean, remove duplicates, and make sure the picture is not distorted by smudges.
This part of the NLP pipeline often starts with the little messes that people do not notice when they read naturally. A sentence might contain extra spaces, stray line breaks, emojis, HTML tags, punctuation that adds no meaning, or spelling variations that mean the same thing. In text cleaning, we decide which of those details matter and which ones only get in the way. The goal is not to make the text bland; the goal is to make it consistent enough that a model can focus on meaning instead of being distracted by accidental variation.
A common next step is normalization, which means putting different forms of the same idea into a shared shape. For example, we may lowercase words so “Apple” and “apple” are treated alike, or expand abbreviations so “can’t” becomes “cannot”. We may also remove stop words, which are very common words such as “the,” “is,” and “and” that sometimes add little value in a specific task. That can feel a bit strange at first, because those words are important in human conversation, but in some NLP tasks they are like background furniture: present, useful, and not always central to the scene.
What about words that appear in many different forms? Here, stemming and lemmatization enter the story. Stemming trims words down to a rough root, so “connected” and “connecting” might become something like “connect” or an even shorter stem, while lemmatization reduces a word to its dictionary form, or lemma, such as turning “better” into “good” in some systems. The difference matters because stemming is faster and rougher, while lemmatization is slower but more precise. Which one should you use for text preprocessing? That depends on whether your task values speed, accuracy, or a balance of both.
Noise removal is another quiet but important part of the process. If you are working with web data, social posts, or customer reviews, you may need to strip out URLs, mentions, repeated characters, boilerplate text, or broken formatting. If you leave that clutter in place, your model may learn odd patterns that have nothing to do with the real task. Think of it like trying to understand a conversation in a crowded room: the words are there, but the extra noise makes the signal harder to hear. Text cleaning helps the useful parts of the language stand out.
The tricky part is that preprocessing is never one-size-fits-all. If you are building sentiment analysis, punctuation, emojis, and even repeated exclamation marks may carry real emotional weight, so removing them too aggressively can erase clues. If you are building topic classification, on the other hand, you may care less about style and more about the words themselves. Good NLP work often means asking a practical question first: what does this model need to notice, and what can safely be ignored? Once we answer that, we can choose the right preprocessing steps instead of applying them blindly.
By the time this stage is done, the text is not perfect, but it is much more workable. We have reduced noise, standardized spelling and form, and prepared the document for the next layer of analysis. That preparation may feel invisible compared with the more exciting tasks that come later, yet it is one of the quiet foundations of natural language processing, because every model learns better when the text it sees is clean, consistent, and thoughtfully arranged.
Tokenization and Normalization
When we feed text into an NLP model, the first real question is not what the sentence means but what shape it should take so the machine can work with it. That is where tokenization and normalization step in together: tokenization breaks language into usable pieces, and normalization makes those pieces more consistent. If you have ever watched a messy desk become workable once the papers are sorted and labeled, you already understand the feeling of this stage in NLP.
Tokenization is the act of splitting text into tokens, which are the units a model reads. Those tokens are not always full words; they can also be punctuation marks, characters, or subwords, which are smaller word pieces used by many modern NLP systems. That flexibility matters because language does not always arrive in neat little word-shaped boxes. A phrase like “unhappiness” might stay whole in one system and become smaller pieces in another, depending on what the model needs to learn.
So why not always split by spaces and call it a day? Because human language is messier than that, and tokenization has to deal with contractions, hyphenated words, names, emojis, and languages that do not separate words with spaces in the same way English does. Word tokenization works well in many simple cases, but subword tokenization often gives NLP models a better balance between detail and generalization. It lets the system recognize familiar chunks, even when it meets a brand-new word for the first time.
Normalization comes next, and it acts like a translator between different surface forms that mean the same thing or almost the same thing. In text normalization, we may lowercase words, expand contractions, standardize punctuation, or convert different spellings into a shared form. We may also normalize Unicode, which is a standard for representing text characters in computers, so that visually similar characters are treated consistently. Without that step, two strings that look identical to us can behave like strangers to a model.
This is where the practical side of NLP starts to feel like judgment rather than routine. If your task is search or topic detection, normalization can help by reducing noise and making matches easier to find. If your task depends on tone or style, though, aggressive normalization can erase clues you actually wanted to keep. A lowercase question mark, an emoji, or a repeated exclamation mark may seem small, but in some settings they carry emotional weight, and tokenization in NLP needs to respect that.
The same careful thinking applies when we decide how much to normalize words themselves. Some pipelines use stemming, which trims words to a rough root, while others use lemmatization, which reduces a word to its dictionary form. Both aim to group related forms together, but they do it with different levels of precision. That is why there is no single perfect recipe for text normalization; the right choice depends on whether you want speed, simplicity, or a more exact understanding of language.
If you are asking, “How do tokenization and normalization help NLP models understand text?” the answer is that they make language predictable enough to learn from. Tokenization gives the model units to count and compare, while normalization makes those units more consistent across spelling, format, and writing style. Together, they turn raw text into something cleaner, more stable, and much easier for later NLP steps to interpret. Once that foundation is in place, the model is ready to move from reading scattered symbols to recognizing patterns that actually mean something.
Stemming and Lemmatization
Now that we have cleaned and normalized text, we come to one of the most practical choices in NLP: stemming and lemmatization. Both techniques try to group related word forms so the model does not treat reading, reads, and read as completely unrelated pieces of language. The difference is in how they get there. Stemming takes a rough, rule-based shortcut, while lemmatization aims for the dictionary form of a word by using vocabulary and morphological analysis, which is the study of how words change shape.
Stemming feels a little like trimming a hedge with quick snips until the shape looks close enough. A stemmer chops off prefixes or suffixes with heuristic rules, and that speed is exactly why people use it in search and text mining pipelines. But the shortcut can be blunt: the famous Porter stemmer can reduce words like operate, operating, operates, operation, and operational to oper, which helps with grouping but can also blur meaning. In other words, stemming often improves recall, which means finding more possible matches, but it can lower precision, which means getting fewer exact matches.
Lemmatization moves more carefully, like asking a librarian to file each word under its proper label. A lemmatizer tries to return the lemma, the dictionary form of a word, and it often relies on part-of-speech tags, which are labels such as noun, verb, or adjective that tell the system how a word is being used in the sentence. That matters because the same surface form can point in different directions: saw might become see when it is a verb, but stay saw when it is a noun. SpaCy’s lemmatizer, for example, can use rules based on part-of-speech tags or lookup tables, and rule-based lemmatization depends on those tags being available first.
Which one should you choose when you build a text classifier or search system? The answer depends on what you want the model to notice. If your goal is speed and broad matching, stemming can be a strong, lightweight choice because it needs less linguistic knowledge than lemmatization. If your goal is cleaner meaning and fewer strange word forms, lemmatization usually gives you a better result, especially when the exact word shape matters. NLTK’s WordNet lemmatizer, for instance, returns the shortest lemma it finds in WordNet and leaves a word unchanged if it cannot find a match, which shows how lemmatization leans on vocabulary coverage instead of brute-force trimming.
You will also notice that stemming and lemmatization are not interchangeable in every language or task. English examples are easy to picture, but other languages may have richer morphology, meaning words can change more dramatically depending on tense, number, gender, or case. That is why lemmatization often depends on language-specific resources, while stemming relies more on reusable rules. In practice, we usually choose the gentler tool when meaning matters, and the faster tool when rough grouping is enough. If we keep that tradeoff in mind, the next step in NLP becomes easier to understand: once words are reduced to stable forms, we can count them, compare them, and feed them into models that learn patterns from the cleaned-up language.
Syntax, POS, and Parsing
After we have cleaned and standardized text, the next question is wonderfully ordinary and surprisingly important: how do the words fit together? This is where syntax in NLP enters the story, along with part-of-speech tagging and parsing. If earlier steps gave us tidy words on a table, these steps help us build the table itself, showing which pieces belong together and which word is doing what work in the sentence.
Part-of-speech tagging, often shortened to POS tagging, gives each token a grammatical job, such as noun, verb, adjective, or adverb. Think of it like handing out name tags at a group project: one word is the action, another is the thing being acted on, and another is modifying the description. That may sound simple, but English keeps changing roles on us, so a word like book can be a noun or a verb depending on context. POS tagging gives the model the first real hint about how to read the sentence instead of treating every word as if it played the same part.
Once those roles are labeled, syntax starts to matter. Syntax is the set of rules that governs how words combine into phrases and sentences, and it is what lets us tell the difference between a sentence that feels natural and one that feels off. When you ask, “How does NLP know which word is doing the action?” the answer usually begins here. The model is not reading language like a person does; it is looking for patterns in how tagged words tend to arrange themselves, and that arrangement becomes the skeleton of meaning.
Parsing is the step that turns those labels into structure. A parser is a tool that analyzes a sentence and shows how the words relate to one another, almost like drawing a subway map where the stations are words and the tracks are grammatical links. In dependency parsing, the parser identifies a head word, which is the central word that others depend on, and then connects each dependent word to that head. In the sentence “The striped cat chased the small mouse,” for example, chased is the head, cat is the subject, and mouse is the object, while striped and small describe the nouns they sit beside.
That structure is useful because language often hides its meaning in the relationships, not just in the individual words. A parser helps the model see that “cat chased mouse” is not the same as “mouse chased cat,” even though the same words appear in both sentences. It also helps with attachment problems, which happen when a word could connect to more than one other word. In a phrase like “old men and women,” syntax and parsing help decide whether old describes both groups or only the men, and that kind of ambiguity is exactly where NLP has to work hardest.
There is another major style called constituency parsing, which groups words into larger chunks such as noun phrases and verb phrases. If dependency parsing is about who depends on whom, constituency parsing is about how words form nested building blocks, like stacking smaller boxes inside larger ones. Both approaches try to expose the grammar inside the sentence, but they answer slightly different questions. Dependency parsing is often easier to use for extraction and downstream machine learning tasks, while constituency parsing can be helpful when we want a richer picture of phrase structure.
All of this becomes even more important in real applications because syntax in NLP often acts like a quiet guide rail. Search systems, translation models, question-answering tools, and information extraction pipelines all benefit when they can tell who did what to whom, and which words belong together as a single phrase. A sentence can look perfectly fluent on the surface and still be structurally tricky underneath, so parsing gives the model a way to look beyond the line of words and into the grammar beneath them. In practice, part-of-speech tagging and parsing do not replace meaning, but they make meaning easier to reach, which is why they remain such steady companions in natural language processing.
Word Embeddings and Representations
By the time a model has cleaned and tokenized text, each word still needs a numeric shape it can carry around. That is where word embeddings come in: they turn words into dense vectors, which are compact lists of numbers that place similar words near one another in vector space. Instead of treating language as a pile of isolated labels, word embeddings give NLP a way to measure resemblance, so words that behave alike can live closer together and share what the model learns.
The idea feels less mysterious when we watch how these vectors are learned. Word2vec introduced continuous word representations trained from very large text collections, and the resulting vectors captured a range of syntactic and semantic relationships. GloVe took a different path, building vectors from global co-occurrence statistics in the corpus, so words that appear in similar neighborhoods end up with related representations. If you have ever searched for “how do word embeddings work in NLP?”, this is the core answer: the model learns from context, not from a dictionary definition handed to it in advance.
What makes this useful is the way embeddings let language feel organized instead of random. A model can start to notice that related words live in similar regions of the space, which means knowledge about one word can help with another. That is the quiet power of word representation: it lets the machine generalize from experience instead of memorizing each word as a totally separate event. GloVe even designs its vector differences so that relationships between words carry meaning, which is why these spaces often support analogy-like patterns.
Not all word embeddings stop at whole words, though. Some models, like fastText, break a word into character n-grams, which are short subword pieces, and build the final word vector from those pieces. That matters for rare words, misspellings, and words the model never saw during training, because the system can still assemble a useful representation from familiar fragments. In practice, this makes subword embeddings a bit like recognizing a person’s face even when one feature is hidden: the parts still give us enough clues to make a good guess.
Then the story gets more interesting, because not every word keeps the same meaning in every sentence. Contextual embeddings solve that problem by making a word’s representation depend on the surrounding text. ELMo learned deep contextualized word representations from a bidirectional language model, and BERT went further by pretraining deep bidirectional representations that condition on both left and right context. That means the same word can land in different places in vector space depending on how it is used, which is exactly what we want when language shifts under our feet.
This distinction matters because classic word embeddings and contextual embeddings serve different kinds of work. Static embeddings are lighter and often easier to plug into older pipelines, while contextual embeddings are stronger when meaning depends heavily on surrounding words. BERT’s authors showed that the model could be fine-tuned with just one extra output layer, and ELMo’s authors noted that their representations could be added to existing models with strong gains across several NLP tasks. So when we ask which representation to use, we are really choosing between simplicity, speed, and context sensitivity.
Once you see words as vectors, the rest of NLP starts to feel more connected. A model can compare, cluster, retrieve, and transform these representations, which is why embeddings sit so close to the heart of modern language systems. From here, we can move from individual word meaning toward the bigger patterns that emerge when those vectors interact inside sentences and documents.
Named Entity Recognition and Classification
When a sentence reaches named entity recognition and classification, we are no longer asking only where the words begin and end. We are asking which stretches of text point to real-world things, and what kind of things they are. So how does named entity recognition and classification actually work when you hand it a sentence? In practice, the system looks for spans of tokens and assigns labels such as PERSON, ORGANIZATION, LOCATION, DATE, or MONEY, turning a piece of language into a set of readable facts. That is why NER is so useful for information extraction: it helps us move from free text to structured meaning.
The first part of the job is spotting the entity span, which means finding the full stretch of text that belongs together. If you read “Stanford University,” you do not want the model to tag only “Stanford” and forget the rest; the entity should travel as one unit. Stanford’s NER documentation describes this as labeling sequences of words, and Stanza’s documentation says the module recognizes mention spans for a particular entity type. That span-first idea is the heart of named entity recognition: find the boundaries, then decide what the thing is.
Once the span is found, classification gives it a category. This is the moment where the model chooses between labels like PERSON, ORGANIZATION, and LOCATION, and in some systems it also handles MONEY, NUMBER, ORDINAL, PERCENT, DATE, TIME, DURATION, and SET. That may sound like a simple labeling exercise, but it carries a lot of meaning, because a single span can shift roles depending on context. “Apple” can be a company, a fruit, or part of a product name, and the classifier has to read the surrounding words before it commits.
This is where the story gets interesting, because named entity recognition is not only about spotting famous names. Many real systems use machine learning sequence models, and some pipelines also mix in rule-based components for things like dates and times. That combination matters because language is full of patterns that are partly regular and partly slippery. A machine can learn that “March 14, 2026” is a date, but it may still need rules to normalize or interpret that date correctly in context. In other words, NER classification is both pattern recognition and careful judgment.
The quality of the labels depends on the domain, too. A model trained for news stories may do well on people, companies, and cities, but it may miss the special vocabulary of medicine, law, or finance. Stanford’s documentation notes that the recognized entity set is language-dependent and often more limited outside English, which is a good reminder that NER is not a universal stamp. In one setting, the important labels might be PERSON and ORGANIZATION; in another, the system may need to recognize gene names, drug names, or legal references instead.
What makes named entity recognition and classification feel so powerful is that it creates a bridge between language and database thinking. Once the model identifies the span and assigns the label, we can count mentions, build search indexes, link names across documents, or pull facts into a knowledge graph. That is the reason NER shows up in so many pipelines: it helps us answer practical questions such as who did what, where it happened, and when it happened. It is a small piece of the NLP pipeline, but it often becomes the hinge that lets the rest of the system open.
Even with strong models, the task still asks for care from us. We need to think about boundaries, label choices, and the kind of text we are processing, because a good classifier in one setting can stumble in another. If you are wondering why NER sometimes feels easier to demo than to deploy, that is the reason: the labels may look tidy, but the language underneath them is anything but. Once we keep that in mind, we can start to see why named entity recognition and classification sit so close to the center of practical NLP.